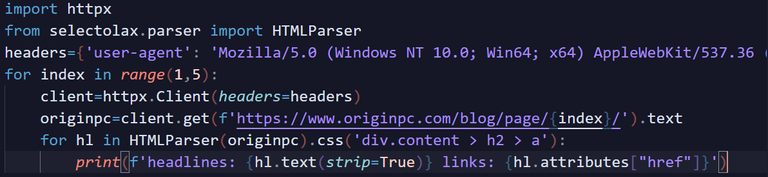
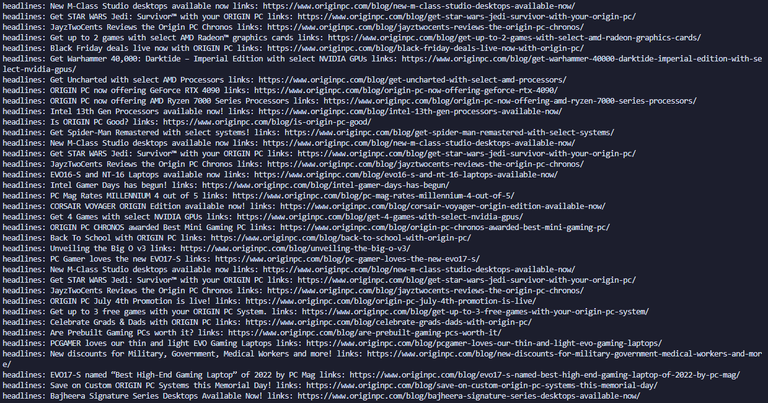
import httpx
from selectolax.parser import HTMLParser
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75'}
for index in range(1,5):
client=httpx.Client(headers=headers)
originpc=client.get(f'https://www.originpc.com/blog/page/{index}/').text
for hl in HTMLParser(originpc).css('div.content > h2 > a'):
print(f'headlines: {hl.text(strip=True)} links: {hl.attributes["href"]}')