As promised earlier this week, I managed to dedicate some time to the release of a new episode of our citizen science project on Hive, that has been designed to take at most one hour of time (let’s restart gently). As I am also currently dealing with the preparation of my presentation at HiveFest, I take the opportunity to mention that all results obtained by the participants to the project will be included in the presentation, and therefore highlighted widely!
For the moment, the project focuses on the simulation of a signal typical of neutrino mass models at CERN’s Large Hadron Collider (the LHC). I recall that neutrinos are massless beasts in the Standard Model of particle physics, despite that they are experimentally known to be massive today. We must then rely on the presence of new particles to provide an origin to their masses.
These new particles yield specific signals at particle colliders, and our project plans to extend one of my previous studies that targets such a signal when it yields the production at the LHC of a pair of particles called (anti)muons. See also here for a Hive blog on that topic.
Within the context of our citizen science project, we will replace these muons/antimuons by electrons, positrons or even by a mixed pair including one muon and one electron or one antimuon and one positron.

[Credits: Original image from geralt (Pixabay)]
In the previous episode, we took as a reference my older publication, and we tried to reproduce the calculation of the production rate of the di-muon signal at the LHC. In addition, we also provided new results suitable for the third operation run of the LHC that started last July (at an unprecedented collision energy).
I was proud to see that a few Hive community members managed to do that, and were then the first people in the world to calculate total production rates at the LHC run 3 of what is called a double-beta process. Today, we continue focusing on the di-muon signal production rate, but we will this time take care of the uncertainties inherent to the calculation.
Episode 6 - Outline
In the rest of this blog, I first explain how precision can be achieved and why what we have done so far is not precise enough. Next, we will redo the calculations done during episode 5, but this time by also estimating the uncertainties on the predictions. In the upcoming episode 7, we will see how to obtain more precise results.
As usual, I begin this post with a recap of the previous episodes of our adventure, which should allow anyone motivated to join us and catch us up. A couple of hours by episode should be sufficient.
- Ep. 1 - Installation of the MG5aMC software allowing for simulations at particle colliders. We got seven reports from the participants (agreste, eniolw, gentleshaid, mengene, metabs, servelle and travelingmercies), among which that of @metabs consists of an excellent documentation on how to get started with a virtual machine running on Windows.
- Ep. 2 - Simulation of 10,000 LHC collisions leading to the production of a top-antitop pair. We got eight reports from the participants (agreste, eniolw, gentleshaid, isnochys, mengene, metabs, servelle and travelingmercies).
- Ep. 3 - Installation of MadAnalysis5, so that detector effects could be simulated, the output of complex simulations reconstructed, and the results analysed. We got seven contributions from the participants (agreste, eniolw, gentleshaid, isnochys, metabs, servelle and travelingmercies).
- Ep. 4 - Investigations of top-antitop production at CERN’s Large Hadron Collider. We got five contributions from the participants (agreste, eniolw, gentleshaid, servelle and travelingmercies). This episode included assignments whose solutions are available here.
- Ep. 5 - A signal of a neutrino mass models at the LHC. We got four reports from the participants (agreste, eniolw, travelingmercies (part 1) and travelingmercies (part 2)). This episode also included assignments, and their solutions are available here.
I cannot finalise this introduction without acknowledging all current and past participants in the project, as well as supporters from our community: @agmoore, @agreste, @aiovo, @alexanderalexis, @amestyj, @darlingtonoperez, @eniolw, @firstborn.pob, @gentleshaid, @gtg, @isnochys, @ivarbjorn, @linlove, @mengene, @mintrawa, @robotics101, @servelle, @travelingmercies and @yaziris. Please let me know if you want to be added or removed from this list.
Towards precision predictions at the LHC
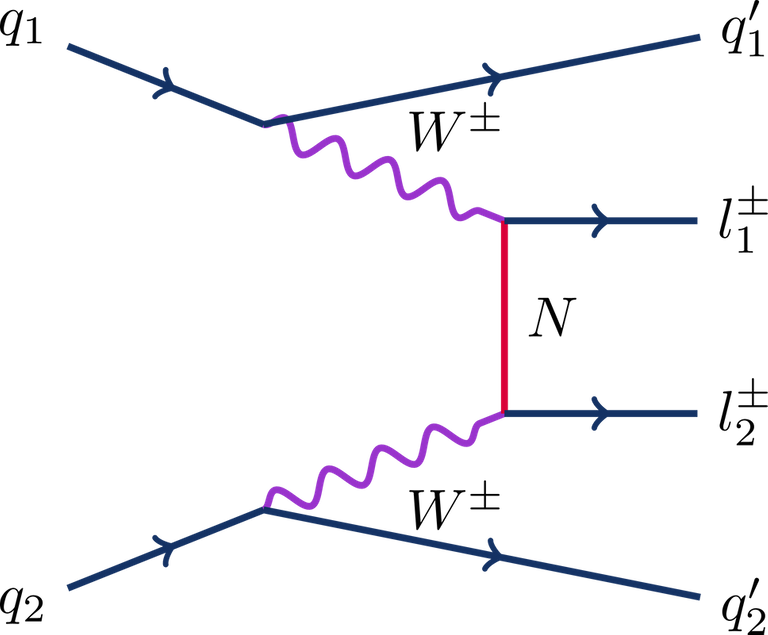
[Credits: CMS-EXO-21-003 (CMS @ CERN)]
The process considered is illustrated by the diagram above. Whereas protons are collided inside the LHC, at high energy they do not scatter as such. It is instead some of their constituents that scatter.
In the specific case of our signal, we must consider collisions between two quarks, one of them being provided by each of the colliding protons. For that reason, the initial state of the process (on the left of the figure) is represented by the symbols q1 and q2.
Then, these initial quarks each emit a very energetic W boson (purple in the figure) by virtue of the weak force, one of the three fundamental forces included in the Standard Model. The two W bosons finally proceed through the core process of interest: they exchange a heavy neutrino N (red in the figure), that is in our model the particle responsible for generating the masses of the neutrinos of the Standard Model.
Such an exchange leads to the production of two leptons of the same electric charge, represented by the symbols l1 and l2 on the right part of the figure. In my older study, we considered that these two leptons were either two muons, or two antimuons.
[Credits: CERN]
I have never mentioned it so far, but the calculation of the production rate associated with the above signal is a perturbative calculation. This means that the result can be written as an infinite series. The first term is the dominant one, and then come subleading corrections, subsubleading corrections, and so on.
Of course, we cannot calculate an infinite series term by term, and we need to truncate it at some point. This naturally leads to uncertainties due to missing higher-order terms. Obviously, the more terms we include, the smaller are the uncertainties (in a series, terms are expected to be smaller and smaller).
So far, we simply ignored all terms but the leading one, that is represented by the diagram that I have described above. This is called a leading-order calculation. After adding the second term of the series, we perform a next-to-leading-order calculation. It is not that easy to handle numerically, because we have to deal with infinities that cancel each other, which requires specific techniques that have been developed during the last decades. This will be addressed in episode 7.
In the following, we will make use of the MG5aMC software that we previously installed, and the heavyN neutrino mass model that we copied in the models directory of MG5aMC. For more information on those steps, please see episode 5.
A working directory for leading-order simulations
For now, I assume MG5aMC is ready to run, with the neutrino model files correctly installed. Let’s start the program as usual, by typing in a shell the following command, from the folder in which MG5aMC has been installed:
./bin/mg5_aMC
Then, we proceed similarly to what we have done for episode 5, and we generate a working directory with a Fortran code dedicated to the signal considered. We must type, within the MG5aMC command line interface:
MG5_aMC>import model SM_HeavyN_NLO MG5_aMC>define p = g u c d s u~ c~ d~ s~ MG5_aMC>define j = p MG5_aMC>generate p p > mu+ mu+ j j QED=4 QCD=0 $$ w+ w- / n2 n3 MG5_aMC>add process p p > mu- mu- j j QED=4 QCD=0 $$ w+ w- / n2 n3 MG5_aMC>output episode6_lo
In the set of commands above, we first import the model (line 1), then we define the proton content (lines 2 and 3): a proton is made of up, down, strange, charm quarks and antiquarks, and of gluons. Lines 4 and 5 describe the process itself, which we can map to the diagram previously introduced: two initial protons p (containing each quarks and gluons) scatter to produce two final jets j (coming from the emission of the W bosons), and two final muons mu- (line 4) or antimuons mu+ (line 5). The last command generates the working directory itself.
For more details, please consider reading again what I wrote for episode 5.
A leading-order run
Next, we are ready to recalculate the leading-order rate associated with our signal. The calculation will be similar to that performed for episode 5, except that this time the uncertainties inherent to the calculation will be estimated. As in the previous episode, the calculation can be started by typing in the MG5aMC interpreter
MG5_aMC>launch
We can then run the code with its default configuration, which is achieved by typing 0 followed by enter (or simply by directly pressing enter) as an answer to the first request of MG5aMC.
Neutrino scenario - parameters
Next, we will have to tune the parameters of the neutrino model file so that it matches a benchmark scenario of interest. This is a scenario in which a heavy neutrino N interacts with muons and antimuons. This is done by pressing 1 followed by enter as an answer to the second question raised by MG5aMC. We must then implement two modifications to the file.
- Line 18 controls the mass of the heavy neutrino. Such a neutrino is identified through the code
9900012and we first set its mass to 1000 GeV (1 GeV is equal to the proton mass). Line 18 should thus read, after it has been modified:9900012 1.000000e+03 # mN1
- Lines 48-56 allow us to control the strength of the couplings of the heavy neutrino with the Standard Model electron, muon and tau. There are nine entries, and we must turn off 8 of them (by setting them to 0), so that only the heavy neutrino coupling to muons is active (and thus set to 1). This gives:
Block numixing 1 0.000000e+00 # VeN1 2 0.000000e+00 # VeN2 3 0.000000e+00 # VeN3 4 1.000000e+00 # VmuN1 5 0.000000e+00 # VmuN2 6 0.000000e+00 # VmuN3 7 0.000000e+00 # VtaN1 8 0.000000e+00 # VtaN2 9 0.000000e+00 # VtaN3
:wq in the VI editor).
Calculation setup
In a second step, we type 2, followed by enter, to edit of the run card.
- We first go to lines 35-36 and set the energy of the colliding beams to 6800 GeV. This is what corresponds to the LHC Run 3.
6800.0 = ebeam1 ! beam 1 total energy in GeV 6800.0 = ebeam2 ! beam 2 total energy in GeV - Next, we modify lines 42-43 to set the ‘PDFs’ relevant to our calculation (which indicates how to relate a proton to its constituents). We choose to use
lhapdf, with the PDF set number262000:lhapdf = pdlabel ! PDF set 262000 = lhaid ! if pdlabel=lhapdf, this is the lhapdf number - On line 96, we replace
10.0 = ptlby0.0 = ptl. We do not want to impose any selection on the final-state muons.
We then save the file (:wq) and start the run (by pressing enter).
Results
If everything goes well, we should obtain a cross section of 0.0138 pb in a few minutes, with information on two types of uncertainties.
- Scale variations: +10.8% -9.02%
- PDF variations: +5.73% -5.73%
Assignment
Leading-order rate dependence on the neutrino mass
Leading-order rate dependence on the neutrino mass
Let’s now repeat the exercise above, but for heavy neutrino masses varying from 50 GeV to 20,000 GeV. After getting enough points, we should generate a plot with the heavy neutrino mass being given on the X axis, and the value of the cross section on the Y axis. Of course, the plot should include error bars as we now have information on them.
In practice, we re-launch the code (by typing launch again), and modify the mass of the heavy neutrino in the param card (line 18). We could perform a scan by setting it to
9900012 scan:[100,5000,20000] # mn1This would perform the calculation three times, the heavy neutrino mass being respectively taken to be 100 GeV, 5,000 GeV and 20,000 GeV. Of course, more than three points should be considered to get a smooth curve.
Summary: uncertainties and production rates at the LHC
In this sixth episode of our citizen science project on Hive, we focused on an LHC signal relevant for a neutrino mass model. We have redone the calculation achieved in episode 5, but this time by including the uncertainties inherent to the perturbative nature of the calculation.
The present episode includes one assignment that should take about an hour to be performed. We want to study the dependence of the neutrino mass signal rate on the neutrino mass, together with the variation of the related uncertainties.
I am looking forward to reading the reports of all interested participants. The #citizenscience tag is waiting for you all (and don’t forget to tag me)! In the next episode, we will re-do that calculation again, but after including subleading corrections to the predictions. We will see that we will get a slightly larger results, but much more precise.
Good luck and have a nice end of the week!
~~~ embed:1567923279201173504 twitter metadata:YWdyZXN0ZTA1MDUzNjE0fHxodHRwczovL3R3aXR0ZXIuY29tL2FncmVzdGUwNTA1MzYxNC9zdGF0dXMvMTU2NzkyMzI3OTIwMTE3MzUwNHw= ~~~
The rewards earned on this comment will go directly to the people( @lemouth, @agreste ) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
Well, I have work to do! Hopefully I can get on over the weekend (the grass will have to wait a little longer for me to mow). Cheers!
Ahaha! Glad to read that the project wins the competition against your grass. My garden is in a bad state too, but it is raining too much at the moment, so that mowing will wait ;)
As a side note, this episode should be quicker than the previous one. Please let me know how long it will take to you.
Cheers!
You were right about this week's tasks, everything went smoothly as if I was doing an extension of the tasks of previous episode. I was able to get these results for the mass (1000 GeV) of the heavy neutrino considered:
The run time for the scan (I used the same points from episode 5) took longer than the previous simulation. Here's the plot I got from the masses considered:
I'd be able to write my progress report tomorrow, as I am done with the simulations already. Just a question, I checked our reference paper regarding the reporting of the scale and PDF variations. Do the values on the third and fourth columns in the table correspond to the addition in quadrature of the scale and PDF variations, respectively?
Glad to read that you are already done. Will you be faster than @agreste this time? And what about @eniolw and @gentleshaid? Please tell us where you all stand!
Note that the error bars are missing. You may need to upgrade your python script ;)
In the paper, we quoted them separately. The third column corresponds to scale variation uncertainties, and the fourth one to PDF uncertainties. In the figure, only scale uncertainties are accounted for. However, we must be careful that predictions in the article correspond to next-to-leading order ones (NLO), which is precisely what we will do in the next episode, and compare them to the leading order ones (LO) that we dealt with this week.
I recall that LO and NLO refer to where we truncate the perturbative series mentioned in the blog (LO = first term; NLO = second term).
Cheers!
Again, @agreste was faster! 👏🏻 I was a bit tired yesterday from work and classes (I enrolled this semester haha 😅) that I had to delay the writing for a day. I am not sure if I got the values for the error bars correctly, I manually recorded the error from the log of the terminal during the scan. I checked @agreste's for comparison and I noticed that the values I got are really small or is it expected?
I almost forgot about it!
This confused me a little, is this figure the table I got from your paper?
I noticed this. I have open both posts in my browser, and I will review them while in the train to Amsterdam tomorrow (or maybe tonight although there is little chance, as I don't have much time). I will check out what you did for the error bars and comment on this.
Normally, you should get errors that vary depending on the heavy neutrino mass, and in the ball park of 10%. Much smaller errors are expected when moving to NLO, as we will see in the next episode.
The numbers in the table can be extracted from the figure (in fact we did the opposite: we started from a much bigger table and made the figure).
I have already done the calculations. I have to start writing the report. Maybe it will be ready today, depending on how complicated my work day is going to be.
I am pleased to read this, and I am looking forward for the results. Unfortunately, it will be too late to grab something to show at HiveFest. However, I have taken what you achieved in the previous episode. This will be shown! ^^
Thank you! And best of luck at the HiveFest!
You are welcome!
Hi! Thanks for the reminder. I will do my report in due time. I'm pretty busy.
Great! I am looking forward to read it! Note that I can help if needed ^^
Science projects are not easy because they have to focus on what we want to do so that the results are maximized
That's true. However, here I have a very good idea about what to do, so that we do not plan to explore without guidance. We don't know exactly what will be the results, but we know that what will be found will be useful to advance knowledge.
Cheers!
Good to see citizen science moving towards!! I am anxious to see the next reports from the community!

!1UP
I am similarly very excited to read them, and somewhat impatient. However, I am afraid that both you and I will have to wait a bit for these reports. Anyway, I will track the #citizienscience tag.
This reminds me that there is a post from @travelingmercies that I didn't comment yet, as it was published right when I left for vacation. I will do it right now!
Excellent. That's a great job well done. Thanks for sharing sir. There was a lot to learn and I eagerly look forward to the next episodes.
You can also plan to participate to the project, if you have some time and are interested. Everyone can join, at any time. It is sufficient to go back to episode 1, and follow the menu provided in the second section of this blog.
Cheers!
Yes I am interested in the project. Let me go through the previous episodes from episode 1. So I can bring myself up to speed to the current stage. Thank you Sir.
Great! I was so happy to read your reply this morning! Thank you :)
I am thus looking forward to read your reports. Don't hesitate to write a report after each of the proposed episode (even if it is a partial one), so that I could follow your progress and answer any question or comment and clarify any doubt you may have.
Cheers!
OK. Sure I will. Many thanks Sir
Greetings dear @lemouth, the progress they have had in the project is evident with the summary you made, new challenges are coming for the participants, which I am sure they will be able to meet and have new learning.
I will be on the lookout for the next installment brother, have an excellent week.
Thanks for passing by!
I am also sure that the participants will manage to handle all proposed exercises during the course of the project. In addition, I truly hope to see 2023 as the year where the work done by Hive community members will converge onto a citizen science article to be submitted for peer-review. Let's see whether (and when) we get there!
Cheers!
Detecting Neutrino is not an easy task bro and they are also electrically neutral in nature, they are close to zero, but its existence in an atom is evident. Are you calculating the amount of tau particles as well?
In the framework of a collision at a particle collider, we make use of energy conservation to deduce the presence of neutrinos (and of any other invisible particle). This is achieved from an energy imbalance between the initial and the final state. Energy is conserved, so that if the energy of the initial state and that of the final state are different, then something invisible like a neutrino must carry energy away.
In the context of the present project, there is no final-state neutrino. We aim to grasp information on the model through one of its fully visible signatures ((heavy) neutrinos only appear as intermediate particles).
We could (and we should). However, there is for now not enough participants to the project to consider that signal too. It is only a matter of resources, as you can see... Maybe as a follow up... who knows?
Got it my friend, I guess you have also collected muon radiation profiles that comes out of the collider boundaries, I mean for safety even though you are doing it on a simulator no harm but in reality.
I understand resources for such projects often depends on tools and funds and satisfying the funding agencies for its utility.
Keep it up mate, you are on roll.
All safety tests have been made at the level of the LHC. There is a lot of documentation on this matter online (checkout CERN's website). Here, the idea is to trigger interest of experimenters to start a new analysis at an existing machine, and with existing data (so that if they got excited by the results, this can be started straight away).
Exactly. Although here, since we are running fully on Hive and with non-particle-physics actors, it is only a matter of human resources and not of money. Of course, I could do the exercise together with a student or a postdoctoral fellow. However, I have no one with enough free time in my group, so that we end up again at the problem of funding...
Cheers, and thanks for the chat :)
Thank you for sharing this valuable information to us. Best of luck
You are very welcome. According to the success with the previous episodes, I am sure this one will be a success too! :)
So happy to see this back on again! Once again welcome back, @lemouth.
Thank you! Your message is very appreciated :)
Best wishes for your project, hope you do well and be successful
Thanks a lot. For the moment, everything moves nicely and at a good pace. Let's see for the next steps :)
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
You have received a 1UP from @gwajnberg!
@stem-curator, @vyb-curator, @pob-curator, @neoxag-curator
And they will bring !PIZZA 🍕.
Learn more about our delegation service to earn daily rewards. Join the Cartel on Discord.
Congratulations @lemouth! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 200000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Congratulations @lemouth! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badge:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
!PIZZA
!PGM
!LUV
!BEER
PIZZA Holders sent $PIZZA tips in this post's comments:
@lespipirisnais(4/15) tipped @lemouth (x1)
Join us in Discord!
You seem to have decided to ignore, without any justification (if there are some, please show them), hundreds of year of data (experimental measurements, i.e. facts), the underlying theory predicting them (that has not been falsified so far), and numerous applications in our every day life (including current communication means, computers, etc.). Well, I don't know what to really say here. It is your choice. Fine.
PS: mass is different from weight (mass is constant, weight can change), and things can exist without taking space (for instance: light).
Light is also a particle (photon). This is an experimental fact very well understood theoretically. This was demonstrated in the beginning of the 20th century, with the development of quantum mechanics.
"Theory" has a very well defined meaning in science, and it is not what you wrote.
In addition, one of the core ideas in quantum mechanics (how can it be a lie when a huge fraction of the world economy relies on its properties?) is the duality between waves and particles. See my other reply and check out the double-slit experiment. This is the proof.
Sorry but I cannot. You have not backed up any of your claims, and you simply mentioned that everything we have learned during the last 300 years consisted of lies (despite tons of experiments and applications). This is not how science works. We have experiments, data, and people (remark: not only people).
You cannot throw away previous knowledge without a reason. If you want to replace the currently admitted paradigm by something else, the something else should at least explain all observations made so far as much as the currently admitted idea. Without this, we don't gain, but we lose understanding, This is how novel ideas emerge.
Both. We have experimental data, measurements or facts. Then you have a theoretical framework that can be used to derive predictions for the observations in the past, current and future experiments. This theory can of course be falsified (that's part of the definition of a theory).
So far, the Standard Model of particle physics has not been falsified. It is therefore the currently admitted paradigm. Throwing away theory and data without a good reason makes no sense. Claiming they consist of a 300-year conspiracy also requires a proof, that has not been presented.
I was "not told anything". I analysed the findings and developments of the last hundreds years, and learned from there, taking as proofs what were proofs. Ignoring them would just be fooling ourselves...
You can check out any textbook or online lecture on quantum mechanics. The double slit experiment may be the right place to begin with. You may even start with the wikipedia page and the references therein. It is very well explained.