In this post I'll be breaking down how I was able to create an application that interacts with the Hive blockchain using an LLM (ChatGPT in this particular case). The intention with the post is to bring attention to some of the possibilities currently at our feet, by showing a very specific step-by-step approach to problem-solving using AI. Hopefully you'll get some ideas of your own, or at the very least get an interesting read out of it.
Background: Summaries, summaries, summaries
You may have noticed some of my Threads lately, about the summaries for various podcasts being out. The idea was born a little more than a month ago, after an interaction with @coyotelation, where he pointed out how he as a non-english speaker had big problems following along with the ongoing Lion's Den episode. Even though he really wanted to take part in the discussion and gain access to the information, his possibilities were limited because of the language barrier.
This sparked the idea: What if I could somehow transcribe the episode and then feed that to an LLM to generate a summary of the episode? This would solve @coyotelation's (and surely many other's) problem, but it would also do a lot more than that: It would make valuable Hive-content previously only available in audiovisual format, indexable by Search engines, not to mention LeoAI, LeoSearch and other search engines specialized on indexing Hive content.
And sure enough, with a bit of research I figured out how I could download the recordings and run them through ASR (Automated Speech Recognition) software that it turned out I could run on my own system. Quite resource intensive, but still. It worked! The software is called Whisper AI, and it takes my computer only about 15 minutes to transcribe near flawlessly a 2 hour video/audio recording. I should probably mention, though, that it's a quite powerful computer with a quite powerful graphics card as well.
With the first few transcriptions created, I needed to craft a prompt that would consistently generate good summaries. After hours of experimentation I landed on something that was somewhat consistent. It still needs manual supervision and input, but it's close enough. Here's the full prompt if you're interested:
Your role is to analyze and summarize transcripts of Twitter Spaces live podcasts uploaded as .srt files. You will provide a detailed analysis of the entire transcript, crafting a comprehensive breakdown that includes:
1. A brief summary/abstract of the episode.
2. A bullet point list of the main topics discussed, with emphasis on the specifics, such as project names and key concepts.
3. A detailed article on each topic, elaborating on what speakers said, with a focus on specifics rather than a high-level overview, including discussions and names of specific projects mentioned during the episode.
You should aim to present the information clearly and concisely, ensuring that the target audience, who could not attend or listen to the recording, gains a thorough understanding of the episode. Your responses should be tailored to provide insights and detailed accounts of the discussions, making the content accessible and informative.
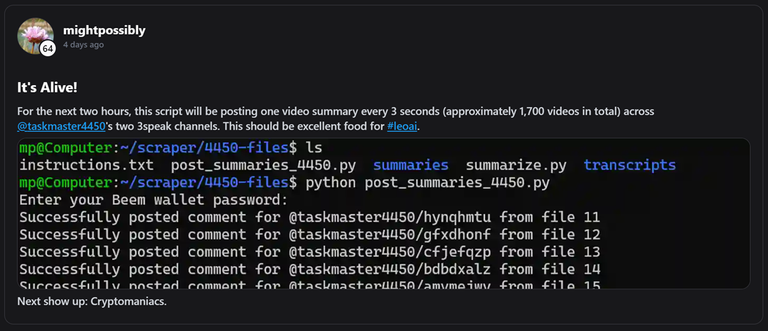
No less than 27 podcast summaries has been posted to the @ai-summaries account since the project commenced a little over a month ago (noone can claim that Hive doesn't have an active podcasting community!).
Anyways, on to today's use-case...
Summarizing a large amount of 3Speak videos
After a few weeks of posting summaries, @taskmaster4450 approached me and asked whether it would be possible to somehow summarize his more than 2500 videos for the purpose of adding their data to the Hive Database thus making their contents available to LeoAI.
Up until then, the summarization process was both manual and quite laborious for me, and my immediate thought was: Forget it, no way, that's simply not viable. I have no coding experience nor coding competence and this is simply unachievable with my current competence level.
But then I started thinking. Which specific steps would be required to actually accomplish this? And could I perhaps accomplish at least some of it with the help of AI? I tried breaking down the imagined necessay steps and came up with this*:
- Scrape a list of aLL the videos in the channel including their unique identifiers (hive permlinks)
- Automatically download the videos in the list
- Run ASR on each video, outputting 1 transcript per video
- Run each transcript through ChatGPT using a pre-defined prompt to summarize the transcript, outputting 1 summary per transcript
- Post each summary to its corresponding video as a comment
*Actually, I initially only came up with the first two steps, doubting I would even accomplish those. More on the specifics on the process below.
Problem 1: Generate a list of the channel videos
Prompt:
I have an Ubuntu WSL environment set up already, and node-js is all set up and ready to go, along with python3. I need help writing a script that will scrape the entire 3speak.tv channel "https://3speak.tv/user/taskmaster4450" and list each video that has been posted to that account. The script will output a csv file that lists each video in reverse chronological order in the format video_url,video_name. An example of a specific video URL in the channel is
Output:
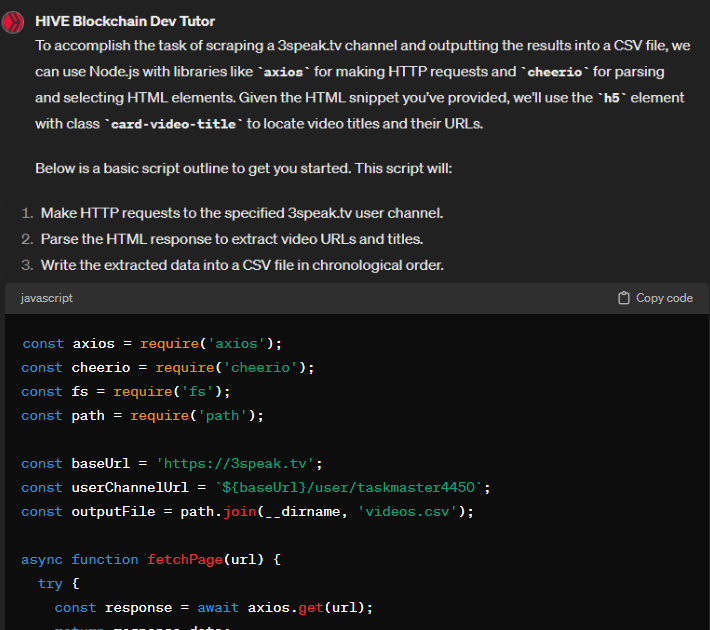
I tried running the script* and to my surprise I was left with a shiny csv-file containing all the videos in the channel in chronological order, like so:

*I actually didn't know how to run the script, so I prompted for that as well. "How do I run a nodejs-script"
But then I realized I'm gonna need the video identifier isolated as well, which is the Hive permlink, so I asked for some adjustments:
Great. Let's build further on this. I need the outputted csv file adjusted. There must be an additional column: Before the two current columns (video_url,video_name) i need to isolate the unique video identifier part of the URL. So if we use the initial example, the first row (let's call it video_id) would simply display 'jbonizwn'
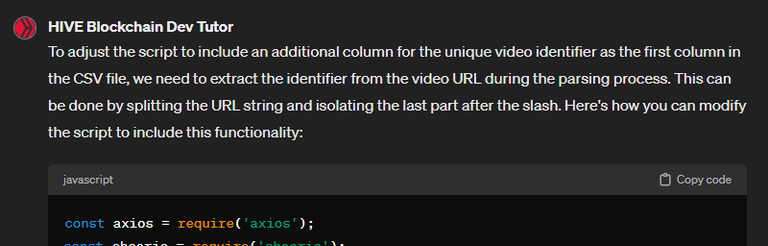
And then I realized I didn't really need the full URL of the video at all, only the identifier:
this worked perfectly. And nOW that I think of it, I don't need the CSV to even display the video_url, I only need the video_id and the title. Rewrite the whole script to accomodate for this
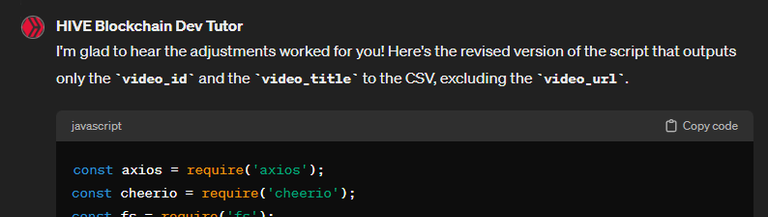
And here's an excerpt of its final output:

Problem 1 solved. On to..
Problem 2: Auto-download the videos
From my initial manual summarizing, I was already familiar with the command tool yt-dlp, which I've used to download the Twitter/X-recordings to transcribe them. But up until this point, I'd done them one recording at a time. To be able to handle thousands of videos, I needed to automate the process. But first things first, how do I properly name the videos to dynamically be named after the links they were fetched from?
Prompt:
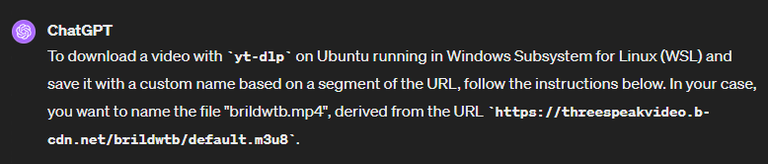
using yt-dlp on Ubuntu WSL, how can I download the video on the following URL and save the video file named after the code between the two /'s, i.e. in this example "brildwtb.mp4".
https://threespeakvideo.b-cdn.net/brildwtb/default.m3u8
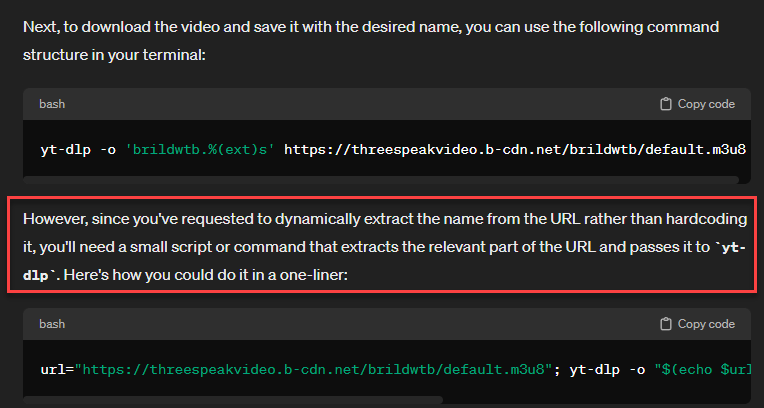
Say I have a list of 100 such URLs. How could I feed this list into the script to download them all in one operation?
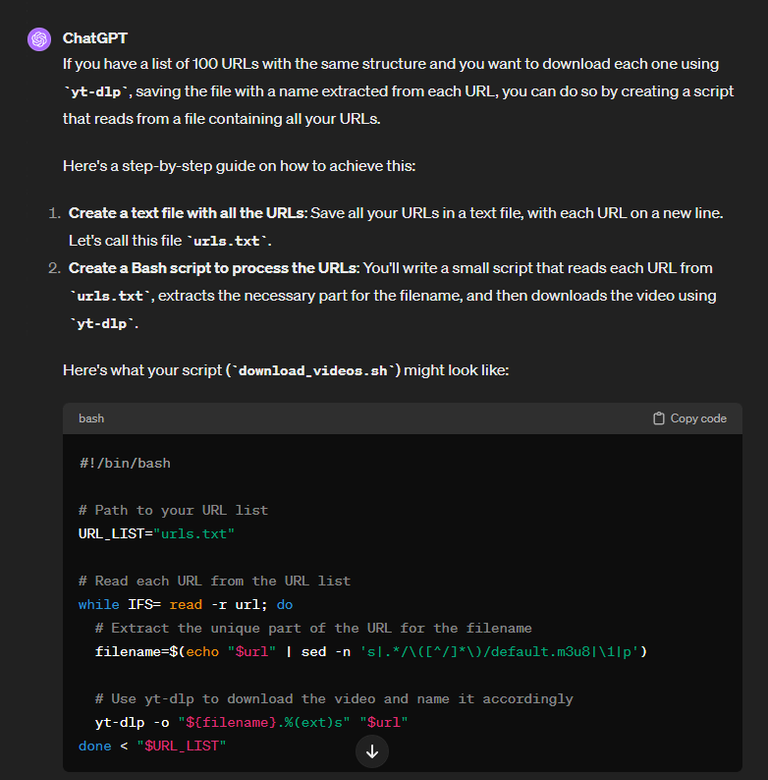
At this point I realized it would probably be a good idea to number the videos too, so it would be easy for me to resume downloading in case the script would halt for some reason.
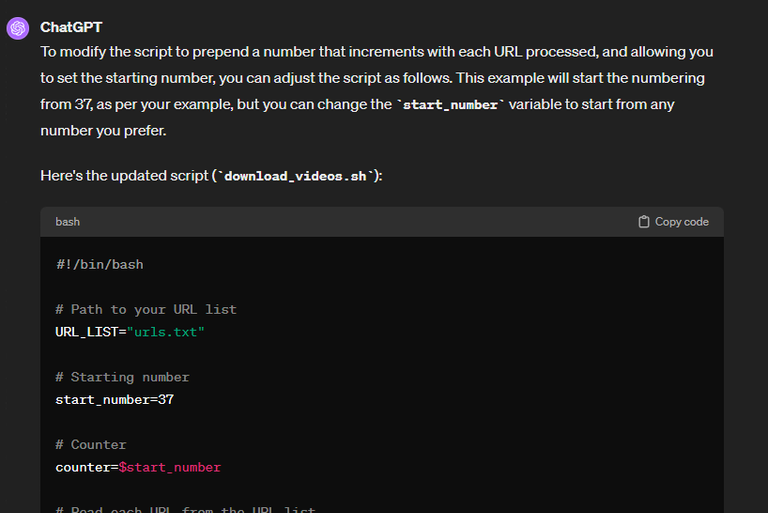
I forgot I also need the output video to be prepended with a number and a dash. The number will increase by 1 for each line, but I need to be able to set in the script which number it should start counting from. So if we use our initial example and say that that example is the first line in urls.txt, and I select that the number it should start counting from is 37, our file output would be "37-brildwtb.mp4"
And just like that, problem 2 was solved as well, resulting in a massive folder looking somewhat like this:
Problem 3: Transcribe the videos with minimal manual input
This one turned out to be real simple. I already knew the command to transcribe a video from before, and I already got whisper set up on my computer. I just needed to run the command on all the files in a single folder. note that the command 'more' is just a simple placeholder for the correct command, which would be something like whisper videofilename.mp4 --model medium --language en --output_format srt
Prompt:
On my Windows computer, I have a folder containing a number of files. Using the CMD cli interface, I'd like help creating a single command that will run a specific command on each file in the folder that ends with .txt The command that should be run is "more"

Running this command on all the files is a different story though. It took my computer approximately 24 hours of continuous work to transcribe all 1700 videos.
Problem 4: Generate summaries based on the transcripts
This was the problem I was most "afraid" of tackling, and is also the step I probably spent the most time on. I had some big problems getting GPT to cooperate with me. My intial prompt was something like "I need to interact with the OpenAi API to automatically summarize based on a set of text files". But because GPT-4 is trained on data only as recent as 2021, it served me code using deprecated API calls, and I simply could not get it to work with the updated calls as per the documentation.
The solution turned out to be prompting from a completely different frame of reference: Instead of "I need to interact with the OpenAI API", I approached it from "I need help developing this script based on the following function". After which I proceeded to paste in the correct API call from the OpenAI Documentation. To my surprise, this worked almost flawlessly. But enough background, let's dive on in:
Prompt:
I need help with refining a python script

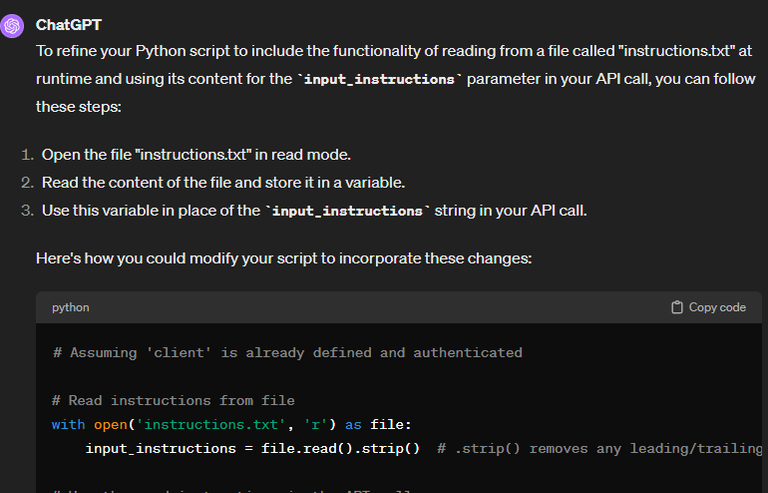
And what do you know, it worked perfectly. But that hard part was still to come. Note how I'm very particular about describing exactly what I need the script to do.
Excellent, that worked perfectly. Let's continue.
In the folder where the script will run, there are two subfolders: "transcripts" and "summaries". The 'transcripts' folder contains an undefined number of .srt files with unique names and contents.
The script will look for files in the transcripts folder and run the response function once for each file found. These files will also serve as the input_transcript-variable that will update each time the function is run.
For each file in the transcripts folder, the output of the response function will create a .txt file in the "summaries" folder with an identical name (with the exception of the file extension), containing the output of the function
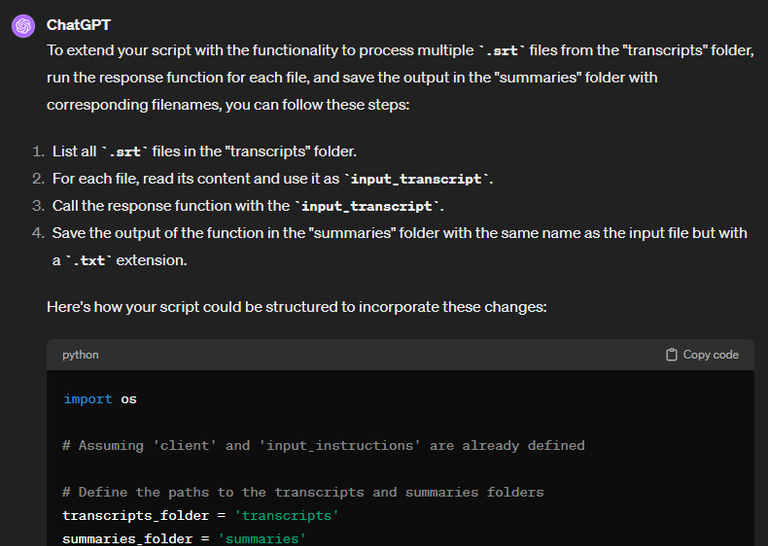
Also this script worked exactly as intended. There were a few prerequisites I haven't mentioned, namely needing a paid OpenAI developer account with API access tokens to be allowed to do the API calls. I'll note though, that for running the summaries on said 1700 transcripts, it only cost me like 5 USD, which was a surprisingly low sum according to my expectations.
It took about 3-4 hours for the script to complete all the summaries.
Step 5: Posting the summaries to the blockchain
With a folder full of summaries, all that NOW remained was posting said summaries to their corresponding videos. I wanted them to be posted as comments rather than individual posts. It was also an important point for me to decline payout on the comments to stay in tune with the stated project goals.
Prompt:
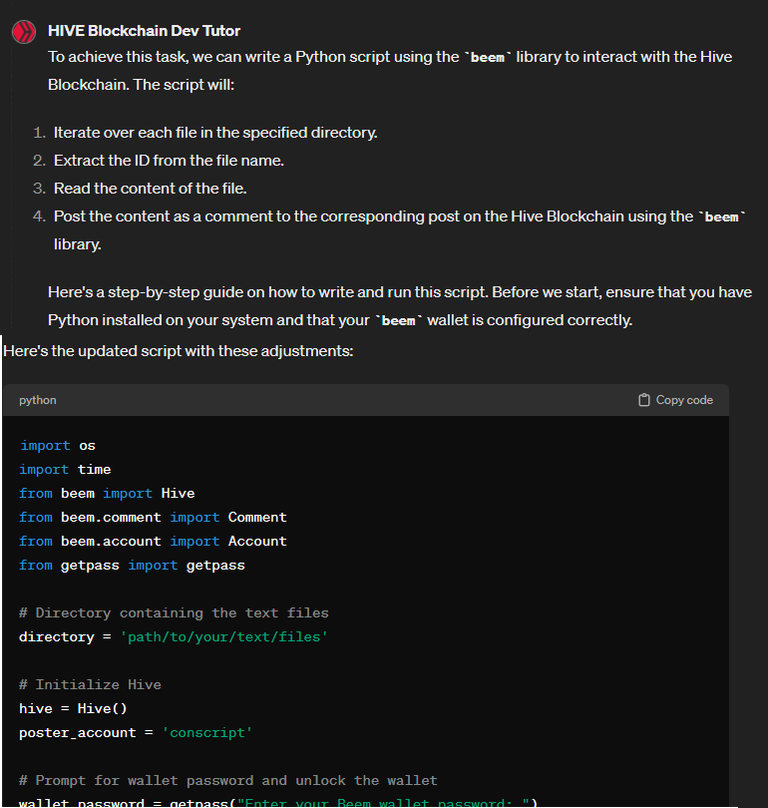
I had a few back and forths on this one, but eventually I got it working. Which is when I posted this thread:
https://inleo.io/threads/view/mightpossibly/re-leothreads-ws2kqgt7
The script took about 2,5 hours to successfully post all the summaries to their corresponding videos. If you want to see some of the resulting summaries, check the comment section of the thread above (I dropped some links in there).
closing remarks
If you made it all the way down here, you've probably realized I've left out a bunch of details, as this is not a tutorial for how to achieve this particular thing, but rather how AI can be used to solve problems like this. By breaking it down to simple steps, it makes it possible to actually get the program doing what you want it to do – which is what this whole article is intended to show.
If you're a coder, you're probably tearing your hair out seeing this cumbersome process play out by such an amateur. And if you're a non-coder like me, you probably think this looks like pure magic... or at least somewhere in between.
I have plans to refine this whole process further, and will attempt to tie several of the steps together so as to reduce manual input even further. But just in its current state, I have achieved results I would never have been able to if I were to do it manually.
Finally, if you have any questions about any of this, if you got any ideas from reading it or anything else that may be related, I'd love to hear about it in the comment section below.

Thank you for reading!
What is Hive?
To learn more about Hive, this article is a good place to start: What is Hive?. If you don't already own a Hive account, go here to get one.
@leoglossary links added using LeoLinker.
Posted Using InLeo Alpha
That's why I value the importance of engagement. Through our conversation, look where we are now? You brought something very valuable to Hive and this should be widely publicized and promoted.
It is this type of work like yours that should be recognized and will undoubtedly be rewarded in different ways.
It had to be @taskmaster4450le to bring you a very laborious mission summarizing his thousands of videos. LOL
But I'm glad you managed to find an alternative to all of this.
Success on your journey my friend! You deserve all the good things that the Hive and Leo ecosystem can provide you.
May more ideas emerge from our interaction.
Thank you fren. This is how we grow! I have big plans to expand this concept, and more podcasts/channels have already requested summaries too. Currently processing @bradleyarrow's channel. After that @jongolson and then @selfhelp4trolls. Hopefully the list will keep growing.
Glad to know that. Here's to many more requests!
great job. I'm not sure if im missed reading it but does it autopost or are u copy pasting and posting it
In the case of the ones I do in the day to day, I post them manually. Regarding the 1700 videos described in this post, they are posted automatically by the script created in Problem 5.
i see. that makes sense. nah I figured the 1700 videos would be automatic. No way you would do all that on your own or would you :P.
Wow! I know nothing about coding, buy it sounds like that AI is pretty amazing! I would say well done on your putting it all together as well!
Thank you! It's not necessary to know coding at all to use AI. If you have no experience with interacting with LLM's this is a pretty complicated use-case though – you can use it for much simpler stuff too. For instance:
https://inleo.io/threads/view/mightpossibly/re-leothreads-jkjf3zek
Highly recommend giving it a go! It's experience worth having, however simple the use-case.
Congratulations @mightpossibly! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 64000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out our last posts:
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
Congratulations @mightpossibly! You received a personal badge!
Wait until the end of Power Up Day to find out the size of your Power-Bee.
May the Hive Power be with you!
You can view your badges on your board and compare yourself to others in the Ranking
Check out our last posts:
Congratulations @mightpossibly! You received a personal badge!
Participate in the next Power Up Day and try to power-up more HIVE to get a bigger Power-Bee.
May the Hive Power be with you!
You can view your badges on your board and compare yourself to others in the Ranking
Check out our last posts: