Bonjour à tous,
Récemment j'ai lu un article par @mengene qui explique comment il a utilisé des méthodes de Deep Learning in biologie. Ça m'a inspiré à écrire mon propre article à propos de mon dernier projet universitaire où j'ai utilisé un réseau neuronal dans le domaine de la microfluidique et comment vous pouvez utiliser la même technologie très facilement sur vos propres projets.
Ce que j'essayais de faire
Reprenons depuis le début, mon boulot pendant ce projet fut d'assister Marc Prudhomme, un doctorant, sur une partie de ses travaux pour sa thèse. Il a déjà construit plusieurs dispositifs capables de générer des microbulles, mais pour connaitre la taille des bulles qui sont créées lors des expériences il a besoin de cliquer plusieurs fois sur les bords de nombreuses bulles. Cette procédure prend beaucoup de temps et les photos du microscope ne sont pas forcément les images les plus nettes que j'ai pu voir. Il m'a donc demandé si je pouvais automatiser la procédure pour simplifier les expériences.
Après une recherche "approfondie" d'internet, j'ai trouvé 2 solutions pour détecter des cercles dans les images :
- La Transformée de Hough appliquée aux cercles
- Les réseaux neuronaux pour la détection d'objets
La première est déjà implémentée dans un module Python populaire nommé OpenCV. À première vue, cette solution parait plutôt simple à implémenter.
La seconde nécessite un jeu de données (dataset) conséquent que l'on doit créer manuellement et douloureusement, de plus je n'avais aucune idée du temps d'entrainement nécessaire pour obtenir un réseau suffisamment précis. J'ai donc choisi d'utiliser la transformée de Hough.
Ce que je n'avais pas anticipé, fut que l'implémentation dans OpenCV rendait la détection de cercles concentriques plutôt difficile, mais surtout que le moindre changement de conditions (luminosité, netteté) ou de taille des bulles perturbait entièrement la mesure nous forçant à modifier les paramètres manuellement pour chaque mesure. Ce qui prend beaucoup de temps, trop de temps. Voici un exemple de ce que j'arrivais à obtenir une fois que les paramètres sont ajustés :

Et ce à quoi ça ressemble lorsqu'ils ont très légèrement décalé :

J'ai encore passé quelques jours a essayé d'améliorer le résultat, mais j'ai finalement abandonné cette solution juste avant les vacances de Noël à cause de la quantité d'efforts nécessaires pour obtenir la mesure que l'on cherche à chaque fois que l'image est légèrement différente.
C'est alors que, je ne sais pas exactement comment, peut-être une anomalie spatio-temporelle, j'ai eu un peu de temps libre pendant les vacances. J'ai décidé de donner une chance au réseau neuronal.
Débuter avec les réseaux neuronaux pour la détection d'objets
Je me suis donc mis à la recherche d'une architecture qui me permettrait d'entrainer facilement un réseau neuronal avec mes propres données. Mais je n'avais pas seulement besoin de classifier les images, j'avais aussi besoin de connaître les coordonnées des boites de délimitations (bounding boxes) qui entourent les objets détectés pour mesurer la taille des bulles.
Je me suis souvenu d'une architecture appelée YOLO capable de telles prouesses (You Only Look Once, Tu ne Regardes qu'Une Fois, TRUF mais cet acronyme personne ne l'utilise ;) ). Aujourd'hui, YOLO en est à sa 5eme version (qui proviennent de différents auteurs), et de mon point de vue, c'est la plus simple à essayer. Donc voici comment faire avec YOLOv5 !
Préparation d'un bon dataset
Je n'étais pas prêt à passer plusieurs jours pour créer le jeu de données, j'ai donc choisi 20 images parmi les photos que j'avais à ce moment. Mon objectif principal lors de la sélection est de choisir des images aussi diversifiées que possible pour entrainer le réseau à fonctionner dans toutes les situations qu'il pourrait rencontrer. J'ai ainsi mis des photos issues de 2 caméras différentes, avec des bulles de tailles et de concentrations variées et des luminosités différentes. Je voulais aussi pouvoir tracer les boites autour de chaque bulle présentes sur l'image, je les ai alors recadrées pour qu'elles ne contiennent qu'une douzaine de bulles chacune.
Vous combinez cela à la découverte du site MakeSense.ai, un site internet qui vous permet de tracer facilement les boites autour des objets, cela m'a permis de créer le dataset à la vitesse de l'éclair, en quelques heures tout de même.
Donc, une fois que vous avez sélectionné vos images, séparez-les en 2 dossiers, le premier avec la majorité des images (j'en ai choisi 16) pour l'entrainement et placez quelques images dans le second dossier (j'en ai mis 4) pour la partie évaluation.
Ensuite, importez les images du premier dossier dans MakeSese.ai après avoir cliqué sur le bouton "Get Started". Puis cliquez sur le bouton "Object Detection" et remplissez les labels dont vous aurez besoin pour repérer vos objets, personnellement je n'ai besoin que d'un seul label que je vais appeler "Bubble". Vous pouvez aussi charger pendant cette étape un fichier contenant des labels d'un précédent projet.
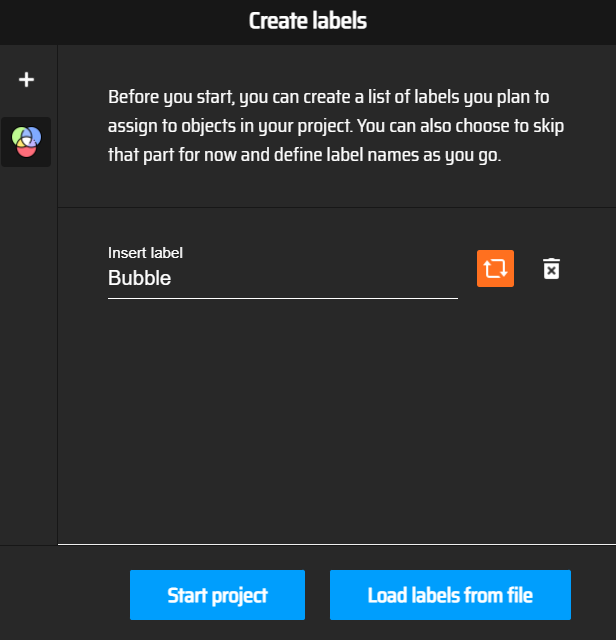 Capture d'écran du site MakeSense.ai, où l'on choisit les labels
Capture d'écran du site MakeSense.ai, où l'on choisit les labels
Ensuite, cliquez sur "Start Project" et dessinez les boites autour de vos objets sur l'ensemble des images en prenant soin d'être minutieux sur les contours et les labels utilisés.
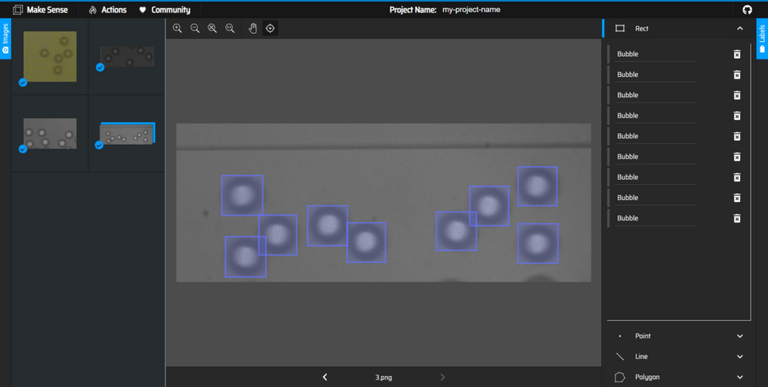 Capture d'écran du site MakeSense.ai, où l'on dessinne les boites entourant les objets
Capture d'écran du site MakeSense.ai, où l'on dessinne les boites entourant les objets
Quand vous avez fini de dessiner les boites sur toutes les images, cliquez sur "Actions -> Export Annotations" :
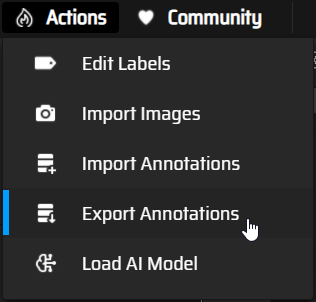 Screenshot of the MakeSense.ai website, Panneau Actions
Screenshot of the MakeSense.ai website, Panneau Actions
Enfin, cochez la case à propos du format YOLO et cliquez sur "Export". Vous obtiendrez un fichier compressé contenant les fichiers textes avec les informations sur chaque boite que vous avez créé.
Il faut ensuite faire la même chose avec le deuxième dossier.
Quand vous avez exporté l'ensemble de vos annotations, vous pouvez créer un dossier avec le nom que vous voulez (j'ai choisi "train_data") où vous allez créer un fichier avec l'extension .yaml (j'ai mis bubble.yaml). À l'intérieur de ce fichier, nous allons définir le chemin vers les images utilisées pour l'entrainement et l'évaluation, mais aussi le nombre de classes (nc) et le nom des différentes classes dans le même ordre que sur MakeSense.ai :
train: train_data/images/train
val: train_data/images/val
# Classes
nc: 1 # nombre de classes
names: ['Bubble'] # nom des classes
On crée ensuite 4 nouveaux dossiers de cette manière
train__data
│ bubble.yaml "The file you just have created"
│
├───images
│ ├───train
│ │ "Mettez les images pour l'entrainement ici"
│ │
│ └───val
│ "Mettez les images pour l'évaluation ici"
│
└───labels
│
├───train
│ "Mettez les fichiers textes générés par MakeSense.ai pour l'entrainement ici"
│
└───val
"Mettez les fichiers textes générés par MakeSense.ai pour l'évaluation ici"
On place ensuite les images dans les dossiers correspondants nommés "images" et les annotations dans les dossiers "labels". Vous devriez obtenir quelque chose comme ceci :
train_data
│ bubble.yaml
│
├───images
│ ├───train
│ │ 0.png
│ │ 1.png
│ │ 10.png
│ │ 11.png
│ │ 12.png
│ │ 13.png
│ │ 14.png
│ │ 15.png
│ │ 16.png
│ │ 2.png
│ │ 3.png
│ │ 4.png
│ │ 5.png
│ │ 6.png
│ │ 7.png
│ │ 8.png
│ │ 9.png
│ │
│ └───val
│ 0.png
│ 1.png
│ 2.png
│ 3.png
│
└───labels
├───train
│ 0.txt
│ 1.txt
│ 10.txt
│ 11.txt
│ 12.txt
│ 13.txt
│ 14.txt
│ 15.txt
│ 16.txt
│ 2.txt
│ 3.txt
│ 4.txt
│ 5.txt
│ 6.txt
│ 7.txt
│ 8.txt
│ 9.txt
│
└───val
0.txt
1.txt
2.txt
3.txt
Vous êtes maintenant prêt pour l'entrainement !
Entrainer votre Réseau Neuronal
Cette partie va prendre pas mal de temps, mais cette fois-ci c'est au tour de l'ordinateur de travailler et pas vous. On commence par installer tous les outils dont on va avoir besoin : Git, Python et pyTorch. Vous pouvez aussi tester tout ce que l'on va voir avec un simple clic sur mon Google Colab si vous ne pouvez pas ou ne voulez pas installer quoique ce soit sur votre ordinateur (vous avez juste à changer le lien GitHub par votre propre jeu de données). De plus vous pourrez utiliser les cartes graphiques de Google bien plus rapidement que mon PC. Il suffit de cliquer sur "Runtime -> Run All" pour exécuter toutes les commandes et voir ce qu'elles font.
Une fois que pyTorch est installé sur votre PC, ouvrez un terminal dans le dossier de votre choix et exécutez les commandes suivantes :
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -qr requirements.txt
Copiez ensuite votre dossier contenant les photos, annotations et fichier yaml (celui que j'ai appelé train_data précédement) dans le dossier yolov5. Ensuite, on va utiliser cette commande pour entrainer le réseau neuronal, mais avant de l'exécuter, voici une explication des différents paramètres :
python train.py --img 640 --batch 8 --epochs 80 --data train_data/bubble.yaml --weights yolov5s.pt --cache
La phase d'entrainement est réalisée par le programme train.py de yolov5, nous avons besoin de renseigner un certain nombre d'arguments :
- --img : taille de l'image (si les objets ne sont pas relativement trop petit, c'est une bonne idée de laisser 640 ici)
- --batch : taille du lot (dépend de la quantité de RAM dont vous disposez)
- --epochs : nombre de fois que l'on va répéter les étapes d'entrainements/évaluation, j'ai mis 60 pour tester si ça marche et 700 pour avoir un résultat décent
- --data : chemin du fichier yaml créé précédemment
- --weights : quelle taille de réseau on souhaite générer, voir cette page pour plus d'informations
- --cache : cache images sur la ram
Quand le programme a terminé, il va vous afficher ces lignes expliquant où est stocké le meilleur résultat obtenu et ces statistiques :

Le plus important ici est d'obtenir un mAP (mean Average Precision, la précision moyenne) le plus proche possible de 1. Le nombre après mAP représente le ratio de l'intersection des aires prédites et sélectionnées par vos soins, sur l'union de ces 2 aires. Par exemple, si elles correspondent exactement, ce nombre sera égal à 1, et si elles ne s'intersectent pas, c'est égal à 0. Ici, j'ai trouvé qu'obtenir un mAP de 99.5% pour un ratio de 50% (mAP@0.5=0.995) est suffisamment bon pour ce que j'essaie de faire.
Il est aussi possible d'obtenir ce message si le programme ne trouve pas de meilleurs résultats après 100 epochs :
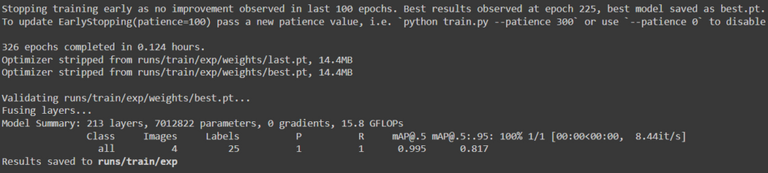
Vous pouvez aussi trouver des graphiques dans results.png sous runs/train/exp, pour ceux qui ont un fétiche sur les données tracées. On peut voir l'évolution de la précision et des erreurs :
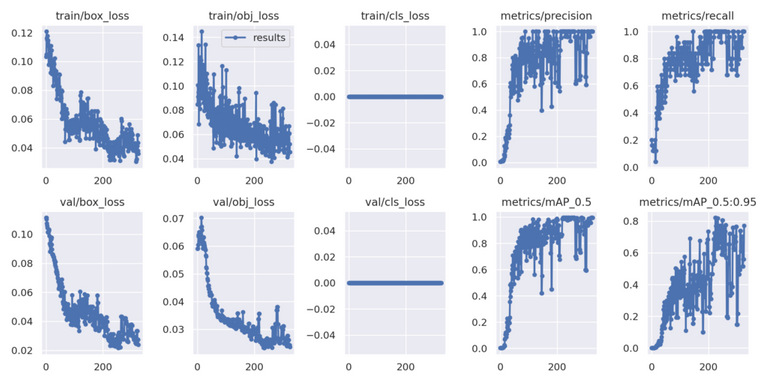
Le programme garde toujours en mémoire le meilleur résultat et le dernier dans le dossier runs/train/exp/weights.
L'importance de la taille du jeu de données
Ce qui m'a le plus refroidi à utiliser un réseau de neurone est la création de mon dataset. J'ai toujours vu les grands jeux de données comme ceux utilisés pour reconnaître les races de chiens et chats avec plus de 200 photos par races et je n'étais pas prêt à en créer autant. Mais je me suis dit que les caractéristiques simples de l'objet que je souhaite détecter (plutôt rond, arrière-plan clair, conditions plus ou moins contrôlées) devrait me permettre d'entrainer un réseau de neurone performant avec bien moins d'images. Mais je n'ai pas testé l'impact de la taille du dataset sur les résultats, donc allons-y :
Pour cet exemple, je vais utiliser ce fameux dataset comprenant des chiens et chats disponible ici : https://www.robots.ox.ac.uk/~vgg/data/pets/ (et ici pour avoir le format YOLO https://public.roboflow.com/object-detection/oxford-pets/1 )
Je ne vais utiliser qu'une seule race de chien, et j'ai choisi le Shiba Inu pour rester dans le thème de la blockchain. Il y a 200 images par race, j'ai créé un répertoire ici avec 2 jeux de données à 200 epochs :
- 1 grand dataset avec 73 images pour l'entrainement et 15 pour l'évaluation
- 1 petit dataset avec 21 images pour l'entrainement et 4 pour l'évaluation
Si vous voulez tester par vous-même la différence entre les 2 datasets, vous pouvez le faire ici :
https://colab.research.google.com/drive/1dpNYAnuAY6xdH02ooIkzuujiLSvO97Wo?usp=sharing
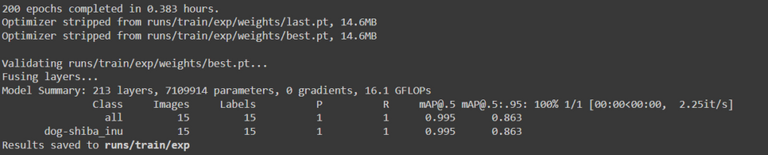
Voici les résultats à la fin de l'entrainement du grand dataset :
Et pour le plus petit (le temps d'entrainement est plus faible et la précision légèrement en dessous) :
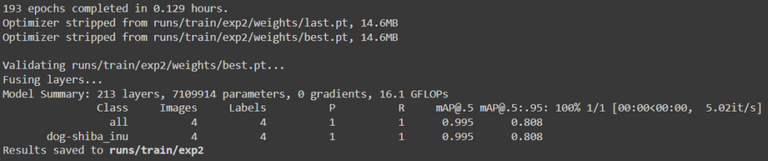
Mais lors du test des modèles, le petit modèle s'est avéré nettement moins bon, ne détectant pas la plupart des chiens, alors que le modèle entraîné avec le grand ensemble de données les a quasiment tous trouvé.
Donc oui, la taille du jeu de données est importante, mais elle dépend des caractéristiques des images avec lesquelles on travaille et des objets que l'on cherche à détecter. Dans l'environnement contrôlé que j'avais seules 20 images suffisent à créer un réseau de neurones correct, mais lorsque la complexité des objets et images augmente, le nombre d'images dans le jeu de données doit aussi augmenter.
Utiliser votre réseau de neurones :
Avec la prochaine commande, vous pouvez tester votre réseau de neurones sur n'importe quelle image (changez le nom du dossier exp pour correspondre à celui que vous vous voulez tester) :
python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.7 --source train_data/tests/0.png --hide-labels
Le résultat sera stocké dans runs/detect/exp (un nombre sera ajouté après le nom du dossier à chaque fois que vous utiliserez le programme). N'hésitez pas à jouer avec le seuil de confiance (--conf) entre 0 et 0.99 pour voir plus ou moins de boites. Voici quelques exemples :



Vous pouvez aussi faire des détections sur l'ensemble des images d'un dossier en spécifiant pas de fichiers de cette manière :
python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.7 --source train_data/tests/ --hide-labels
Vous pouvez vous arrêter ici ou vous pouvez regarder cet exemple si vous souhaitez utiliser votre modèle dans votre propre programme python. Vous avez seulement à changer le chemin du modèle (là où j'ai mis 'best500s') et le chemin de l'image :
# Example modifié de pytorch : https://pytorch.org/hub/ultralytics_yolov5/
import torch
# Model
model = torch.hub.load('yolov5','custom',path='best500s',source='local') # or yolov5m, yolov5l, yolov5x, custom
# Images
img = '0.png' # Chemin de l'image que vous voulez tester
# Inference
results = model(img)
# Results
results.show() # ou .show(), .save(), .crop(), .pandas(), etc.
print(results.pandas().xyxy)
La dernière ligne du programme vous permet de récupérer les coordonnées des boites trouvées, ce qui me permet de mesurer la taille des bulles.
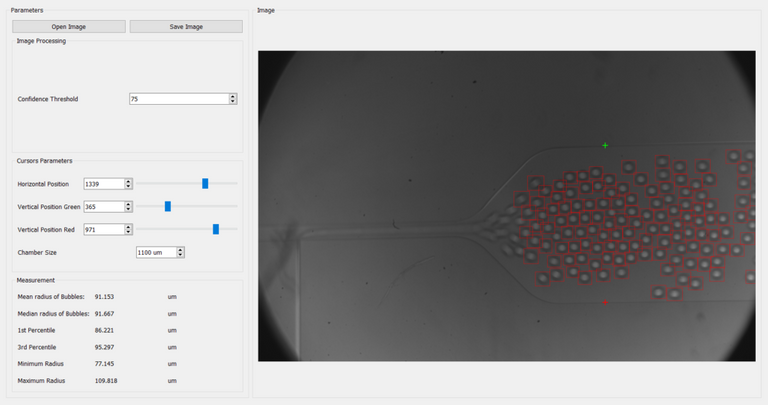
Vous pouvez inclure ces quelques lignes dans n'importe lequel de vos programmes, ici j'ai créé une interface graphique avec PyQt pour changer facilement l'image testée, sélectionner un intervalle de confiance et ajuster 2 curseurs pour obtenir une échelle de mesure, le programme affiche ensuite diverses statistiques sur les bulles trouvées :
Conclusion
Nous y sommes, maintenant vous savez comment entrainer et utiliser votre propre modèle YOLO. Nous avons aussi vu que vous n'avez pas forcément besoin de centaines d'images pour entrainer le modèle si vos images sont simples et que vous l'entrainez avec une grande diversité d'images et sur un nombre d'epochs plus grand.
Merci beaucoup de m'avoir lu jusqu'au bout !
Aller plus loin et Sources :
Toutes les images de bulles utilisées dans cet article, le sont avec l'autorisation du doctorant.
Cool de voir tes posts egalement en francais ! J'espere que tu auras le temps de continuer ! Je n'ai pas vraiment d'autres commentaires pertinents, mis a part ceux faits dans la VO ;)
Merci pour tes commentaires ! Je ne sais pas si je pourrais poster toutes les semaines, mais si j'arrive à augmenter ma moyenne de 3 par an, ça serait déjà pas mal :)
Tu es donc coureur de fond ! ;)
Merci pour ce post hyper passionant 👍 très intéressant de savoir que finalement le nombre d'image dépends énormément du contexte et qu'il peut être d'une valeur raisonnable rendant du coup l'expérience plus facile d'accès.
Merci beaucoup ! Oui ça rend la création du dataset moins effrayante dans certains cas ^^
Congratulations @robotics101! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 40 posts.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Check out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
Your content has been voted as a part of Encouragement program. Keep up the good work!
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more
The rewards earned on this comment will go directly to the person sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.