If you want to understand Steemit on a deeper level, you need to dig into the data on the blockchain. Having spent a couple of days familiarising myself with the API and getting a node up and running, my conclusions are: that data is pretty complex, and there is a lot of it, but, once you get started, there is a lot of cool analysis to be done. This is my contribution to helping others get up and running with extracting and analysing data from the Steem blockchain using Python.
I'll walk through the process of building a dataset by running through the blockchain, loading it into Python Pandas, cleaning it and then running some basic exploratory analysis on #introduceyourself posts
This post builds off the excellent developer's guide to Steem's blockchain by @furion. I couldn't have got to this point without that guide, or without the Python tools written by @xeroc. Huge thanks to them.
And a disclaimer: there may be better, or more efficient, ways to do what I'm demonstrating here. If anyone more familiar with the Steem API wants to chip in, I'd be happy to hear from them.
Prerequisites
I'm assuming three things:
- That you have a local node up and running using the command:
.\ steemd --rpc-endpoint
Since we are going to be hitting the blockchain hard, you need to be doing this locally and not melting someone else's server. In the end, I found the easiest way to do this was compiling Steem on a remote Ubuntu box rather than trying to work out networking in Docker. YMMV.
- That you have the Anaconda Python 3 distribution installed. This has the whole Python data science stack included and is by far the easiest way to get up and running with this sort of analysis. The only non-standard package I've used here is seaborn for plotting. You can install this with:
conda install seaborn
- That you have installed the python-steem library
Creating a dataset from the blockchain
Our goal is to to create a dataset of all #introduceyourself posts for analysis. This is a relatively simple task in itself, but the principles hold for much more complicated ideas. How do we do it?
- We loop through every transaction through the blockchain.
- If that transaction contains a Blog and that blog has #introduceyourself as its first tag, then we record its author and permanent URL in a list.
- We then use the API to get the content of each relevant post using the author and URL and save this as a list of JSON responses.
- We then turn this list into a Pandas dataframe and analyse it using standard data science techniques.
Note that this workflow can be repeated for more complex ideas, including ones that can't be achieved through the API alone.
To start, we import our libraries and connect to the node.
from steemapi.steemnoderpc import SteemNodeRPC
import json
from json import JSONDecodeError
rpc = SteemNodeRPC("ws://127.0.0.1:8090", "", "")
As described in the post by @furion, each post is contained in an operation array. The relevant parts of an operation look like this:
'operations': [ [ 'comment',
{ 'author': 'anauthor',
'body': 'This is a post',
'title': 'My Intro',
'json_metadata': '{"tags": ['introduceyourself']}',
To find an #introduceyourself post, we need three conditions to hold:
- The first item in the array is 'comment'.
We then need to examine the dictionary in the second item of the array.
- The value of 'title' needs to be something other than the empty string,
''(which would indicate a reply). - Finally, we need to find
introduceyourselfin the 'tags' of the 'json_metadata' item. The json_metadata item is stored as a string, so to get at it programatically, we can decode it using the json library.
The code below loops through each block in the blockchain, and each transaction in each block, making these checks. If an introduceyourself post is found, it adds the author and permanent URL to a list of tuples. To keep things simple, I made the decision to only add the first post that an author made in the category to the dataset.
Note that I've done a lot of error catching because this is a long process, and if you are doing something more complex than I'm doing here, then debugging weird data errors will be a big part of creating your dataset successfully.
props = rpc.get_dynamic_global_properties()
current_block = 0
last_confirmed_block = props['last_irreversible_block_num']
authors = set()
posts = []
# debugging records
bad_json, weird_json, no_tags, tags_empty = [], [], [], []
while current_block < last_confirmed_block:
current_block += 1
block = rpc.get_block(current_block)
for t in block['transactions']:
for o in t['operations']:
if o[0] == 'comment' and o[1]['title'] != '' and o[1]['json_metadata'] != '':
try:
metadata = json.loads(o[1]['json_metadata'])
except JSONDecodeError as e:
bad_json.append(current_block)
continue
try:
tags = metadata['tags']
except KeyError as e:
no_tags.append(current_block)
continue
except TypeError as e:
weird_json.append(current_block)
continue
try:
first_tag = tags[0]
except IndexError as e:
tags_empty.append(current_block)
continue
if 'introduceyourself' == tags[0]:
author = o[1]['author']
permalink = o[1]['permlink']
if author not in authors:
authors.add(author)
posts.append((author, permalink))
Getting the content of the posts is now really easy. We just make a call to the API, which requires two parameters: the post author and the permanent URL.
introduce_posts = []
for post in posts:
introduce_posts.append(rpc.get_content(post[0], post[1]))
Each item in this list is the json response describing an introduceyourself post. It contains payout details, active votes, the content of the post and lots more. In truncated form, an entry looks like:
{'abs_rshares': 0,
'active': '2016-06-11T08:27:54',
'active_votes': [],
'allow_curation_rewards': True,
'allow_replies': True,
'allow_votes': True,
...
}
Pandas has a function, from_records that translates a list of dictionaries straight into a dataframe, and we can use this to finish off the process of creating our dataset.
records = pd.DataFrame.from_records(introduce_posts)
The full records table has 40 columns and over 3000 rows, but this is a sample of important columns, and the first few rows.
| author | created | total_payout_value | body |
|---|---|---|---|
| pal | 2016-06-02T15:01:24 | 413.870 SBD | Hey all! I |
| glib | 2016-06-02T16:45:15 | 271.440 SBD | Im a small |
| cryptogee | 2016-06-02T08:31:45 | 48.904 SBD | This artic |
| theshell | 2016-06-03T12:18:33 | 1281.812 SBD | ***A day i |
| cryptoctopus | 2016-06-03T13:48:42 | 983.936 SBD | # Hi! My n |
Now that we have a dataset, we can start to get to work.
Cleaning up the data
Type changes
Data analysis requires a lot of prep and cleaning. Working with the Steem blockchain is no exception.
First, we'll turn the date strings into date columns into datetime data types, so that plotting works nicely.
records.created = pd.to_datetime(
records.created, infer_datetime_format=True)
records.last_payout = pd.to_datetime(
records.last_payout, infer_datetime_format=True)
records.cashout_time = pd.to_datetime(
records.cashout_time, infer_datetime_format=True)
We'd also like the payout values to be a numeric type. Right now these are strings with the format "100.000 SBD", so we can simply cut off the first word and convert to a float.
records.total_payout_value = records.total_payout_value.apply(
lambda x: float(x.partition(' ')[0]))
Analysing payouts
We can now do some basic analysis on payouts.
Using the describe, median and mode functions on the total_payout_value series. We get the following:
| Mean payout | Median payout | Mode | SD |
|---|---|---|---|
| 129.9 SBD | 0.196 SBD | 0.0 SBD | 722.0 |
The mean is really pushed up by some of the 'jackpot' posts.
What makes a post valuable?
Having the content of the posts in the dataframe means that we can start to analyse the factors that make a successful post. As one simple example, we can count the number of words in the post and categorise each post as either 'short', 'medium' or 'long' and add these as new columns in the dataframe.
records['words_in_post'] = records.body.apply(
lambda x: len(x.split()))
def post_length_type(p):
if p <= 104:
return "Short"
if p >= 469:
return "Long"
else:
return "Medium"
records['long_post'] = records.words_in_post.apply(lambda x: post_length_type(x))
Now whenever we do an analysis, we can split on this new variable and see if it makes a difference. Here, for example, we can plot the number of votes against the payout using Seaborn and see the different results for each length category.
%matplotlib inline
ax = sns.lmplot(x="net_votes", y="total_payout_value",
hue="long_post",
col = "long_post", col_order=["Short", "Medium", "Long"],
palette="Set2",
data=records[(records.total_payout_value < 3000) ])
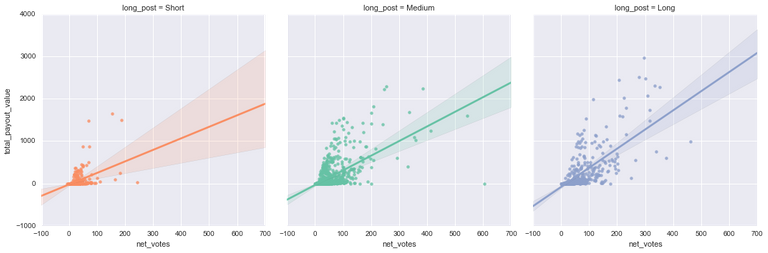
As this plot shows, longer posts are more likely to have higher payouts and more votes, although there are still plenty of low value posts too. This could show two things: either it pays to put effort into your introduceyourself post, or the people who are more likely to be valued by the community just have a lot more to say about themselves (the long CV effect).
Trends over time
Finally, let's see how payouts have changed over time.
To do this, we need to remove some bad data rows and set the index to be the 'created' column.
no_payout_timestamp = pd.Timestamp('1970-01-01T00:00:00')
records = records[records.created != no_payout_timestamp]
Now we can calculate the daily mean payout on introduceyourself payouts and, to reduce the wild swings, also calculate a five-day rolling mean. Since we have the post length variable, let's split on that to see if it shows us anything.
(records.groupby('long_post')
.total_payout_value.resample('D').mean()
.rolling(window = 5).mean()
.unstack().transpose().plot())
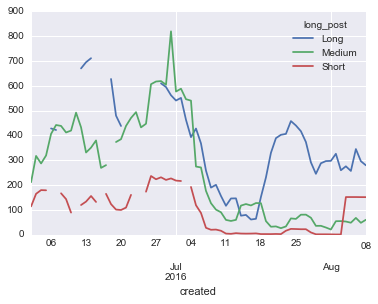
This plot shows us that long posts have consistently been doing better than short or medium ones. Also of note is the big drop off in mean payouts in early July and the tick up in values of long posts from mid-July. I suspect the latter is a function of the 'celebrity' effect, of people with large followings making big announcement posts and getting large rewards as a result.
Conclusion
There is a lot more that could be done with this dataset - this is more of a proof of concept that I hope will help other people who want to go on and figure out what is making the Steem network tick.
If you enjoyed this post, you may also like my series on Steemit and graph theory - I think my next task is going to be scraping the blockchain for data to populate a network database like Neo4J. If anyone is interested in collaborating, let me know.
Never heard about seaborn. It looks great!
Yeah, Seaborn is awesome - it's nice to finally get plots as elegant as ggplot in Python. The only drawback is that - at least the last time I tried - it doesn't handle date-time data properly, so if you want to work with financial or social time series, you need to drop back to the default Pandas wrapper around matplotlib, which doesn't match and has uglier default themes.
Great work mate!
Most excellent post! @sunjata Follow for you and upvote!
Full $TEEM AHEAD!
@streetstyle
very informative, the details are very well represented. way to go @sunjata
THIS! I NEEDED THIS!
Can you drop a line via google hangouts to faddat@gmail.com?
Thanks for your post!
Hey, I'm going to be away for a few days, but you can catch me on the #dev channel of steemit.chat - for sure when I'm back next week, and I'll be checking in in-between times too.
Thanks! Bookmarking. Cashtags: $b.datascience $b.programming $b.data $b.analysis $b.dev
Interesting. Thanks for doing all this work!
I never received the data from blockchain. Make instructions for the beginner (with pictures ). Where to begin? Thank you.
If I can help you , I'm ready
It's hard to say what your particular problem is, but if you have steemd running, then the websocket still won't connect successfully until the blockchain has synced - this can take a long time, particularly on a home network connection. I did it on a remote box mainly to avoid this bottleneck. There are some good guides linked to in the furion post I linked to in my post.
can it be done without locally creating a node?
In theory, there's nothing to stop you putting in the address of a remote node when you do:
rpc = SteemNodeRPC("ws://remotenode:8090", "", "")For smaller tasks, like pulling a few posts, this would be fine. For something like this, which loops through every block, I think you would run into trouble.
There's a new project, called steem.ws that is running a load-balanced cluster of nodes - you could ask them what kind of usage they consider polite and limit your calls to the API accordingly.
thanks!
great job. keep going
As an analytics student, the first thing I searched for on her was analytics and data science. Very impressed with how in depth this post is as well as informative, even though you call it "Simple" lol
Thanks a lot for this post! Very nice entry point to interact with the chain in Python :-)