In a vector database, each piece of data is represented as a vector of numbers, where each number corresponds to a specific feature or attribute of the data. The dimensions of the vector depend on the specific features being used to represent the data.
For example, in a text database, the vector might have dimensions corresponding to the frequency of each word in the vocabulary, the part of speech (noun, verb, adjective, etc.) of each word, and the sentiment (positive, negative, neutral) of each word. The resulting vector might look something like this:
The goal of similarity search is to find the most similar vectors to a given query vector, which is the vector representing the data the user is searching for. There are several algorithms that can be used for similarity search, each with its own strengths and weaknesses.
The inner product space algorithm calculates the dOT product of the query vector and each vector in the database to find the most similar vectors. The dot product is a measure of the similarity between two vectors, and it can be calculated using the following formula:
dot product = sum(a_i * b_i)
where a_i and b_i are the i-th elements of the two vectors.
The inner product space algorithm works by calculating the dot product of the query vector and each vector in the database, and then sorting the results by the dot product. The most similar vectors are the ones with the highest dot product.
The cosine similarity algorithm calculates the cosine of the angle between the query vector and each vector in the database to find the most similar vectors. The cosine similarity is a measure of the angle between two vectors, and it can be calculated using the following formula:
cosine similarity = dot product / (|a| * |b|)
where |a| and |b| are the magnitudes of the two vectors.
The cosine similarity algorithm works by calculating the dot product of the query vector and each vector in the database, and then normalizing the result by the magnitudes of the vectors. The most similar vectors are the ones with the highest cosine similarity.
The annular distance algorithm calculates the distance between the query vector and each vector in the database, using the annular distance metric. The annular distance is a measure of the distance between two vectors, and it can be calculated using the following formula:
where ||a - b|| is the Euclidean distance between the two vectors, and ||a|| and ||b|| are the magnitudes of the two vectors.
The annular distance algorithm works by calculating the Euclidean distance between the query vector and each vector in the database, and then adding the product of the magnitudes of the vectors. The most similar vectors are the ones with the smallest annular distance.
Clustering is a technique for grouping similar vectors together into clusters. There are several clustering algorithms that can be used for this purpose, including:
K-Means clustering: This algorithm works by initializing a set of centroids, and then iteratively updating the centroids and assigning each vector to the closest centroid.
Hierarchical clustering: This algorithm works by building a hierarchy of clusters, starting from individual vectors and merging clusters until a desired level of granularity is reached.
DBSCAN clustering: This algorithm works by selecting a set of "core" points, and then expanding a ball around each core point to find other points that are within a certain distance.
Vector databases have many applications, including:
Information retrieval: Vector databases can be used to retrieve documents that are similar to a given query.
Recommendation systems: Vector databases can be used to recommend products or services to users based on their past behavior and preferences.
Natural language processing: Vector databases can be used to analyze the meaning of text and perform tasks such as sentiment analysis and named entity recognition.
computer vision: Vector databases can be used to analyze images and perform tasks such as object recognition and facial recognition.
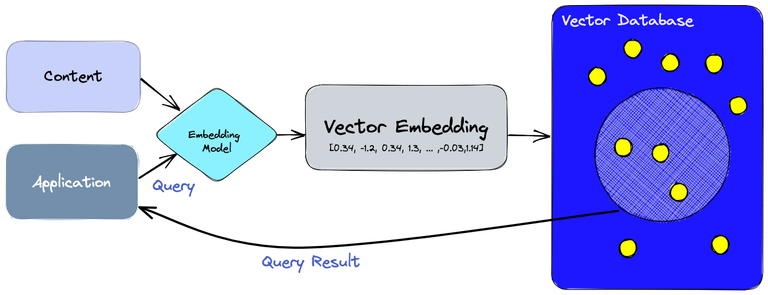
Vector Representation
In a vector database, each piece of data is represented as a vector of numbers, where each number corresponds to a specific feature or attribute of the data. The dimensions of the vector depend on the specific features being used to represent the data.
For example, in a text database, the vector might have dimensions corresponding to the frequency of each word in the vocabulary, the part of speech (noun, verb, adjective, etc.) of each word, and the sentiment (positive, negative, neutral) of each word. The resulting vector might look something like this:
[0.2, 0.1, 0.05, 0.01, 0.8, 0.3, 0.1, 0.2, 0.1, 0.05]This vector represents the text document, with each number corresponding to the frequency of a specific word or feature.
Similarity Search
The goal of similarity search is to find the most similar vectors to a given query vector, which is the vector representing the data the user is searching for. There are several algorithms that can be used for similarity search, each with its own strengths and weaknesses.
Inner Product Space (IPS)
The inner product space algorithm calculates the dOT product of the query vector and each vector in the database to find the most similar vectors. The dot product is a measure of the similarity between two vectors, and it can be calculated using the following formula:
dot product = sum(a_i * b_i)where
a_iandb_iare thei-th elements of the two vectors.The inner product space algorithm works by calculating the dot product of the query vector and each vector in the database, and then sorting the results by the dot product. The most similar vectors are the ones with the highest dot product.
Cosine Similarity
The cosine similarity algorithm calculates the cosine of the angle between the query vector and each vector in the database to find the most similar vectors. The cosine similarity is a measure of the angle between two vectors, and it can be calculated using the following formula:
cosine similarity = dot product / (|a| * |b|)where
|a|and|b|are the magnitudes of the two vectors.The cosine similarity algorithm works by calculating the dot product of the query vector and each vector in the database, and then normalizing the result by the magnitudes of the vectors. The most similar vectors are the ones with the highest cosine similarity.
Annular Distance
The annular distance algorithm calculates the distance between the query vector and each vector in the database, using the annular distance metric. The annular distance is a measure of the distance between two vectors, and it can be calculated using the following formula:
annular distance = sqrt(||a - b||^2 + ||a||^2 * ||b||^2)where
||a - b||is the Euclidean distance between the two vectors, and||a||and||b||are the magnitudes of the two vectors.The annular distance algorithm works by calculating the Euclidean distance between the query vector and each vector in the database, and then adding the product of the magnitudes of the vectors. The most similar vectors are the ones with the smallest annular distance.
Clustering
Clustering is a technique for grouping similar vectors together into clusters. There are several clustering algorithms that can be used for this purpose, including:
Applications
Vector databases have many applications, including:
Popular Vector Database Libraries
Some popular vector database libraries include:
These libraries provide a range of features and algorithms for similarity search and clustering, and can be used in a variety of applications.