If you count words regardless of the language
As it stands, that's how this function works.., my challenge is to figure out if it contains multiple versions, using MT's or otherwise. Keeps my brain ticking over nicely!
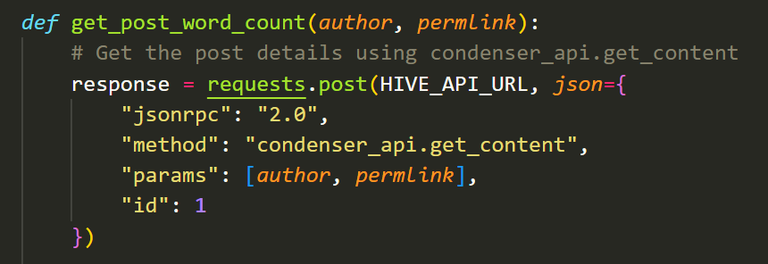
If you count words regardless of the language
As it stands, that's how this function works.., my challenge is to figure out if it contains multiple versions, using MT's or otherwise. Keeps my brain ticking over nicely!
Well, you can check for specific characters that English lacks - Ñ and vocals with accents for Spanish; umlauts (ä, ö, ü or ß) for German, and likely most Germanic languages; and so on.
If there are English articles AND at least certain number of non-English characters, then the text is likely in two or more laguages.
A more complex option woul counting these English articles, I guess there would be a certain ratio for them in a common English text. Say 0,8 articles per sentence in average or so. If the ratio gets below certain threshold, the text likely contains other language(s), or perhaps is not a fluent natural text, but say a table or something similar.
This looks promising, Python has a vast array of libraries..I will give it a trial run. There's more than one that does the same thing... useful!
It should be easy with such libraries, since you're about to detect languages in entire posts and not in separated sentences :)
It's nice to see a challenge coupled to a solution that improves a thing.