
This post documents a misadventure in optimizing a high performance database that I am working on. After making a small change I realized a 3x performance gain and the problem was with the hardware prefetcher making bad predictions. I searched the internet looking for anyone else who might have stumbled across similar performance degrading behaviors and couldn't find anything. So, for all of you performance nerds this post may reveal a new source of potential performance pitfalls that doesn't show up directly in your code!
I'll give you the moral of the story upfront. You pay not only for the memory that your program actually uses, but for any memory your CPU thinks you might use that you never actually use.
As a result I have a new idea for a generic c++ type that hides unlikely to be used pointers from the hardware pre-fetcher until you actually want to use them.
Case Study
I am building a copy-on-write (COW) adaptive radix trie where each node can have up to 256 children. When inserting into a shared trie, a new copy of each node from the leaf to the root must be made and 1 of the 256 children is changed while the reference counts on the other 255 children are incremented. When one of the versions of the trie is no longer needed, you must decrement the reference counts and if any count goes to zero then you must recurse to the child node.
My code was carefully designed to put all of the reference counts in a separate area of memory so that I wouldn't have to access the child nodes. Each node is on a different cacheline, so every child node access loads 64 bytes and loading all 256 children would move 16kb into the limited CPU cache. Furthermore, to save space my nodes store pointers to child-nodes in smaller "node ids" which can be used to lookup the pointer to the actual node.
The following is pseudo-code of what my code was doing. release_node releases the node_id reserved for the node and the id cannot be used after its reference count goes to 0, but the pointer to the node remains valid for the current call stack.
void release_node( node_id id ){
const node* node_ptr = get_node(id);
if ( release_node(id) )
release_children(node_ptr);
}
So I lookup the node pointer node_ptr but only use it if the reference id was actually released. However, that is not how the hardware prefetcher saw things. It saw a pointer materialize on the stack and decided to fetch the memory it pointed at, just in case. It is also possible that the branch predictor speculated a call to release_children() which promptly de-referenced the pointer causing a cache miss and forcing the data to be loaded.
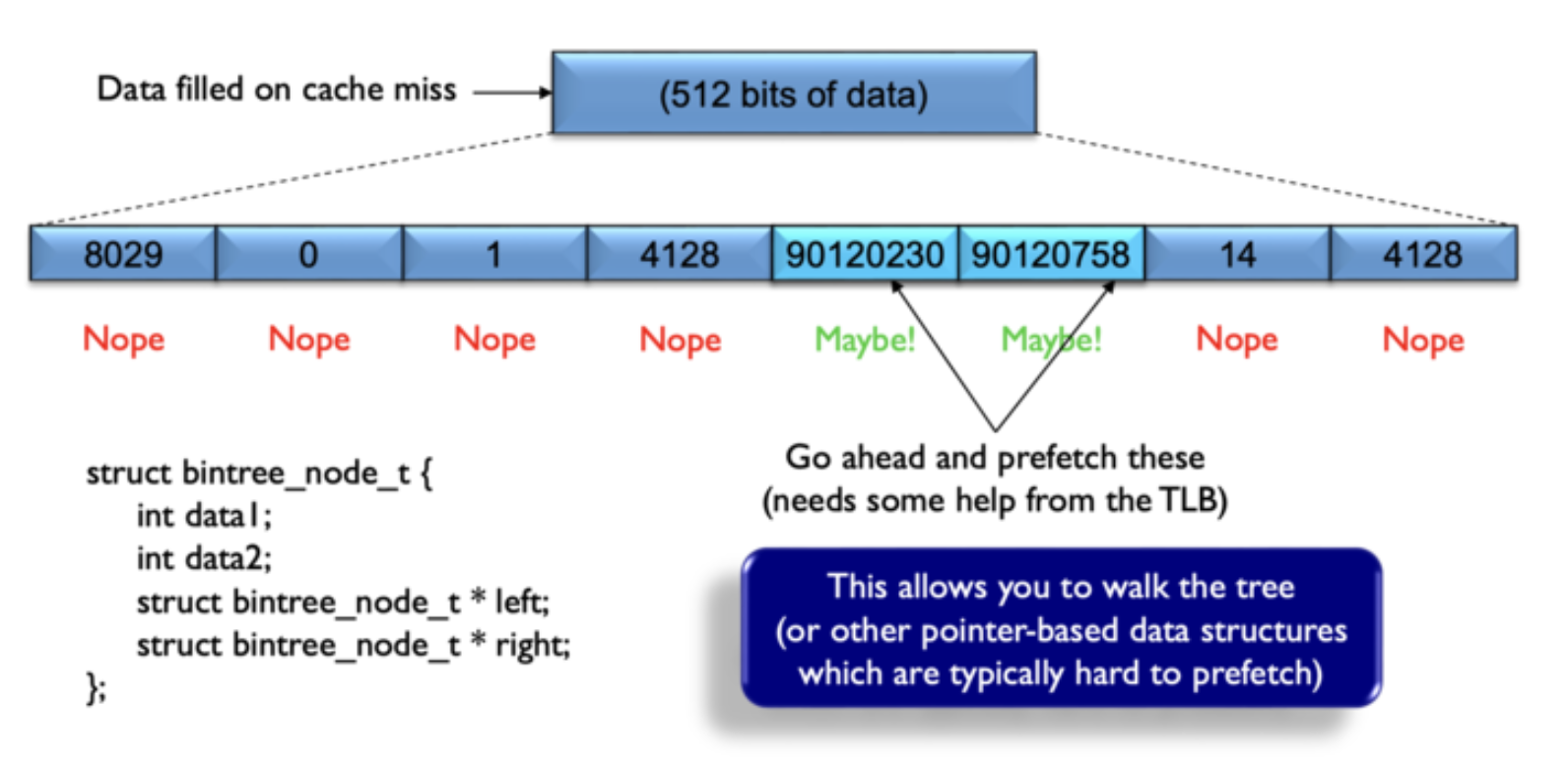
I restructured my code so that release_node(id) would return the pointer if and only if the reference count went to 0. I wish I could say that I thought the hardware prefetch was guessing wrong, but I was really only trying to avoid two reads of an atomic variable. (I store the pointer and reference count in the same atomic variable).
void release(node_id id ){
if( const node* node_ptr = release_node(id) )
release_children( node_ptr );
}
Would you imagine my surprise when this small change gave me a 3x increase in performance! I had just spent the better part of the prior day trying to use software prefetching to prevent stalls and every attempt at software prefetching (__builtin_prefetch) only made things worse! Then I make this small change and presto! All my memory stalls are gone.
To complete the picture here is some pseudo-code for get_node() and release_node():
node* get_node( node_id id ) {
return get_pointer(_atomic_nodes[id].load());
}
const node* release_node( node_id id ) {
auto prior = _atomic_nodes[id].fetch_sub(1);
if( prior.ref_count() == 1 ) {
free_node_id(id);
return get_pointer(prior);
}
return nullptr;
}
The old version of my code returned true/false from release_node and the new version returns the last pointer stored in the atomic before being released. As you can see, in both the old and new code the actual pointer is never dereferenced until within the body of release_children(); however, in the faster new code the pointer isn't even calculated until after the atomic reference count actually goes to 0.
So the old code produced a pointer on the stack that wasn't needed the majority of the time and the hardware prefetch would load it into memory even though it was never dereferenced. The new code also foils branch prediction that speculated on a call to release_children() because it produced a data-dependency on the result of decrementing the reference count before the pointer could be produced.
General Purpose Application
Any data structure that stores pointers must be aware that the data they point at could be prefetched whenever they are loaded even if the pointers are rarely used. This gave me an idea for a masked pointer:
template<typename T>
class prefetch_masked_pointer {
static constexpr uintptr_t mask = (1ull<<63) | 1;
prefetch_masked_pointer( T* p ):_mask_ptr( uintptr_t(p) ^ mask ){}
T* operator -> () { return (T*)(_masked_ptr ^ mask); }
uintptr_t _masked_ptr;
};
I have no idea if the above code is sufficient, but the idea is to change the highest and lowest bits of the pointer to something that doesn't look like a pointer. The low bit throws the alignment off for most pointers other than char* while the high bit attempts to put the address clear outside the valid address space. It might work just as well using a random 64 bit number.
With this prefetch-masked pointer, you can use it like a normal pointer except each (rare) dereference incurs an extra XOR operation. Variations on this theme could be used for masked_unique_ptr<T> or masked_shared_ptr<T>.
It might also be wise to not store infrequently needed pointers on cachelines with frequently used pointers.
Moral of the Story
It is not enough to be careful with what memory you actually touch, you must also be careful to not even load the address of memory you don't need. The appearance of accessing the memory can be just as bad as actually accessing it. More experimentation would be required to determine whether loading to the pointer to the stack is more dangerous than other pointer memory locations.
If you are aware of any other writings on preventing the hardware prefetch algorithms from accidentally polluting your cache with unneeded data I would be interested in hearing from you in the comments!
Looks sad...no one gives a.
Is it me? .. I keep on reading with a Slavik accent!
anxiety in the machine
Interesting how you framed it as a case study.
Congrats!
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
Processor make and model, please?