Malcolm McEwen (originally posted on phasm.co.uk )
We tend to regard data as if it were a thing with dimensions and boundaries. A product of the information age we live in it travels like the cargo of a ship on the virtual ocean that is the information highway; when in fact the cargo, the ship and the information highway are all data, there is only ocean.
This ocean of data drives society, determines national budgets, aids decisions in industry and pigeon holes us into social and economic groups. From the global to the personal level data plays a significant role in all the decision processes of everyone's life. Processes that if based on poor inaccurate, out of date or misleading data risk making decisions that are equally poor, misleading and out of date.
So, if we are to make good decisions, we need to know the outcomes, the benefits and consequences of our actions on ourselves, our neighbours and our environment. We need to understand the relationship between the macro and the micro, the local and the global and the only way to do that is through the data.
According to some reports we have generated more data in the last five years than in our entire history and each year we generate more. With this explosion in data comes opportunities for improving our decision processes and achieving global sustainability objectives. However with those opportunities come challenges in handling, differentiating and working out just what is and is not useful. For no data, is better than the wrong data. The right data however, despite what Mark Twain would aver, makes for good statistics and good statistics support good decision processes. But what is the 'right data' in an information age awash with the stuff.
What Is Data
The internet is data, everything on it and every piece of software on a computer is made up of Data. However in the context herein data has the more 'narrow' scientific definition of:
“a set of values or measurements of qualitative or quantitative variables, records or information collected together for reference or analysis,” (Wikipedia)
it is the cargo on our ship...
The contents of a telephone book is an example of data collected for reference. Data that can and is put into databases for analysis. Once entered it can be re-organized and sorted so as to reveal how the names are distributed, measure their frequency and estimate ethnic or social economic distributions. The analysis might reveal odd correlations, trends and anomalies, such as the frequency at which three sixes appear in the telephone numbers of people with double barrel names, that would otherwise be missed. Such anomalies can fuel conspiracies and are examples of statistics being used like a drunk uses a lamp post, more for support than illumination. In truth there is though little one can get from a telephone book other than a telephone number and an address. That's not to say that data isn't useful.
Types Of Data
Data categorisation is very much dependent on purpose; there is no single category structure applicable to all. With that in mind I propose four Data 'spheres' to initially distinguish data types.
Personal Data
A telephone book is just one source of personal data, as is a mailing list, a club membership, a bank account or a tax office receipt. Individually these data sources provide limited information about an individual but contain fields (name,address, etc) that make it easy to link the data so that collectively it documents extensive details about an individual's personal and financial life. Scary stuff and whilst it's the most precious kind of data it similarly makes up an insignificant fraction of the total data currently held or being generated by the internet.
Economic Data
The state of the nation, the productivity of industry and the movement of goods and services within and between trading entities relies on the supply of good data. The budget, government policy and changes to or creation of new laws all rely on good relevant data. Without it there would be no means to balance the books, to calculate a nations GDP and value it's currency. However data collection currently lags behind the policy that relies on it. At best the figures are for the previous quarter but more often than not are estimates aggregated together from different sources.
Sociopolitical Data
Domestic government policy on health and education as well as changes to and creation of new laws all rely on good data. At the regional level Data determines how policy will be implemented and budgets distributed between schools, policing, refuse collection, etc. National and local government therefore needs quantitative and qualitative data on the demographics, social trends, political, cultural and ethnic identities of the people it serves.
Environmental Data
Environmental data includes any lab, field and desktop data from any chemical, physical or biological discipline from the natural sciences. All data relating to Earth and biological disciplines from theoretical particle physics to the applied science of agriculture are forms of Environmental Data.
Non Exclusive Nature Of Data
Within these spheres data can be quantitative/qualitative, spatial/temporal, deterministic/stochastic or combinations there of. The data may similarly be relevant to a few, many or have a lasting or fleeting influence, and whilst most data conforms to the categories above some straddles more than one and all of it interacts with and influences the data in others. So whilst we can can compartmentalize data we can only understand it in the context of the whole.
What Is A Database
A database is an application (program) into which data can be input and organised to provide an indexing system or display statistical information on the data. A simple data set could be a membership list of a golf club. Each entry containing details on a members name, age, address, joining/subscription date and details of their achievements (i.e. handicap, or records held). The database would allow the club to sort the details by any field (name, age, address, joining date, subscription renewal, handicap, etc) and compile simple statistics (i.e. avg age, length of membership) or see who hadn't paid their subs. A database might store values, charts, tables, files or just the location of the data as with bit torrent file sharing sites or search engines (i.e. google).
Types Of Database
All databases store information, ideally for easy retrieval. What differentiates one from another is the way the data is stored (within the database itself, or links to an external location), where the database is held (central or distributed), and how the data is subsequently accessed (public or private).
Traditional Database
Whilst limited and not generally regarded as a true database, a spreadsheet performs all the basic functions of one. MySQL the database in the LAMP (Linux Apache MySQL PHP) stack that drives the internet is an example of a more complex database. A MySQL database stores the content and links to a web sites media. This content is accessed though PHP scripts ( i.e. a Content Management System like WordPress) and then served to the internet by an Apache server built using Linux.
Distributed Hash Table (DHT)
A Distributed Hash Table (DHT) is a database that stores only the location(s) of a file along with a hash value (a unique reference that is the sum of the contents of the file). The hash value stored in the database can then be compared with that of the external file in order to qualify the integrity of the external file. A DHT may also hold data on when the file(s) was added, the last time it was accessed and the total number of calls made to the file. A DHT is a mechanism used for indexing and distributing files across a P2P network.
Blockchain
The bitcoin blockchain solves trust issues for cryptocurrency, but burns a lot of fossil fuel in the process. Although the bitcoin blockchain is referred to as a distributed database, it is more a duplicated ledger with every node maintaining an identical copy of the entire database. All nodes compete to balance the ledger by guessing a hash value; a value that can't be calculated easily and can only by discovered by brute force. Guessed correctly it balances the entire system, and creates a block. That in a nut shell is the proof of work concept that makes the Bitcoin blockchain secure; A very energy hungry solution to solve an integrity issue with Homo sapiens.
A Framework For Sustainability
In a previous post I summarised the recent technical report by the Open Data Institute (ODI) (http://theodi.org/technical-report-blockchain-technology-in-global-data-infrastructure) which raised the need for a “blockchain ecosystem to emerge that mirrored the common LAMP 7 web stack” and was “compatible with the Web we have already.”
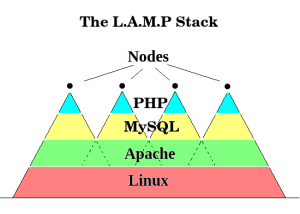
Reliable and secure the software that underpins the LAMP stack is, it is now nearly 20 years old and has arguably reached its peak. It has similarly evolved to be better at generating data than dealing with it. It’s good at serving files, not dealing with the information in them, so whilst the evolution of a data stack needs to evolve alongside the existing web structure it will likely be an evolution independent of it. One ‘promising’ data stack identified by the ODI team which met this criteria was “Ethereum as an application layer, BigchainDB as a database layer and theInterplanetary File System (IPFS) as a storage layer”.
Application Database Storage (ADS) Network
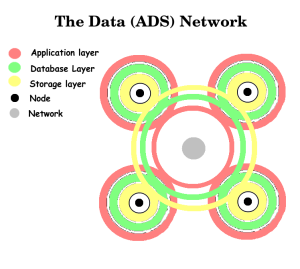
Unlike the LAMP stack the data ecosystem is more likely to evolve as a weave of intertwined data streams that converge on nodes that use the data. Similarly with the LAMP stack exchanges between nodes occurs at the server level, in an ADS network exchanges of data would occur in all layers, Application, Database and Storage.
The Application Layer
What makes databases powerful are the scripts, applications, programs and content management systems that use it. Scripts that are similarly responsible for entering data and with the rapid growth in smart appliances and the IoT this data inputting is increasingly becoming automated. How useful all that data turns out to ultimately be will depend as much on the applications that can use the data effectively as on the databases that store and organize it. Once data no longer has a processing value it would be archived, an action that would be performed by an application.
The Database Layer

The database layer is where the data that serves different economic, social and environmental purposes is indexed and organized. It may be data that is or is not stored in the database and data that is used by multiple applications. To avoid unnecessary duplication; blockchain, DHT and SQL type databases will need to be able to synchronize data.
The Storage Layer
If the database is the indexing layer, the storage layer is what is largely being indexed. A place for enduring data the storage layer is where files, large legacy databases, redundant or archived data is stored for retrieval by databases and applications.
Blockchain As Metronomes In An ADS Network
The main function of a blockchain is to provide an immutable ledger that can be trusted. It’s a property an ADS network can exploit in supply chain auditing to provide a trusted data source for multiple users in a network. Blockchain is an ideal tool with which to build an authentication and tracking system that shadows produce as it moves from farm to fork (strengthening the food chain with a blockchain)
A Manifest Of Global Agricultural Produce
ADS Network Providing invaluable data to producers, importers, retailers and consumers alike, with an authentication and tracking system on the blockchain the the origin and route produce took to market could be qualified.Once established a consumer would have access to an audit trail where they would be able to authenticate origin, standards in production or the carbon footprint of food. Detailing the precise route that the produce took from the field to the shelf would give Importers and Retailers insight into double handling, stalling and wastage on route, whilst National and Supranational bodies would have precise data on the production, origin and consumption of agricultural produce. If data be the cargo in an ADS network, supply chain authentication and tracking system is the ship that carries that data.
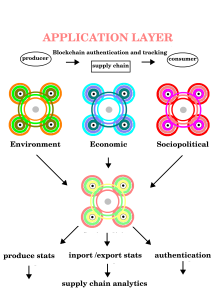
Sowing The Seeds For Integrated Crop Production And Management Systems
With an authentication and tracking system in place a farmer would be able track in real time how much produce left the farm and reached the intended market. He would be able to see this relative to his neighbour, relative to acreage of a given crop in a region and relative to all the routes that crop took to market.Without having to communicate all farmers in a publicly accessible authentication and tracking system would be incidentally exchanging data; data that can help all of them plan and co-ordinate crop choices and market logistics.It is a small step for that hub to widen, to encourage integrated crop production and management in farms across a region and improved logistics to tackle over and under production and transport wastage. One more step and farmers could begin to operate in their own regional network not only to produce and supply food but to create co-operatives to allocate resources more amicable or developing integrated fertility programs. My experiment with IRCC Cameroon was an attempt to remotely put such a structure in place.
Supporting The Development Of A Peer To Peer Economy
Farmers are not the only ones who could build co-operatives around a supply chain. Retailers and even consumers at the other end could use an authentication and tracking system to order directly from producers. They could pay for that produce using crypto-currency that could be placed in an escrow arrangement pending delivery. That order could then be automatically coordinated through logistics operators to find the optimum route, and then tracked to the delivery address. On arrival the receipt of the order would trigger the payment out of escrow. It’s a future that relies first on the establishment of an authentication and tracking system.
Undermining The Dark Web
The P2P economies of the dark web rely on the pseudo-anonymity of crypto-currency, anonymous reputation systems and the anonymous global delivery systems run by states and governments to operate. With an authentication and tracking system the missing links in the supply chain can be put back. Whilst not completely ending the Dark Web markets an authentication and tracking system addresses the anonymity of the delivery systems used.
Hi! I am a content-detection robot. This post is to help manual curators; I have NOT flagged you.
Here is similar content:
http://phasm.co.uk/data-databases-and-distributed-network/
NOTE: I cannot tell if you are the author, so ensure you have proper verification in your post (or in a reply to me), for humans to check!
hi cheetah .. I am indeed the author..