Hi friends. This time I have a toy python code for you guys to play around with. This is my first attempt at data analysis with steemit data. The code I have is actually from this reply. I have put it in a loop to run over through a list of steemit handles. The users were those got mentioned in steemSTEM distilled-36 article. These authors got both @curie and @steemstem votes. There was a total of 171 users. I am giving that list here.
Installation first
My machine is a Linux debian system. I assume that you know to install python. What I did was I downloaded python-3.6.5 from here. Extracted and installed it locally. I installed pip package too. (In case any of you want help regarding these, please reply to this article.) Then I installed steem-python as below:
python -m pip install -U git+git://github.com/Netherdrake/steem-python
Python Code
from steem import Steem
s = Steem()
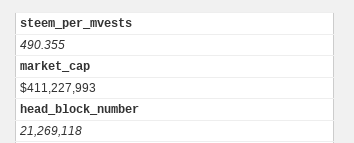
sp_per_mv = 490.355
#490.355 April 4 (3.47 PM Indian time GMT+5.30)
users = []#steemit usernames
SP = []#steem power
i=0#counter
#users.txt from steemSTEM distilled-36
for line in open('/home/devanandt/Documents/STEEMIT/STEEM-PYTHON/Test_projects/distribution_of_n_users/users.txt'):
users.append(line.strip('\n')) #appending list with usernames deleting newlines
# the computation of SP
for user in users:
account = user
print(user)
#code-snippet from @kryzsec
vs = float(str(s.get_account(account)['vesting_shares']).replace(' VESTS', ''))
rvs = float(str(s.get_account(account)['received_vesting_shares']).replace(' VESTS', ''))
dvs = float(str(s.get_account(account)['delegated_vesting_shares']).replace(' VESTS', ''))
SP.append((vs+rvs-dvs)*sp_per_mv/1000000)
#the data writing part
thefile = open('SP.dat', 'w')
for item in SP:
i=i+1
thefile.write("%d %s\n" %(i,item))
thefile.close()
This is not an efficient code I am sure. If there are good python coders, you can reply the better versions of it. This is very slow too. Ultimately my dream is to get all steemit user handles and check the wealth distribution and see it the results math with this paper by Dr. Venkat et al. The paper says in a free market economy the wealth distribution tends towards log-normal distribution. They use Statistical mechanics and Game theory concepts to deduce it.
A better Code [from @kryzsec ; See his comment for this article]
from steem import Steem
s = Steem()
sp_per_mv = 490.355
#490.355 April 4 (3.47 PM Indian time GMT+5.30)
users = []#steemit usernames
SP = []#steem power
i=0#counter
#users.txt from steemSTEM distilled-36
for line in open('./users.txt'):
users.append(line.strip('\n')) #appending list with usernames deleting newlines
for user in users:
usr_dict=s.get_account(user)
print(user)
#code-snippet from @kryzsec
vs = float(str(usr_dict['vesting_shares']).replace(' VESTS', ''))
rvs = float(str(usr_dict['received_vesting_shares']).replace(' VESTS', ''))
dvs = float(str(usr_dict['delegated_vesting_shares']).replace(' VESTS', ''))
SP.append((vs+rvs-dvs)*sp_per_mv/1000000)
thefile = open('SP.dat', 'w')
for item in SP:
i=i+1
thefile.write("%d %s\n" %(i,item))
thefile.close()
Where do you get STEEM per MV (steem per mega vests)?
This quantity is needed to calculate SP of the user. I got it from steemd.com page. Image below:
Gnuplot code (in semilog style for X axis)
##
reset
set terminal epslatex color standalone#or png
#set style fill transparent solid 0.5
set key autotitle columnhead
set o "SP.tex"
Min = 0 # where binning starts
Max = 40000 # where binning ends
n = 1000 # the number of bins
binwidth = (Max-Min)/n # binwidth; evaluates to 1.0
bin(x) = binwidth*(floor((x-Min)/binwidth)+0.5) + Min
set xlabel "STEEM POWER"
set ylabel "DISTRIBUTION" offset 2,0
set logscale x
plot "./SP.dat" using (bin($2)):(1.0) smooth freq with lines lt -1 lc 1 title "";
unset output
set output # finish the current output file
system('latex SP.tex && dvips SP.dvi && ps2pdf SP.ps')
system('mv SP.ps SP.eps')
unset terminal
reset
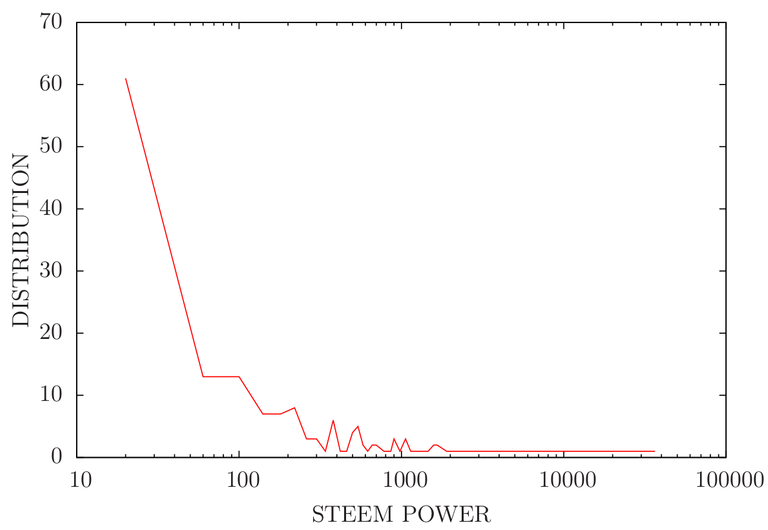
Semilog Plot
Raw plot (with no semilog command)
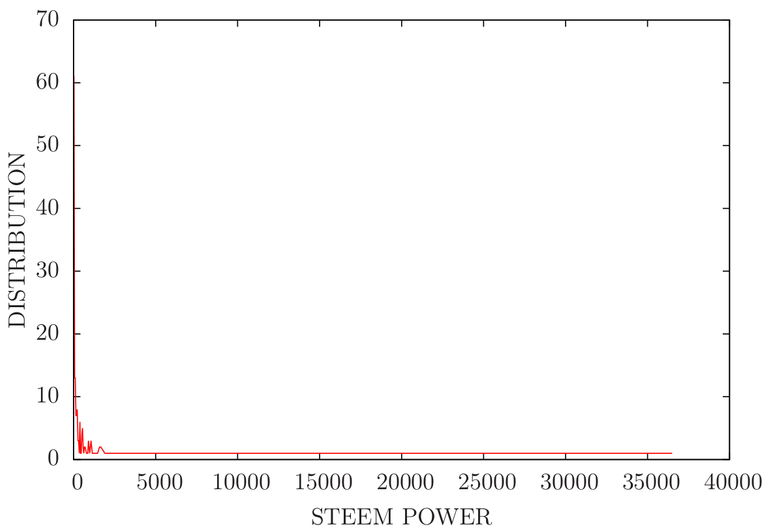
Barely seeing anything right! :P
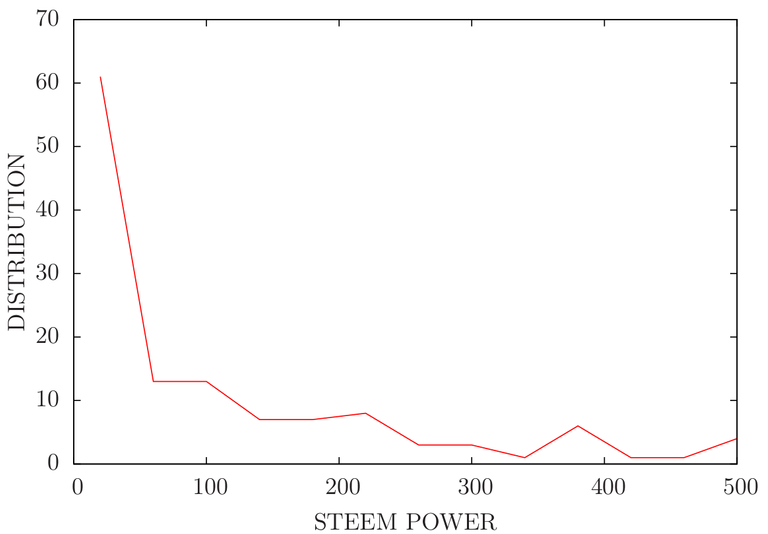
Zooming into Raw plot (0 to 500 SP)
Conclusion
The only conclusion as I understand is most of the wealth at least in terms of SP is in few hands. Let us initiate a discussion about the science of economics too.
Acknowledgement
I thank @kryzsec for this detailed reply with a coding example. He pointed me to a very nice article written by @themarkymark for installing the library steem-python (which works with python3 only).
Reference
- Venkatasubramanian, Venkat, Yu Luo, and Jay Sethuraman. "How much inequality in income is fair? A microeconomic game theoretic perspective." Physica A: Statistical Mechanics and its Applications 435 (2015): 120-138.
- Learn Python 3 the Hard Way: A Very Simple Introduction to the Terrifyingly by Zed A Shaw
Software used
- Python 3.6.5 (with steem-python library for data pulling)
- Gnuplot (for plotting)
A call to users who may be interested in these kinds of data analysis
Anyone interested in similar kind of data analysis? Let me know.
@tibra : Maybe you want to see this article :P
@bharathchand : What do you think?
If you like this post, please upvote and resteem it.
Below are my recent posts, you may find it interesting:
- Linear Transformation Contest: Sample Code in Matlab
- Linear Transformations: A 20 SBD coding contest announcement! [UPDATED with sample code!]
- A google trends analysis on "COW": India versus Pakistan
- Eigen Values and Eigen Vectors: Visually Explained!
Join #steemSTEM
Join the active science community #steemSTEM at discord: https://discord.gg/BZXkmWw
And to steemSTEM beginners:
You can ask for help in our discord page. There are people ready to help you there.

All images without image sources are my creations :)
Follow me @dexterdev
____ _______ ______ _________ ____ ______
/ _ / __\ \//__ __/ __/ __/ _ / __/ \ |\
| | \| \ \ / / \ | \ | \/| | \| \ | | //
| |_/| /_ / \ | | | /_| | |_/| /_| \//
\____\____/__/\\ \_/ \____\_/\_\____\____\__/
First of all, thank you for this!
What I'd also like to see is how much of the rewards were used to power up.
And those who received steemstem votes, what percent of their VP went back to steemstem tag.
But of course all of this requires quite a lot of work.
Actually, the thing is I am a beginner. But we can slowly start looking to these kinds of analysis. steem-python is a nice tool!
The story of the pareto distribution! -> wiki
Yes this seems to be a power-law distribution. I think the over-all distribution of steemit will also have power-law distribution. But then the paper I cited predicts something else. May be there is something hidden here, still which we don't understand.