
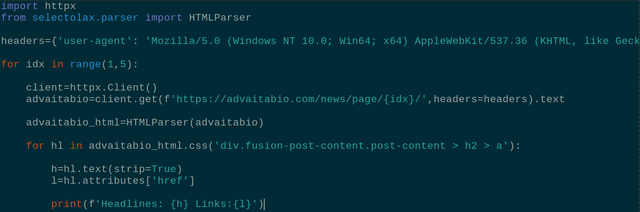
import httpx
from selectolax.parser import HTMLParser
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75'}
for idx in range(1,5):
client=httpx.Client()
advaitabio=client.get(f'https://advaitabio.com/news/page/{idx}/',headers=headers).text
advaitabio_html=HTMLParser(advaitabio)
for hl in advaitabio_html.css('div.fusion-post-content.post-content > h2 > a'):
h=hl.text(strip=True)
l=hl.attributes['href']
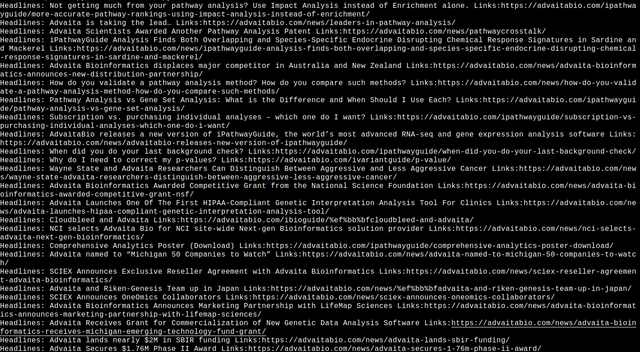
print(f'Headlines: {h} Links:{l}')
Congratulations @pynomiems! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out our last posts:
Support the HiveBuzz project. Vote for our proposal!