Postanowiłyście nauczyć się programować. Ale zasadnicze pytanie brzmi: dlaczego musicie uczyć się programować? Jako przykład podam Siri lub Asystenta Google – przecież można komputerowi wydać polecenie, czemu więc nie „Ok Google, stwórz mi program, który będzie miał pomarańczowe tło, i będzie wyświetlał zdjęcia kotków z neta, i każdy będzie mógł takie zdjęcie polubić”?
Co rozumie komputer?
W komputerze zasadniczo można wyróżnić trzy najważniejsze składowe:
- jednostkę obliczeniową,
- pamięć,
- urządzenia wejścia/wyjścia.
Jak widać, żadna z tych części nie nazywa się mózg i nie rozumie, co to znaczy, że tło ma być pomarańczowe. Komputer zrozumie za to, że ma w pamięci na obszarze reprezentującym obszar wyświetlacza o współrzędnych od X,Y do A,B wpisać wiele razy wartości (255, 165, 0), a sterownik wyświetlacza rozumie, że w pikselach o współrzędnych między X,Y a A,B ma zapalić całkowicie punkt czerwony i nieco ponad połowicznie zielony (tak naprawdę we współczesnych monitorach nie tyle reguluje się natężenie podświetlenia co stopień zasłonięcia światła, ale to jest średnio ważne).
Żyłka mi pęknie jak nie dam dygresji. Kolory na wyświetlaczach zazwyczaj opisuje się za pomocą trzech wartości z zakresu od 0 do 255 każda, gdzie liczby odpowiednio opisują natężenie kolorów: zielonego, czerwonego i niebieskiego (RGB). (0, 0, 0) to czarny, (255, 255, 255) to biały. Nie wiem, jak to działa w bardziej wymyślnych wyświetlaczach z dodatkowymi punktami (np. Sharp swego czasu robił takie cuda). W poligrafii używa się czterech kolorów: Cyan, Magenta, Yellow, blacK (CMYK) i jakoś inaczej to się opisuje.
Dygresja z grupy bezpieczeństwa. Swego czasu czytałem artykuł gościa, który opisywał swoje znalezisko: kiedy grał w grę (to musiał być Sylwester), pomiędzy dwoma częściami gry mrugnął mu obraz z filmu, który wcześniej oglądał. Wyłączył grę i napisał program do czytania zawartości pamięci na karcie graficznej (nie potrzebował do czytania żadnych uprawnień administratora). W ten sposób odnalazł w pamięci karty graficznej stany ekranu innych użytkowników. Błąd polegający na nieczyszczeniu wyświetlanego na ekranie obszaru pamięci, doprowadził go do możliwości podglądania aktywności innych użytkowników komputera.
A co to znaczy, że komputer cokolwiek rozumie? W zasadzie niewiele ma to wspólnego z rozumieniem. Jednostka obliczeniowa dostaje kod operacji (w określonym miejscu w pamięci), pobiera z innego miejsca w pamięci dane, zapisuje rezultat w miejscu wyniku wykonanej operacji, informacje dodatkowe gdzie trzeba, następnie pobiera następny kod operacji. Niezbyt to rozumne i niezbyt skomplikowane, ale od czegoś trzeba zacząć. Na tym oparty jest komputer/tablet/telefon, w którym czytasz ten tekst, więc jak widać, da się to nieźle wykorzystać.
O językach
Wróćmy do tematu języków.
Tu poruszymy trochę teorii. Nie przejmujcie się, jeśli nie będzie to zbyt zrozumiałe – wielu programistów nie ma o tym zielonego pojęcia, a zdecydowana większość nigdy lub prawie nigdy takiej wiedzy nie wykorzysta w praktyce. Darzę jednak tą tematykę dużym sentymentem i możliwe, że się z nią jeszcze kiedyś zmierzę. Pozdrawiam w tym miejscu serdecznie Pana dr. inż. Janusza Majewskiego i jego zespół, oraz pozostawiam link do strony z jego wykładami (dla zainteresowanych): http://kompilatory.agh.edu.pl/
Język jest scharakteryzowany przez swoją gramatykę. Gramatyka formalna składa się z kilku elementów, wśród których jest alfabet, z którego tworzy się słowa, i reguły, jak te słowa tworzyć. Pewien w deseczkę gość, zwany Noam Chomsky, zdefiniował klasyfikację gramatyk, od najbardziej restryktywnych (i najłatwiejszych do zrozumienia dla programów) do najluźniejszych. Wśród nich dwa rodzaje mogą nas zainteresować:
- gramatyki kontekstowe – prawidłowość użycia słowa i jego znaczenie zależy od kontekstu, w którym jest ono osadzone. z polskiego na nasze: jest opis jak tworzyć słowa i jak je składać, ale dwóch podobnych sytuacjach to samo słowo może mieć sens lub nie mieć, zależnie od innych czynników. w tej grupie mieszczą się języki naturalne,
- gramatyki bezkontekstowe – w każdej sytuacji prawidłowość użycia danego słowa jest znana i niezależna od jakiegokolwiek kontekstu. w tej grupie mieści się większość języków programowania.
Stworzenie gramatyki bezkontekstowej języka nie należy do najprostszych (chyba że język jest śmiesznie prosty). Zaletą jest możliwość stworzenia takiego narzędzia, które zawsze zrozumie dobrze sformułowany tekst (w naszym przypadku treść programu). Jeszcze więcej pracy/wiedzy/umiejętności wymaga stworzenie narzędzia, które taki tekst programu przeczyta i wykona lub przetłumaczy na kod maszynowy (żeby było ciekawiej, są też narzędzia, które przetłumaczą na postać pośrednią, a ta zostanie wykonana w środowisku uruchomieniowym).
Jak wspomniałem powyżej, program to tak naprawdę zbiór instrukcji, które komputer wykonuje, odczytując wartości ze wskazanych miejsc w pamięci, modyfikując je i zapisując we wskazane miejsca w pamięci. w sumie nie wiem, czy kiedykolwiek ludzie tworzyli programy bezpośrednio w kodzie maszynowym. Pewnie tak, i pewnie wciąż znajdują się tacy masochiści. w zasadzie coś w tym stylu wykorzystywały komputery, które używały kart perforowanych. To był swego rodzaju kod maszynowy, a raczej jego reprezentacja – wprowadzało się serię instrukcji i z pola wyniku czytało wynik. Jak widać nawet wędrującej dupy nie dało się wprowadzić.
Metoda wędrującej dupy to technika weryfikacji poprawności wykonania programu, polegająca na okresowym umieszczaniu w jego treści polecenia, wypisującego na ekran słowo "DUPA". Jeśli słowo nie pojawiało się, dana część kodu nie była wykonana.
Wyobraźcie sobie, że w ramach poprzedniego zadania wysłałem Wam pocztą skrzynkę czegoś takiego:

Karta perforowana. Public domain. Źródło: Wikipedia
To teraz jeszcze wyobraźcie sobie, że macie inne wersje komputerów w centrum obliczeniowym i u Was kolumna 46 na karcie 738 jest obsługiwana inaczej niż u mnie. Miłego szukania błędu.
Jako że człowieka szlag mógł trafić, konieczne były lepsze metody wprowadzania programu. Tak powstał pomysł używania symboli do zapisu instrukcji, a potem tłumaczenia do kodu maszynowego. Jednym z przykładów takiego zapisu jest grupa języków zwanych powszechnie Asembler (ang. Assembly language), który potem jest tłumaczony bezpośrednio do języka maszynowego, czyli tych kodów, które realizuje jednostka obliczeniowa.
Poniżej przykład kilku instrukcji, ładujących (zapisujących) do określonych miejsc w pamięci, zwanych rejestrami określone liczby:
(Zerżnięte z https://en.wikipedia.org/wiki/Assembly_language)
MOV AL, 1h ; Load AL with immediate value 1
MOV CL, 2h ; Load CL with immediate value 2
MOV DL, 3h ; Load DL with immediate value 3
Dorzućmy do tego jeszcze kilka operacji skoku (przejścia do instrukcji w innym miejscu w pamięci), porównania, jakąś kontrolę urządzenia (to wszystko operacje na pamięci, które mają przełożenie na inne urządzenia).
Programy napisane w Assemblerze da się już jakoś czytać, ale nie są jeszcze zbyt wygodne do pracy. Dlatego zaczęto budować języki wyższych poziomów: takie gdzie można operować na zmiennych, ciągach znaków, z wykorzystaniem bibliotek z już gotowymi zestawami funkcji. Początkowo konieczne było w nich zarządzanie alokowaniem i zwalnianiem pamięci, ale późniejsze języki często zyskiwały też zautomatyzowane zarządzanie pamięcią.
Mógłbym tu pisać o wielu językach, ale to nie ma póki co większego sensu. z ciekawostek mogę powiedzieć, że gdy korzystacie z arkusza kalkulacyjnego do obliczeń, także programujecie.
Zarządzanie pamięcią: Jeszcze nie doszliśmy do etapu, gdzie trzymamy jakieś wartości w pamięci. Ale dojdziemy i warto wiedzieć, co ma się dziać z danymi, które nie są już potrzebne. Niektóre języki zostawiają kontrolę nad tym w rękach programistów (z nierzadko opłakanymi skutkami, o czym porozmawiamy kiedyś), inne kontrolują i same rządzą wszystkim; są też takie, które robią coś pomiędzy. Każdy model ma swoje walety i zady. Zwalnianie pamięci określa się zwrotem „garbage collection” (ang. odbiór śmieci). Jeśli język (lub środowisko uruchomieniowe dla jego programów) uwzględnia zarządzanie pamięcią, musi rozwiązać kilka problemów:
- Jak rozpoznać, czy pamięć uwolnić,
- Czy dane wyczyścić, czy może zostawić do nadpisania przez nowe,
- W jaki sposób zwalniać pamięć,
- Kiedy zwalniać pamięć,
- Jak często zwalniać pamięć.
Język Rust, którego naukę rozpoczęliśmy, udostępnia mechanizmy ręczneg zarządzania pamięcią, choć czyni to w dość specyficzny sposób - programista deklaruje, z ilu miejsc można wskazywać na dane w pamięci, a dane te są usuwane dopiero wtedy, gdy żadne z tych miejsc już nie jest używane.
Przy okazji wspomnę, że Rust jest językiem kompilowanym. Oznacza to, że polecenia budujące wykonują tłumaczenie programu w Go docelowo do kodu maszynowego, wykonywanego przez komputer, a nie formy pośredniej, która wymaga jeszcze kolejnego programu do wykonania.
Dla zainteresowanych: Książka o składni języka Rust.
Coś praktycznego
Trochę długi zrobił się ten wstęp, więc przystąpmy do czegoś praktycznego. Dotychczas mieliśmy tylko jeden program, który coś wypisywał. Jak domyślacie się, szczyt inżynierii oprogramowania to to nie jest. Zazwyczaj kod zawiera jakieś wartości, jakieś funkcje, które wykorzystuje się wielokrotnie, jakieś operacje, uzależnione od spełnienia pewnych warunków itd. Dziś trochę tego poznamy.
Przypomnijmy program z poprzedniej lekcji i zaadaptujmy go do Metody Wędrującej Dupy:
fn main() {
println!("DUPA");
}
Chciałbym zwrócić Wam uwagę na strukturę programu - implementacja funkcji main to jest absolutne minimum, aby mieć wykonywalny program (no, nie trzeba wypisywać „DUPA” na ekran, funkcja main może być pusta).
Funkcja – sekwencja poleceń, które można wykonać poprzez jej wywołanie. Funkcja main z definicji ma nie mieć argumentów i nie zwracać żadnego wyniku.
Dodajmy zatem coś do naszego kodu:
fn main() {
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 1. zwrotka, teraz będzie 2. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 2. zwrotka, teraz będzie 3. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 3. zwrotka, teraz będzie 4. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 4. zwrotka, teraz będzie 5. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 5. zwrotka, teraz będzie 6. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 6. zwrotka, teraz będzie 7. zwrotka");
}
Jak widać, moje przykłady mają tyle polotu, że mietczynski mógłby im poświęcić specjalny odcinek na YouTube.
Mamy jakiś kod, w którym dużo się powtarza. Jak się dużo powtarza, to niedobrze. Widzę tu trzy problemy:
- Trzeba było się narobić, aby to powielić,
- Więcej kodu to więcej miejsca na błędy,
- Jak coś się powtarza, a mamy w tym błąd, trzeba go rozwiązać tyle razy ile jest powtórzeń.
Spróbujmy to nieco poprawić.
Najpierw zwróćmy uwagę, że w każdej zwrotce mamy dwa numerki, które różnią się od siebie o 1. Może spróbujmy je zastąpić czymś, aby mieć jedno miejsce do kontroli/zmiany wartości. Wprowadzimy zmienną:
let mut i = 1;
Deklarujemy zmienną (let mut; mut oznacza, że będziemy mogli modyfikować jej wartość), nadajemy jej nazwę „i” i przypisujemy jej wartość 1. Teraz jej użyjmy:
fn main() {
let mut i = 1;
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była {}. zwrotka, teraz będzie {}. zwrotka", i, i + 1);
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 2. zwrotka, teraz będzie 3. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 3. zwrotka, teraz będzie 4. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 4. zwrotka, teraz będzie 5. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 5. zwrotka, teraz będzie 6. zwrotka");
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była 6. zwrotka, teraz będzie 7. zwrotka");
}
Zwróć przy okazji uwagę na to, jak osadziłem wartość w treści. Używając znaków {} poinformowałem makro, że potem będzie jakaś wartość, którą należy tam umieścić.
Fajnie, mamy zmienną, ale nie ułatwia nam to zbytnio życia. Nawet kompilator krzyczy, że coś jest nie tak:
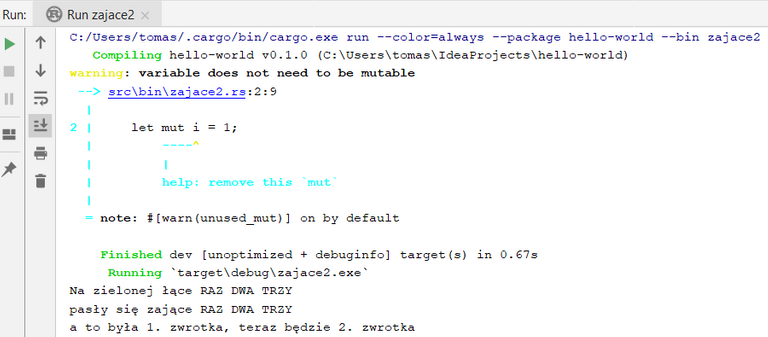
Narzeka, że zmienna jest niepotrzebnie zadeklarowana jako modyfikowalna. Uzupełnijmy ten kod nieco:
fn main() {
let mut i = 1;
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była {}. zwrotka, teraz będzie {}. zwrotka", i, i + 1);
i += 1;
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była {}. zwrotka, teraz będzie {}. zwrotka", i, i + 1);
i += 1;
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była {}. zwrotka, teraz będzie {}. zwrotka", i, i + 1);
i += 1;
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była {}. zwrotka, teraz będzie {}. zwrotka", i, i + 1);
i += 1;
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była {}. zwrotka, teraz będzie {}. zwrotka", i, i + 1);
i += 1;
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była {}. zwrotka, teraz będzie {}. zwrotka", i, i + 1);
}
Jest już postęp, ale teraz mamy kilka identycznych kawałków kodu. Czy musimy tyle pisać, aby wyświetlić na ekranie tę piękną śpiewkę? Gdyby tylko był jakiś sposób, aby wykonać tą samą instrukcję wiele razy…
Otóż jest! Jest dla nas ratunek! Możemy (fanfary!) użyć pętli!
W języku programowania zazwyczaj jest kilka elementów, które pomagają kontrolować przebieg programu. Przykładem są właśnie pętle. Pętla posiada dwa elementy:
- sekwencja poleceń do wykonania
- warunek wyjścia/kontynuacji
Aby użyć pętli, piszemy coś takiego:
fn main() {
let mut i = 1;
while i < 7 {
println!("Na zielonej łące RAZ DWA TRZY
pasły się zające RAZ DWA TRZY
a to była {}. zwrotka, teraz będzie {}. zwrotka", i, i + 1);
i += 1;
}
}
Co tu się wydarzyło w tej funkcji:
- Zadeklarowaliśmy zmienną i przypisaliśmy jej wartość 1,
- Podaliśmy warunek, sprawdzany przed wykonaniem każdego cyklu w pętli:
i<7. Tak długo jak i jest mniejsze niż 7, zawartość pętli będzie wykonana, - Powiedzieliśmy, co należy zrobić z wartością i na końcu wykonania pętli.
Nie jest to jedyna pętla w Rust, ale na dziś wystarczy.
Tyle. Chciałem jeszcze dodać deklarowanie funkcji, ale to już zostawię na następną lekcję. Im więcej czytam, tym bardziej czuję, że jest tu bardzo dużo chaosu. Poczekam na pytania i uwagi, po czym poprawię ten wpis i napiszę kolejny, gdzie uzupełnię i nieco uporządkuję zawarte informacje.
Praca domowa
Zadanie 1: Fizz Buzz
Napiszecie program, który pojawia się od czasu do czasu na rozmowach o pracę, gdy prowadzone są one na tablicy suchościeralnej.
Będziecie wypisywać coś na standardowe wyjście dla każdej liczby od 1 do 100.
Jeśli liczba jest podzielna przez 3, wypiszecie Fizz.
Jeśli liczba jest podzielna przez 5, wypiszecie Buzz.
Jeśli liczba jest podzielna przez 3 i 5 jednocześnie, wypiszecie FizzBuzz.
W każdej innej sytuacji wypiszecie wartość liczby.
W ramach ułatwienia dwie informacje:
operatorem arytmetycznym, zwracającym wartość reszty z dzielenia, jest %. 127%23 zwróci 12,
Warunek w kodzie umieszcza się z użyciem słowa if. Warunek można rozbudowywać dzięki słowu else. Else przedstawia ścieżkę alternatywną. Można ją również połączyć z kolejnym warunkiem:
if a == 2 {
println!("I am a two");
} else if a == 3 {
println!("I am a three");
} else {
println!("I'm a loser Baby.");
}
Zadanie 2: Pół choinki (trudniejsze)
Chcę, abyście wypisały pół choinki z dowolnie wybranego znaku (bez pniaka)
Choinka ma mieć trzy rzędy gałęzi, każdy niższy większy od poprzednich. Ma to wyglądać mniej więcej tak:
@
@@
@@@
@@
@@@
@@@@
@@@@@
@@@
@@@@
@@@@@
@@@@@@
@@@@@@@
Każdy rząd gałęzi będzie większy od poprzedniego o jeden.
Zadanie 3, rozszerzające
Wydrukuj choinkę z zadania 2 na wyjściu błędów. Wyjaśnij czym jest wyjście błędów, standardowe wyjście, standardowe wejście. To zadanie wymaga umiejętności korzystania z wyszukiwarki internetowej.
Zadanie 4: Cała choinka (najtrudniejsze)
Chodzi o to, abyście wypisały pełną choinkę, nie tylko pół. Wiem że to jest trudniejsze, ale dacie radę. Jeśli nie, przyjmijmy że zadanie trzecie jest opcjonalne (na szóstkę).
!tipuvote 0.5
This post is supported by $0.28 @tipU upvote funded by @grecki-bazar-ewy :)
@tipU voting service: get instant upvotes + profit sharing tokens | For investors.
Congratulations @kurykodowe!
Your post was mentioned in the Steem Hit Parade for newcomers in the following category:
I also upvoted your post to increase its reward
If you like my work to promote newcomers and give them more visibility on the Steem blockchain, consider to vote for my witness!