Photo by Denys Nevozhai on Unsplash - https://unsplash.com/photos/2vmT5_FeMck

This is short overview of machine learning. What it is, what learning is and what it's most common concepts are. It is designed as a first step into the topic.
📄 Table of contents
"A wise man can learn more from a foolish question than a fool can learn from a wise answer." - Bruce Lee
What is Machine Learning (ML)
ML finds patterns in data and uses them to predict the future.
Learning requires:
- identifying patterns
- recognizing those patterns
Now it's easy to find patterns. But it is not easy to find patterns that are correct. Increasing the size of data allows to predict outcome that is more and more correct.
| Data | Algorithm | Model | Application |
|---|---|---|---|
| contains patterns | finds patterns | recognizes patterns | uses to recognition on other data |

Common programming languages used for ML are:
- R
- Python
The learning process
1. Asking questions
- what questions to ask
- what data helps you to answer the question
- how do you measure success
2. Iterate
- select and prepare your data over and over to make it useable for the algorithm
- apply an algorithm on the data and create models over and over to increase your success rate
- expose and test successful models to different data
ML concepts
- supervised learning (the value you want to predict is already in the data)
- unsupervised learning (the value you want to predict is not in the data)
Data preprocessing with supervised learning
Raw data has to be transformed in to training data by removing unnecessary items like duplicates, wrong/false information, useless information.
The training data contains features, which stand for important classifications and target values, which stand for the desired piece of information for the model.
Problems
| regressions | classification | clustering | |
|---|---|---|---|
| Goal | trying to find a line or curve that fit the data | trying to group data into classes | trying to identify segments of the data |
| Example |  |  |  |
| Image Credit | By Sewaqu - , Public Domain, Link | By Elizabeth Goodspeed - , CC BY-SA 4.0, Link | By Chire -, CC BY-SA 3.0, Link |
Algorithms
Common styles are:
- decision trees (construct a model based on actual values of attributes in a data)
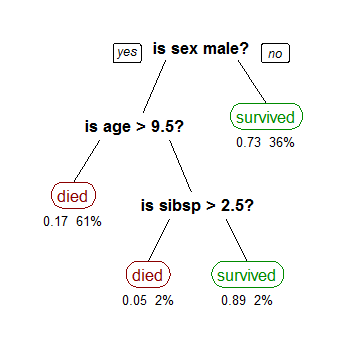
By Stephen Milborrow - , CC BY-SA 3.0, Link
- neural networks (construct a model based on the recombination and reevaluation of results within the training data)

By Glosser.ca - , Derivative of File:Artificial neural network.svg, CC BY-SA 3.0, Link
- bayesian (filters according to probabilistic classifiers)

By AnAj -, Public Domain, Link
- K-means (construct a model based on vector quantization to the k closest training examples)

By Chire - Public Domain, Link
(Iris flower data set, clustered using k means (left) and true species in the data set (right). Note that k-means is non-determinicstic, so results vary. Cluster means are visualized using larger, semi-transparent markers. The visualization was generated using ELKI.)
Training the model
- find features that are relevant to identifying the target value
- put a significant percentage of the features data into the algorithm
- generate a model
- test the model with the remaining percentage of the features data by comparing the target values with the values form the actual data
- if the model is not accurate, change the features, change the algorithm or change the data

By Docurbs - , CC BY-SA 4.0, Link
Thanks for reading my article! Feel free to leave any feedback!
Daniel is a LL.M. student in business law, working as a software engineer and organizer of tech related events in Vienna.
His current personal learning efforts focus on machine learning. Connect on: