Here, I am continuing my blog on Machine Learning with one more additional set of advice.
In general, the course Advanced Machine Learning specialization - Natural Language Processing is by far the best one in the whole specialization. Very nice lectures, explanations, and guides in practical assignments.
However, during doing the last project - making a chatbot for Telegram - I encountered some issues with AWS/Docker setup while doing as explained by the instructors.
Note that most of the things I have written here can be found in the course forum, but I want to share it at one place :)
Installing on AWS
Instead of classical sudo-follow-up command for installation from terminal
apt-get
you need to use :
yum
and this you can find on AWS guide for Docker installation.
Docker python3 run killed
Even though I had only 112 thousand embedded words, 1GB memory on AWS machine did not show to be enough for my chatbot to load. Practically this happened:
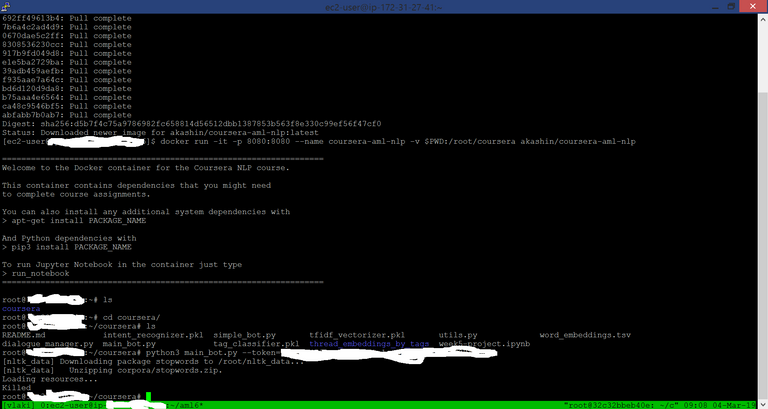
The solution I found that works for me is swapping. Most of the practical commands can be found on this link, while fallocate line should be changed with dd line from here.
Essentially all you need to run is:
sudo dd if=/dev/zero of=/swapfile count=4096 bs=1MiB
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
You can also make swap permanent and tweak its parameters as it is explained in the main swap link.
Note: while choosing memory amount, I did not manage to have bs=1G, with count=1. Instead, to add 1GB you need to type bs=1M with count=1024
AWS - more memory!!!
I tried to swap with 2GB, but it was not enough. This was maximum possible, as AWS had 8GB of storage.
So I had to increase AWS storage. This was done while making Instance as followed from AWS instructions and then before Step 5, I would go "Next: ...." until I do not end up on the storage page. Here I set 30GB (which is maximum for Free Tier!!!) instead of 8GB. Than 15000-20000 counts with bs=1M did the job B-)
ASCII error
When running, there was an error (do not mind the numbers):
UnicodeEncodeError: 'ascii' codec can't encode character '\xe9' in position 215
The solution can be found in the course forum, and you just need to run following line
export PYTHONIOENCODING=UTF-8
before running main_bot.py.
I hope somebody will find this helpful and please let me know if you think that something else should be here.
If you are new to SteemIT and decide to join based on this article - let me know using any media you prefer.