Background
During a programming session in mid-October while listening to several "alternative media" videos concerning facts regarding this election cycle, my thoughts shifted from the embedded networked storage & computing library I was working on to the subject of censorship by social media sites. In particular Twitter's banning of those like Milo Yiannopoulos, real-time suppression of trending topics via hashtag manipulations, and Facebook's alliance with the German government with regards to the narrative on migrants from the Middle East and Northern Africa. I also had my own run-in with Facebook censoring a post in which I tried to include the flag of the German Empire.
"We [anarchists & libertarians] need systems which aren't censored", I thought, "A system with neither centralized control and storage nor ability to censor records."
As too often happens, my thinking drifted to the technicalities of such a system, in particular how to incentivize the maintenance of data and provision of services. It didn't take long for my mind to shift gears from the assembly code I was writing to forming a theoretical framework for a system which would share many things in common with my embedded networking library. The following is a simplified description of what I believe is needed.
Overview
While my introduction discussed the social media issues which sparked my thoughts, this post won't cover those aspects of the system. Instead we will examine the underlying mechanisms which could be used to make numerous applications a reality. It is imperative that the system's inner workings be open-source to ensure full transparency and to leverage the resources of interested parties in keeping the system updated and as secure as possible.
The system's core consists of hosts which may be configured to store data and/or perform computations on data. Host operators may configure almost every aspect of their systems including items such as maximum packet size, cost of storage per packet as well as per time interval, cost of providing autonomous operations, cost of providing enhanced reliability or response times, maximum processing loads, and cost per processing unit.
While hosts perform data storage and processing, clients consist of users requesting host services. Like hosts, clients may configure many aspects of their systems and what they are willing to pay per service offered.
The nature of the system allows anyone with a computer to download the application package and become a host or client. Applications for this system are limited only by one's imagination; however, the system is unfit for real-time computing and better suited to near real-time applications.
A blockchain-based system as I describe must perform the following functions:
- Data storage and retrieval
- Discovery
- Computing (data processing)
- Smart contracts
- Cryptocurrency
- Autonomous operations
- Account rating system
- User interface
- Network Interface
By now some may be thinking to themselves, "Why not just use Ethereum's contract system?"
As we will examine, the requirements for this system differ than those for Ethereum, especially in the area of what is stored within the blockchain. In its most simple application, the client portion of the system should be able to run at usable speeds on embedded devices and IoT platforms, even something as simple as an 8051 core.
To begin, a client is always a client but never host; a host may take on the role of client in addition to host depending on the type of transaction the host is engaged in. For example, a host becomes a client when negotiating for and transferring data or service requests to other hosts even though the data belongs to other clients.
Data Storage & Retrieval

Data segments (or files if you prefer that term) are broken into small packets, the size of which may be set by each client and host. Each packet has an associated cryptographic hash, and each data segment also has a hash. Hashing ensures the integrity of each packet and segment may be checked; packets and segments showing integrity disparities may be removed (voided) from the system entirely with removal reflected in the blockchain. Rather than storing raw data in the blockchain, these hashes are stored while packets are routed to hosts whose packet acceptance size meets or exceeds that of the packets. Packets may also be encrypted on the client system prior to hashing and transmission if the user has configured the system to do so; it is advisable that this be the default operation along with the use of symmetric encryption. This ensures data privacy during transmission and storage.
Normal segments and packets are not meant to exist in perpetuity and thus contain time-to-live (TTL) tags specifying the lifetime of the segment or packet. Hosts may accept segments and packets with a TTL value of zero; these are assumed to be data which is expected to exist in perpetuity. To prevent hosts from being overwhelmed with junk segments and packets with a TTL of zero, it is recommended that hosts accept such data only from trusted clients with appropriate credentials.
Packets are identified by a 128-bit Universal Packet ID (UPID) which includes a packet's time of creation measured in hundreds of nanoseconds from the year 2000. UPIDs cannot contain any information which, if used alone or in conjunction with other information, may identify the system generating the packet. Bits 127 and 126 of the UPID are reserved for UPID extension and UPID voiding, leaving 126 bits for the UPID itself. In addition to a UPID, each packet includes a 256-bit Universal Segment ID (USID) generated in the same fashion as a UPID, with bits 255 and 254 providing a USID extension and voiding mechanism.
To provide hosts with a method of identifying clients who own data stored on hosts, a simple response system is implemented. Upon receipt and acceptance of client data, the host generates a 128-bit UUID and transmits it along with the USID/UPID combination back to the client as a confirmation of data acceptance.
Computing
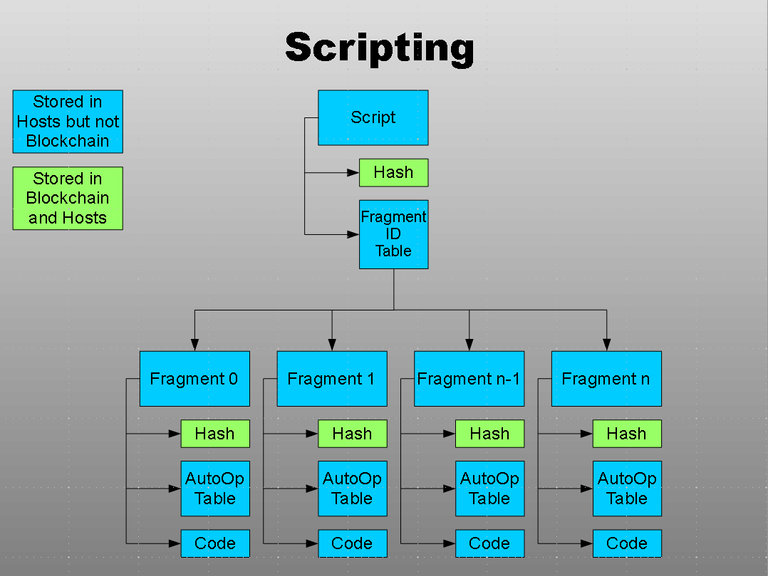
Separate from the data storage and retrieval mechanism is the computing platform.
Scripts are the method clients who wish to perform computations utilize the system, and are composed of individual fragments. A fragment consists of one or more algorithms which will run on a single host. Fragments permit a single script to be executed across multiple hosts. Like data segments and packets, scripts and fragments are not stored within the blockchain but their hashes and IDs are. The scripting language is algorithm-based and possible "exploits" like filling hosts with scripts containing nothing but endless loops are discouraged via the pay-per-compute model.
The computational capability of hosts is rated using Processing Units (PU), a platform-independent standard measurement of computing power available to perform a set of operations. Temporal and memory complexities are the two metrics by which resource consumption may be measured on digital systems, the former serving as the basis for further computations of resource usage such as electrical power.
The number of PUs available on a single host is calculated by performing standard algorithms on said host and rating each using these two metrics.
Smart Contracts

Smart contracts, referred to as Service Agreements, form the basis of the system's method to incentivize users to act as storage and/or processing nodes; while smart contracts currently exist, this system requires a very lightweight and simple implementation. The Service Agreement system consists of nothing more than triggers defining which conditions must be met for hosts to receive payment. There is no need for a wide range of triggers or methods to provide custom triggers. Numerous triggers are defined including the following examples:
- Packet size
- Packet retention time
- Autonomous operations
- Computing complexity
- Data recall
- Algorithm completion
As with segments, packets, scripts, and fragments, service agreements are identified within the system by IDs and hashes.
Cryptocurrency
This subject need not be covered in-depth due to the existence of numerous cryptocurrencies; however, it is important that the number of units which can exist is limited to avoid inflation. Bitcoin is a perfect example. Other than timestamps included in various IDs, account addresses are the only other information which could conceivably be used to identify a client or host.
The maintenance of the blockchain is the goal, and cryptocurrency provides one incentive for miners to perform such maintenance. The blockchain consists solely of service agreements, packet/segment IDs, script/fragment IDs, and their associated hashes as well as node ratings.

A three-phase escrow is also implemented within the blockchain. Phase I is the transfer of currency from the client's available account balance and into their escrow pool upon a host accepting a service agreement and providing an acknowledgement to the client. Phase II is the transfer of the escrow amount into the global escrow pool upon transfer of stored data or algorithm results. Finally Phase III transfers currency into the host account once the client has verified data integrity or the results of the algorithm. As currency moves from Phase I to Phase III it becomes more difficult for the client to recover it and easier for the host to claim it should dispute arise.
Autonomous Operations
The capability for hosts to perform various operations under specific conditions is integral to the effectiveness of the system. Detection of any of the following conditions, as well as others, on a host may trigger autonomous operations:
- Packet age
- Date and time
- Hash error
- Loss of communication with client
Upon the completion of an autonomous operation and verification by miners, the payout determined by the service agreement is transferred into the host's account.
Account Rating
Because accounts (blockchain "wallet" addresses) are required to utilize the system, they are used in the account rating system that assigns an integer value to each account. Account rating allows both automatic and manual rating of clients and hosts and is the feedback mechanism by which those using the system are able to asses the trustworthiness of anyone else in the system. Account ratings are kept in the blockchain and serve as a history of account trustworthiness. Automatic rating is one function performed by miners; segments and scripts are periodically sent to hosts, generally selected at random, and miners check the results against expected results. Automatic rating also occurs when a client flags a service agreements failure or detects a discrepancy in segments or script results and flags the transaction as invalid. In this case miners act as arbiters, determining whether the client or host is at fault and adjusting ratings accordingly. Rating also determines the amount which a client or host is impacted by negative adjustments as well as the impact their "vote" has when rating others.
User Interface
The specifics of the user interface are outside the scope of this post and largely outside the scope of the system as well; the system is primarily a VM and API. However, users should have the ability to specify almost every operational aspect of their client or host; cost parameters, service agreement acceptance parameters, algorithm black and whitelists, rating thresholds, memory constraints, and so on.
Network Interface
While the particulars of each network type are out of the scope of this post, end even the system itself, it is important that methods of accessing and utilizing a network be as secure and anonymous as possible. The Tor protocol is a good example. It is also important that the network is fully abstracted to average client and average host, yet permits advanced clients and hosts to tailor network features to the extent such modifications do not create security and anonymity issues.
Super interesting stuff!! :)
Thank you for reading.
I don't see anything here about encrypting the stored data. IMHO the hosts should never know what it is they are storing, and no host should hold an entire set of packets that comprise a package.
Data storage should also be redundant. If one host goes down that should not prevent a distributed site from working.
So when a client requests a web page, the client puts out a request for data based on a GUID. The various hosts send what packets they have, just like in a torrent system, and the client builds and then decrypts the package. Then, if more processing power is needed, they can build packets of computation that can be sent out to processing hosts who wil only have a subset of the problem being computed - maybe using some sort of zero knowledge proof-like system, so that no hosts actually know what is being done.
When I, as a site builder, set up a site I post the GUID to a blockchain with very little metadata. I then toss the site's data out to the winds where various hosts each store a few of the packets. I shouldn't even know who/where they are being stored.
Thank you for reading and taking the time to respond!
Client-side symmetric encryption was briefly mentioned as the recommended default. However, encryption is not required to use the system and in some instances may not be desired, such as a publicly-available web page stored in the system. Setting the encryption type is something users of clients and hosts are able to define as an option. Additionally, a client could be set to refuse to deal with hosts who accept data which hasn't been encrypted, and vice-versa.
To redundancy and anonymity, I often take things for granted even though I shouldn't; redundancy and anonymity are two reasons splitting segments and scripts into smaller blocks is done. Also, many features such as verification of computations depend on more than one host performing the identical operations on identical data. Any individual or group who wants to invest the time and resources to discover where packets are stored would be able to because of how the internet works, but the average client wouldn't know who or where data is being stored or processed.
Fragments are meant to be small in size, from 8 bytes to megabytes, with the range set by clients and hosts. An embedded client or host may only handle 256 bytes at a time while a desktop-based system could only deal in megabytes. This also opens the door for aggregator services to spring up which accept hundreds or thousands of minuscule transaction requests from embedded/IoT devices, assemble them into large fragments megabytes in size, and send them off to hosts for storage.
This system isn't meant to hide information from prying eyes, but to provide a lightweight blockchain-backed distributed processing and storage mechanism; essentially to prevent censorship but also useful for many other tasks.
If anything else sparks your interest, suggestions, or general comments please feel free to respond!