Hmmm should I put this post in my AI series?
Well, this is a technique that is used in a practice for machine learning, so if a machine can learn something, we can say, I guess, that it’s intelligent. But this is also a big area by itself and also very interesting to me, so I’ll maybe write on this topic a little bit more in the future. I’ll continue to write in my next part about search strategies, but I just couldn’t be patient and I wanted so bad to share this with you, so – let’s say that this is some kind of an intermezzo. The real AI intermezzo!
What is this neural network thing? Is it a real network? Why is it neural?
Nikola, I’m already confused...
Imagine that some guys got too literally meaning of making an artificial intelligence – so, when you try to make literally an intelligence, isn’t it the best way to try to make something that is the best representation of an intelligence? That’s right – a brain.

Use it! Author Affen Ajlfe, Public domain 1.0
Neural network is a mathematical model that is inspired with brain structure, more precise – with biological neurons.
Just like neuron has its cell body, dendrites and synapses, on the same way an artificial neuron has inputs, outputs and processing element. Take a look at the pictures:
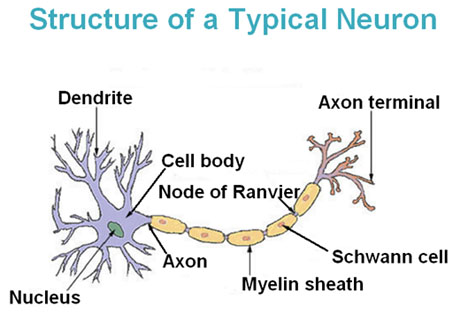
Biological neuron Source, Public domain
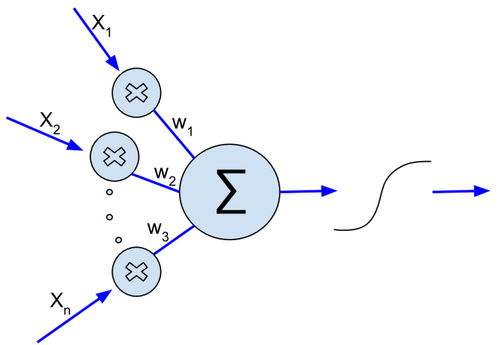
Artificial neuron SourceCC 4.0
Those networks consists of a big number of a well-connected processing elements which are working in a parallel and have ability to learn, memorize and generalize things by training with large data sets.
As you maybe know, that some people love to act tough when they are in a big group and when they are alone they’re actually one big nothing, analog to that - none of these neurons by itself in an artificial neural network have some knowledge, but when they are connected and when they work together they have amazingly big computing power.
How can they actually learn things?
To explain that, I have to mention one important part of these networks and those are weights.
Weights are coefficients which are representing how much is one connection between neurons important. Basically, training neural network is actually setting those weights and there are many ways to do that, so we have many different algorithms.
The idea about weights started in 1940s with Hebb’s learning law (Donald Olding Hebb, a Canadian neuropsychologist) also known as "cells that fire together wire together" which says that if one neuron A is causing activity of other neuron B, then their connection is getting stronger, otherwise - it’s weakening. So, the connection will get stronger or weaker by setting its weight as a bigger or lower coefficient. This is type of an unsupervised learning, because there isn’t any signal which works as a feedback and helps network to learn by “saying” what is good result and what is bad - somehow, neural network is discovering it by itself.
Beside from unsupervised learning – there are two more categories:
- Supervised learning
- Reinforcement learning
In supervised approach, in our training data set we also have correct results so we know what our network is supposed to give us as an output. We use that output and compare it to the real values and basically calculate the error on our data set and use that error as a feedback signal which will go back in the neural network and adjust those weights a little bit better.
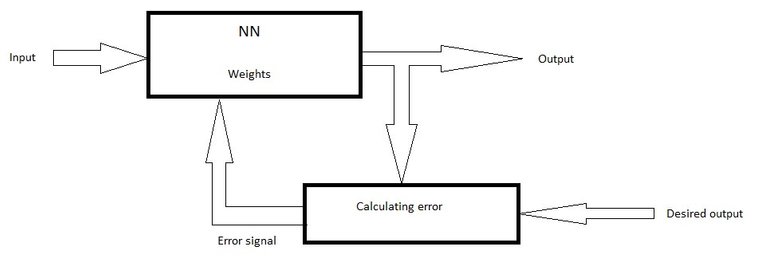
Supervised learning, self-made picture
Reinforcement learning is similar to the supervised learning and some people are considering it as a part of that approach because network also has the feedback signal, but now that signal doesn’t work as an “instructor”, it’s more like a critic. If system is working fine, this signal will support, otherwise it will “punish” it.
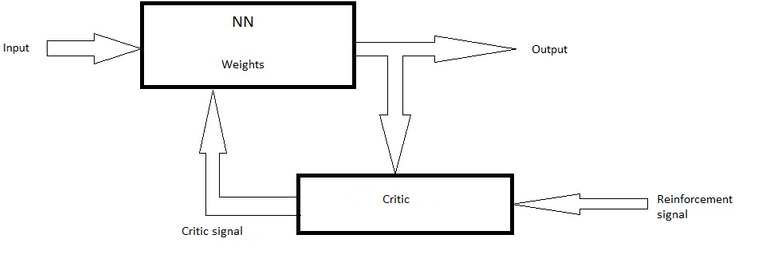
Reinforcement learning, self-made picture
Omg this is so exciting, it sounds like a Sci-Fi
Well, first thing and very, very first thing is to know that these days everyone loves to chit-chat about the AI and neural networks, without actually knowing anything about it, so sorry if I’m ruining your fantasies, but as an eternal pessimist I can say that neural networks are not a magic wand, unfortunately.
They work usually as classifiers.
Let me explain it a little bit better. Imagine that you are trying to teach a little kid what is a car. So, you print some pictures of Volkswagen , BMW, Audi, a little bit of Fiat and Yugo (If you don’t want your kid to become a gold digger) and so on. And you show those pictures to your kid, without saying anything, just show. That kid will notice some characteristics and generalize it and somehow intuitively conclude what is actually a car. Later when you show it some picture of a car that it didn’t see before, for example a picture of Ferrari, that kid should say Oh, I know! It’s a car! Then you give your kid something sweet.
If you show it a picture of an elephant, based on previous experience, it shouldn’t know that it is an elephant, it should just say – this is not a car!
That’s the same way how neural networks work (further I’ll call it NN, it’s much easier for writing).
As the input in NN, we have features of some subject. The feature is something that is good characteristic of your subject (for example your DNA or finger print are certainly good characteristics of you). Those features are coded as numbers and they are going into NN, straight to the processing elements in neurons.
Those processing elements firstly calculate sum of its input and then do the mapping with its activation function in some real number. There are five types of activation functions:
- Step function
- Hard limiter (Signum function)
- Ramp
- Unipolar sigmoidal function
- Bipolar sigmoidal function
The number that this function give as an output will be the output of that neuron and later will be multiplied with some weight and like that will go to the another neuron as an input.
Where we have to watch out?
Do you remember some kids in your class that could solve some mathematical problems but if they come up to a similar problem with something that is changed a little bit or with different numbers, they just couldn’t get it and solve it?
We can’t say that it’s an intelligent behavior, so we don’t want that our network “think” like that, so we need to avoid something that is called overfitting. You can see an example of an overfitting below.
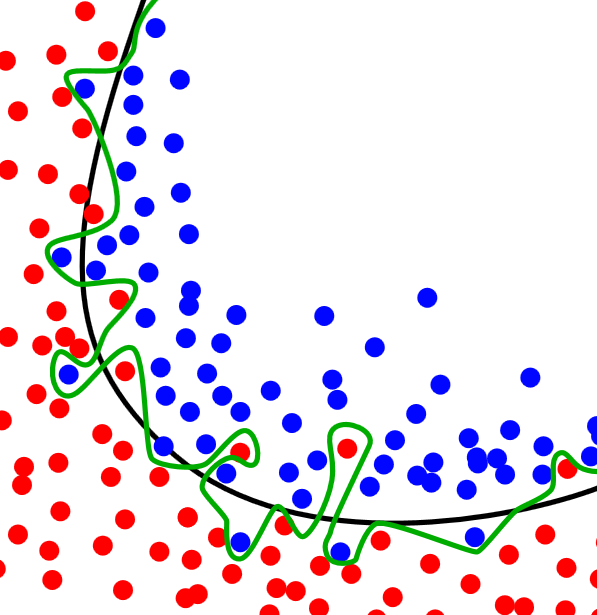
Author Chabacano, CC1.0
It means that NN is specialized only for a concrete data set and it works perfectly, but can’t generalize its knowledge, so when it comes to another data set, the results are terrible.
As we can see on the picture, the green classifier overfits the data with the zero error and it would probably work catastrophically with new data.
To avoid that, we divide our data set not just only on training and test set, but on training, test and cross-validation set, usually in a ratio 60:20:20.
So, we save our test set for testing when our network is trained, but while training NN we are also computing an error on a training set and as the time goes by that error is getting smaller and smaller because NN is ”getting used to” that training set, so from time to time we insert some data from cross-validation set which is unknown to our NN and look at our error. When error starts rising we can say that overfitting is starting, so we stop training our NN.
One more thing that I have to say, before I show you some of my work is that NN can consist of only one layer of neurons (those are perceptron networks, good for cases when you have linearly separable classes) and also can have more layers. NN with more layers is feedforward NN and it has input layer, output layer and all other layers which are between them are called hidden layers. You can see on the picture how it looks like:
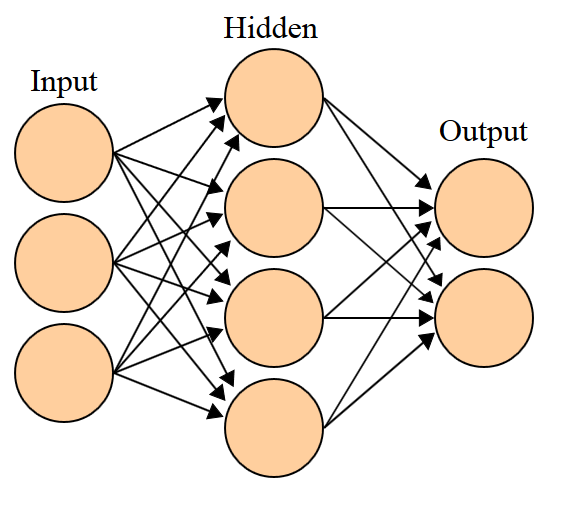
Feedforward network with one hidden layer Author Cburnett, CC3.0
The interesting thing is that there is no rule about the number of hidden layers and neurons in a single layer, the trick is to work experimentally and to determine what is the best possible structure of NN for your problem.
Yeah, you’re just acting smart... why don’t you show us some real things, how does it work in practice?
I guess it’s time to call heavy artillery – Matlab.
To do my simulation, I decided to download some data sets from the internet and to try to build and train NN to work with that data.
I found interesting data set on this link.
This set is created about twenty years ago by Vladislav Rajkovic for the schooling system in Ljubljana, in Slovenia.
Here is the original info about this data set:
Nursery Database was derived from a hierarchical decision model originally developed to rank applications for nursery schools. It was used during several years in 1980's when there was excessive enrollment to these schools in Ljubljana, Slovenia, and the rejected applications frequently needed an objective explanation. The final decision depended on three subproblems: occupation of parents and child's nursery, family structure and financial standing, and social and health picture of the family. The model was developed within expert system shell for decision making DEX (M. Bohanec, V. Rajkovic: Expert system for decision making. Sistemica 1(1), pp. 145-157, 1990.).
Attribute (feature) Values:
parents : usual, pretentious, great_pret
has_nurs : proper, less_proper, improper, critical, very_crit
form : complete, completed, incomplete, foster
children : 1, 2, 3, more
housing : convenient, less_conv, critical
finance : convenient, inconv
social : non-prob, slightly_prob, problematic
health : recommended, priority, not_recom
Class Distribution (number of instances per class):
| Class | N | N[%] |
|---|---|---|
| not_recom | 4320 | 33.333% |
| recommend | 2 | 0.015% |
| very_recom | 328 | 2.531% |
| priority | 4266 | 32.917% |
| spec_prior | 4044 | 31.204% |
Downloaded data set is in .csv file, but somehow I’m not so skillful with that kind of files so I transformed it into .txt file and saved it like that.
This is how it looks like – in every row there is eight features and a class where our candidate belongs. In the first row, you can see the names of those features and as you can see, the ninth column is the class.
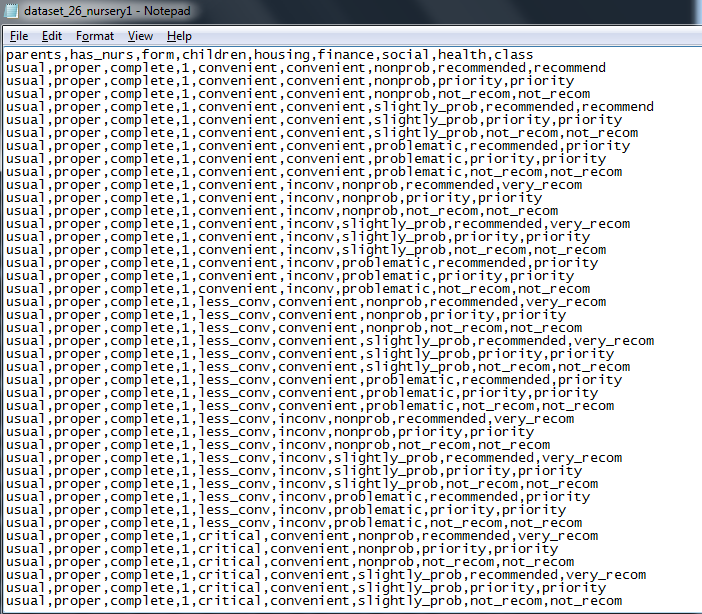
Self-made picture
First, we have to load our data in the Matlab with those commands:

Self-made picture
Now, when the table with the data is loaded, I divided this table into two sub-tables – one with only features (inputs to our NN) and one with only classes (outputs for NN), to work easier.
Because you can’t enter some word as an input into NN, it doesn’t have much sense, I coded all of those inputs and outputs and represented them as a numbers. It was a little bit boring part of the job, because basically we have to write nine ‘for loops’ for that.

And so on, with nine loops Self-made picture
The most important here is to save these coded data as a matrix, not as a table as it was previously, because you can input some data in NN only in a form of a matrix!
Now when we have two matrices as input and output, we have to divide that on training and test set.
You probably remember what I said about cross-validation set and overfitting, but there is one good news – Matlab has built-in functions to help us avoid overfitting and it will automatically do the cross-vallidation during the training!
I decided to separate my data in 80:20 ratio and, to have more precise results, I didn’t choose for example first 80% and the last 20%. Instead, I wrote this small part of the program to choose them randomly until we get 80:20 ratio:

Self-made picture
Now it’s time to create and train network and as you can see, I was experimenting with this part to find the best possible structure of my NN for this problem. Somehow, I was the mostly satisfied with the network with two hidden layers with the 15 neurons in each.

Self-made picture
Here is one picture to show you how this training looks like:

Self-made picture
If we take look at the performance graph of this training, we can see that training stopped exactly when error started rising on the cross-validation set, like I said it before:
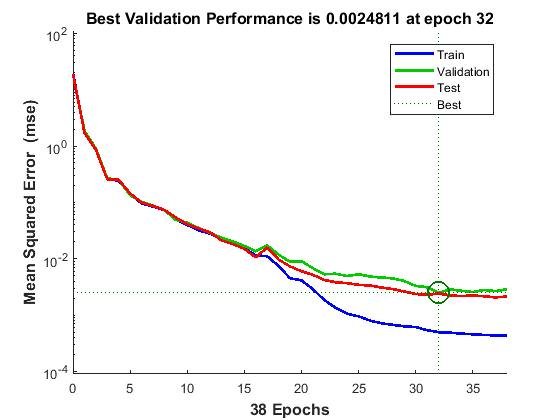
Self-made picture
Now it’s finally time to do the testing on our test set.

Self-made picture
As an output, we have a vector of numbers and to classify them, I put some thresholds. I’ll explain it a little bit better.
The numbers that we got are not rounded, so for example I put first thresholds as 27.5 and 28.5 and ask is my number greater than 27.5 and less than 28.5. If it is, I say ok – I declare this number as 28.
This number 28 is actually a code for a class named ‘’not_recom” as we coded it earlier, which in reality stands for a student that is not recommended.
If it’s not between 27.5 and 28.5, we put more thresholds for other classes and continue the same procedure.
I really hope that I was clear about this.
Basically, our classification is finished and now we should take a look at something called confusion matrix to see how much it was successful.

Self-made picture
The confusion matrix will show you how much elements from the first class are recognized as a first class, as a second class, as a third and so on.
That’s why it’s called ‘confusion’ – it shows us how much is confused our system.
It shows us that for each class, so basically the ideal confusion matrix will be with numbers only on diagonal.
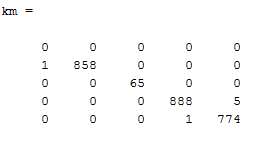
Self-made picture
As we can see my system works surprisingly very, very well!
It classified wrongly only 7 students out of 2592 in total!
Because I have that habit of losing time daily, basically on nothing, I decided to do also extra calculation to see the percentage of my classes and to compare it to the percantage that I stated above as a data info.
This is what I got:

Self-made picture
If we compare it to this:
| Class | N | N[%] |
|---|---|---|
| not_recom | 4320 | 33.333% |
| recommend | 2 | 0.015% |
| very_recom | 328 | 2.531% |
| priority | 4266 | 32.917% |
| spec_prior | 4044 | 31.204% |
I could say that I'm satisfied and this is an indeed small, tiny and powerful neural network.
If you had enough curiosity and patience to read the whole article, I just have to say - thank you. I hope that I succeeded to bring these things and how it works closer and clearer to you.
I hope that you enjoyed and understood a little bit of this.
Risking to spoil my mentor, I have to thank @scienceangel for her help and mentoring during writing this article!
Sources:
Fundamentals of artificial neural networks, Mohamad H. Hassoun
Artificial Intelligence: A Modern Approach, Peter Norvig and Stuart Russell
ANN Wiki
https://www.digitaltrends.com/cool-tech/what-is-an-artificial-neural-network/
Hm. I tend to disagree with that statement:
This is somewhat misleading. As far as I remember, Hebb did not write that two neurons need to fire together to increase the efficiency of their connection.
To understand this clearly, it is important to be aware of the concepts of causality and consistency.
He stated, that neuron A needs to repeatedly (consistency) take part in firing (causality) neuron B. That is an important difference to make. The presynaptic neuron needs to fire repeatedly just before the postsynaptic one, to have a potentiating effect on the synapse in the end. This mechanism is strongly connected to spike-timing-dependent plasticity (STDP) - a neurological process, which is responsible for adjusting the strength of neuron connections. This is based on the relative timing of a neuron’s output and input potentials (spikes).
Hi @egotheist,
Thank you for your insight, you are right - it is a little bit misleading, but if it's taken too literally.
Hebb really never said "cells that fire together wire together", neither I wrote that it's stated in his law - it's just part of the "slang" in academic circles because it's easy to remember.
The fact is that those two neurons can't fire exactly at the same time, so the presynaptic neuron have to fire a bit earlier (because of the causality, like you said) and that consistency is a big factor for weights setting.
I just wanted to adapt it to an average steemit reader.Me personally, never thought about it in that way, that neurons could fire literally at the same time, so that's probably why I haven't seen it as an oversight.
Again, you got the point,
Regards:)
I see. Problem is, this kind of imprecise thinking leads to other mistakes. I have read this exact example already in books. Can't hurt to put it right when writing here.
Good article. Just one suggestion. When you are doing coding stuff it is better to give the source code and related data in websites like GitHub and link it in the article. So that it will be helpful to others too. 😃
I completely agree with you, it's just I never used GitHub before :(
But I certainly plan to learn using it, because I would love to start contributing to the @utopian-io community :)
Hi @nikolanikola!
Your post was upvoted by utopian.io in cooperation with steemstem - supporting knowledge, innovation and technological advancement on the Steem Blockchain.
Contribute to Open Source with utopian.io
Learn how to contribute on our website and join the new open source economy.
Want to chat? Join the Utopian Community on Discord https://discord.gg/h52nFrV
My father used to make me crazy while I was a kid, by me telling that he is going to sell our car and buy Subaru Rex! Puke! Bloody Subaru Rex! I hate it! :D
Anyway, Matlab...
Now I'm serious: do you have some experience with data that were already transformed before used as input for NN? I will need to solve something with hyperspectral images. I have two options, either to use raw data (matrices, 64k x 4k) and put them into NN to train the hell out of them. Or... Should it be better to reduce their dimensionality to 64k by 3 (not 3k, 3) and than put them as input? I don't like to do the analysis of the analysis of the analysis... Yet, reduction of dimensionality is in my veins :)
Well, I personally didn't have experience with such problem, but based on what you said, it looks like you have to reduce the number of the features without losing any important data - That looks to me as a problem for Karhuenen - Loeve expansion, you can check out this article on wiki https://en.wikipedia.org/wiki/Karhunen%E2%80%93Lo%C3%A8ve_theorem and google it further.
I hope that I was helpful :)
Karhunen–Loève theorem
In the theory of stochastic processes, the Karhunen–Loève theorem (named after Kari Karhunen and Michel Loève), also known as the Kosambi–Karhunen–Loève theorem is a representation of a stochastic process as an infinite linear combination of orthogonal functions, analogous to a Fourier series representation of a function on a bounded interval. The transformation is also known as Hotelling transform and eigenvector transform, and is closely related to principal component analysis (PCA) technique widely used in image processing and in data analysis in many fields.Stochastic processes given by infinite series of this form were first considered by Damodar Dharmananda Kosambi. There exist many such expansions of a stochastic process: if the process is indexed over [a, b], any orthonormal basis of L2([a, b]) yields an expansion thereof in that form. The importance of the Karhunen–Loève theorem is that it yields the best such basis in the sense that it minimizes the total mean squared error.
Yes, yes, there is a whole bunch of similar techniques, each one of them good for the extraction/ elimination of "noise" based on slightly different statistical parameters.
Thank you!
One technical tip:
.csv(comma separated values) and.txt(text) formats are the same data encoding. The difference is the file extensions can tell the operating system what types of programs should open the files by default. The matlab ecosystem has acsvreadfunction that should help you avoid having to write parsing code in the future.I hope this helps! Your article is a nice walkthrough. My only other recommendation is to add some high level comments in the code samples on the intent behind the code, but thats more personal taste as I skip to check these out first!
Thanks for the insight @carback1 :)
I had experience with only txt files so far, so it was naturally to me to first transform it in txt, but I'll keep your tips on my mind for the next time. :)
No worries, already too late for that 😎
I must say that this is one of the very rare occasions when I read the article from beginning to the end, and two things happen:
I don't get bored;
I understand everything perfectly, although I knew nothing about the topic prior reading.
Having that said, I think you did awesome work here, just keep it up!
As a person who knows nothing about this, I would have just one cliché question - in what way are neural networks implemented in our everyday lives, where can we find them?
Thank you very much, It really means to me when I see that I succeeded to spark interest in someone who is not actually from this profession :)
Well beside that we can use them as a classifier like I showed in this article with concrete example of its application, they may find use practically everywhere - for example in medicine to help us to determine the disease of a patient, in a business to find some correlation between the data etc.
There is one interesting use - they can be used to reconstruct 3D function, and that can be helpful for face recognition!
I plan to write about these things more in the future, so stay tuned :)
This post has been voted on by the steemstem curation team and voting trail.
There is more to SteemSTEM than just writing posts, check here for some more tips on being a community member. You can also join our discord here to get to know the rest of the community!
норм че
Wonderful post.
Thank you :)
Strong nueral power
Congratulations @nikolanikola! You have completed the following achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
SteemFest³ - SteemitBoard support the Travel Reimbursement Fund.