While building your Steem blockchain dApp, you will soon realize that it’s not that easy to get the data you are looking for quickly, unless there’s already an API that gives you what you need.
We have several reliable, general purpose, “full” API nodes, provided by Steemit Inc. and community members:
| Steem API endpoint | owner |
|---|---|
| https://api.steemit.com | Steemit Inc. |
| https://anyx.io | @anyx |
| https://api.steem.house | @gtg |
| https://steemd.minnowsupportproject.org | @followbtcnews |
| https://steemd.privex.io | @privex |
You can use them for development or even (if you are brave enough) for production.
If your dApp is small and simple, it might work. And yes, in many cases it will.
But is it optimal? No.
In previous episodes, I described different types of nodes and their names and how this can be misleading when it comes to the so-called “full” nodes.
TL;DR
A full node means here something different than in the Bitcoin realm, where Bitcoin full node is pretty much something that a Steem consensus node can do.
Here, on Steem, the word “full” doesn’t refer to anything related to the blockchain - it refers to the fully featured set of APIs enabled within steemd.
Do you really need a full set of API calls?
In most cases you don’t. To get an idea about the information you can get from common Steem APIs, take a look at the devportal:
https://developers.steem.io/apidefinitions/
By the way, please consider voting for Steem.DAO @inertia’s proposal, who already greatly contributed to the Dev Portal Documentation and is eager to do more.
For example, if you need the information returned by get_market_history, take a look at condenser_api.get_market_history and at its underlying api, in which case you will find:
Also see:
market_history_api.get_market_history
Which means that the API node you need should be running amarket_historyplugin.
Another example is a situation in which you want to find who “Resteemed” (a.k.a. “Reblogged”) a given post.
Here, you are lucky, because there’s a method for that called get_reblogged_by and provided by the plugin follow.
Maybe you want to get tags used by a specific author? That’s easy too, there’s the get_tags_used_by_author method provided by - yes, you guessed correctly - tags plugin.
There’s a pretty big chance that if your app needs to use get_market_history, it doesn’t need tags or follow plugins, because it’s not blogging oriented, and vice-versa - if you deal with tags and follow, you probably don’t care about the internal market.
Such knowledge lets you optimize the API infrastructure needed for your dApp.
For instance, you can run a “fat node” without market_history, account_history(see Steem Pressure #6) and use hivemind to get the tags and follow features.
That’s not the end yet. You get a lot more data than you’ve asked for, but still that may not be what you need.
Do you know why? If not, then please, read the first paragraph again.
How many blocks has the witness gtg missed so far?
That’s easy.
Run:
curl -s --data '{"jsonrpc":"2.0", "method":"database_api.find_witnesses", "params": {"owners":["gtg"]}, "id":1}' https://api.steem.house
You will instantly get your answer, because the find_witnesses method returns this information… among many pieces of information that you don’t need.
Now, try something more complicated:
Problem to solve
How many blocks did @gtg produce until block 40000000?
And how many blocks did @gtg produce in August 2017?
And how many blocks did he produce that contained more than 50 transactions?
And what percentage of blocks produced in 2018 had more non-virtual operations than transactions?
How many blocks had only one transaction and which of them had the highest number of non-virtual operations? What is the id of the transaction that contains them?
You should be able to answer all these questions, all the data are in the blockchain after all. The problem is that steemd has no suitable API to answer these questions quickly.
This means that you either have access to a third party service / API that can answer these questions (see @arcange’s SteemSQL “SQL server database with all Steemit blockchain data”, which is available in subscription model), or look into blocks to find your answer.
In the latter case, you will have to inspect all the blocks ever produced using the get_block method.
The good news is that every consensus node can run the block_api plugin.
The Steem blockchain has recently passed the 40 million blocks mark.
This means that in order to answer the first question, you will need to send more than 40 million requests to the API endpoint.
Each time this type of question is asked you will need to repeat the procedure, unless you…
Build and run your own custom Steem API

TL;DR in Memeglish so that project managers can get it.
No. I’m not going to build an API in this post.
It is supposed to be your own API, solving your problems, optimized for your use case.
Instead, I’m going to play with some blockchain data to give you some tips.
To illustrate this, let’s analyze the problem described above. .
Let’s ignore incoming blocks and keep our focus in the range up to 40000000 blocks (catching up with the head block and dealing with micro-forks is a good topic for another episode; in the meantime, you can take a look at how hivemind does this).
Let’s assume that you can’t or don’t want to extend steemd with your custom fancy_plugin or a fancy_plugin_api that does the job.
Keep It Simple Stupid
We don’t need information about virtual operations, so instead of using get_ops_in_block, which requires account_history plugin and API, we can use get_block, which saves a lot of resources, if you want to run your own node.
How does a request look?
curl -s --data '{"jsonrpc":"2.0", "method":"block_api.get_block", "params":{"block_num":197696}, "id":1}'
How does a response look?
{
"jsonrpc": "2.0",
"result": {
"block": {
"previous": "0003043f5746b4d9d06932467ad852ac5d71231c",
"timestamp": "2016-03-31T13:56:18",
"witness": "sminer22",
"transaction_merkle_root": "63321e3f001bed17d301399c5eeaa9b37a0bf74b",
"extensions": [],
"witness_signature": "1f64e94d51baef0b84be04644fafc0b05959e80db64de7b099d00499587f23f97216acd3d8df3c3b81f672b24f8cf47167720d205693d3f5713a65bcf004cffef3",
"transactions": [
{
"ref_block_num": 1087,
"ref_block_prefix": 3652470359,
"expiration": "2016-03-31T13:56:45",
"operations": [
{
"type": "vote_operation",
"value": {
"voter": "proskynneo",
"author": "proskynneo",
"permlink": "steemit-firstpost-1",
"weight": 10000
}
}
],
"extensions": [],
"signatures": [
"202765ea6b688c2ce968ff2b3f1f6715fddd67374f409a202ae720ca072cb6a919175c27921edfc24c5e3d898a221e88395af31a155b1d60b2bd5475d30a30e226"
]
}
],
"block_id": "00030440d0fbfc8323a1388cd009f2a7f9f43162",
"signing_key": "STM6tC4qRjUPKmkqkug5DvSgkeND5DHhnfr3XTgpp4b4nejMEwn9k",
"transaction_ids": [
"679bcc6414b2f2bd16818a83f020bb9a478a84c4"
]
}
},
"id": 1
}
Well, when pretty printed for your convenience, API normally returns a compact version, which is just one line without extra whitespaces.
Caveat
As you can see, the resulting data don’t contain block_number, but you can use the id that equals the block number you are asking for.
We need to get 40M blocks.
That’s a lot, but fortunately you need to do this only once.
Irreversible blocks are not going to change because… well, I hope you can guess why ;-)
Even if you use jussi’s batch requests, throwing that many requests at public API nodes will quickly trigger rate limiting, and even if it doesn’t, it will take a significant amount of time.
Your own consensus node for simple tasks
You can use your own consensus Steem node for that. Local means faster.
Think about latency and how any latency (1ms? 2ms?) is no longer negligible if you multiply it by 40000000.
Such a node is not resource hungry, and with MIRA you can easily run it on a 8GB RAM machine with 500GB storage.
A consensus node currently needs 245GB for block_log and 56GB for the state file.
Besides, your dApp will benefit from such a node also for broadcasting purposes.
Configuration is as simple as that:

Use someone else’s hard work
There are already people (like me) who serve the block_log to speed up replay times.
If only there were a place where one could bulk download JSON files with Steem blocks...
Well, if there’s a need for it, I can make it available with 1M block packages every time we reach 5 or 10 million.
It will save a lot of time for all microservices that require block processing (the last mile can be synced using traditional methods)
Bulk
You’ve already seen how a single block looks in JSON format.
Obviously, we are using compact output to save space.
The whole data set (40M blocks in the uncompressed JSON format) takes 580GB.
For our needs, we need only a small subset of such data.
To get what’s needed we can use jq:
jq -c '
{
id: .id,
block_id: .result.block.block_id,
timestamp: .result.block.timestamp,
witness: .result.block.witness,
txs: .result.block.transactions | length,
ops: [.result.block.transactions[].operations[]] | length,
txids: .result.block.transaction_ids
}'
After processing our blocks we get 46GB of uncompressed json data.
Everything Should Be Made as Simple as Possible, But Not Simpler
A flat file? Are you kidding me?
Use your favorite database to store it.
(Unless your favorite database is MongoDB, then use something else.)
Or maybe RethinkDB?
Some time ago @someguy123 told me about some fancy database designed to store JSON.
”RethinkDB is the first open-source, scalable JSON database built from the ground up for the realtime web. It inverts the traditional database architecture by exposing an exciting new access model - instead of polling for changes, the developer can tell RethinkDB to continuously push updated query results to applications in realtime. RethinkDB’s realtime push architecture dramatically reduces the time and effort necessary to build scalable realtime apps.”
So this not only means effective and effortless storage of JSON data, but also sounds like a perfect choice for many Steem dApps.
But is it? Maybe. For some needs. It’s not perfect for sure, but no solution is.
I’m going to give it a try.
Do your own research. Maybe it will fit your needs. If not, look for something else.
Let’s see how easy it is to store data we need in RethinkDB
Step 1: Install RethinkDB
Check the RethinkDB webpage for installation instructions suitable for your server.
For Debian or Ubuntu, it’s enough to do the usual:
Add RethinkDB repository
echo "deb https://download.rethinkdb.com/apt `lsb_release -cs` main" | sudo tee /etc/apt/sources.list.d/rethinkdb.list
wget -qO- https://download.rethinkdb.com/apt/pubkey.gpg | sudo apt-key add -
sudo apt-get update
Install RethinkDB package
sudo apt-get install rethinkdb
That’s all. No questions asked.
Install the RethinkDB python driver
Because the rethinkdb import subcommand has - surprisingly - an external dependency on the python driver, depending on the way you installed RethinkDB, you might need to get the RethinkDB python driver too.
For that, you need to have pip, and, ideally, virtualenv, so if you don’t then:
sudo apt-get install python3-pip python3-venv
and once you have them, install the RethinkDB python driver into your virtual environment:
python3 -m venv ./rethink
source rethink/bin/activate
pip install rethinkdb
Step 2: Run the server
rethinkdb
Yes. That’s it for now. You can play with more advanced features later.
It enables an administrative console available through HTTP on localhost:8080
Step 3: Load your data.
Throw your JSON data at RethinkDB instance by running:
rethinkdb import -f blockstream.json --table steem.blocks
Where blockstream.json is your big 46GB file with data from 40M blocks.
It goes to a table called blocks within a database called steem.
[========================================] 100%
40000000 rows imported to 1 table in 3615.68 secs
Done (3615 seconds)
Not bad, on my hardware it consumes json stream a little bit faster than what a 100Mbps link could provide.
rethinkdb_data takes 66GB
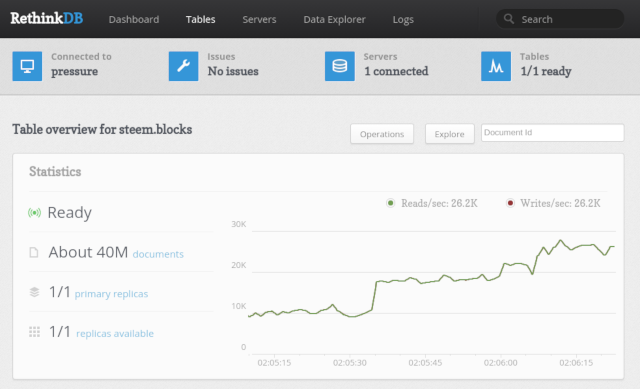
Step 5: Make use of the data
You can use the Data Explorer feature from the administrative console, or use Python, Javascript or Ruby to get the data you are looking for.
If you want to learn more look at the RethinkDB documentation
Depending on your needs, you can create and use secondary indexes to speed up your queries.
Or...
Use a different set of tools and solutions that meet your needs.
A less exotic solution is to use MySQL that supports a native JSON data type, which combined with generated columns might be a good alternative.
(I’m going to try that too.)
Previous episodes of Steem Pressure series
Introducing: Steem Pressure #1
Steem Pressure #2 - Toys for Boys and Girls
Steem Pressure #3 - Steem Node 101
Steem Pressure: The Movie ;-)
Steem Pressure #4 - Need for Speed
Steem Pressure #5 - Run, Block, Run!
Steem Pressure #6 - MIRA: YMMV, RTFM, TLDR: LGTM
Steem Pressure #7 - Go Fork Yourself!
Stay tuned for next episodes of Steem Pressure :-)
If you believe I can be of value to Steem, please vote for me (gtg) as a witness.
Use Steemit's Witnesses List or SteemConnect
Or if you trust my choice you can set gtg as a proxy that will vote for witnesses for you.
Your vote does matter!
You can contact me directly on steem.chat, as Gandalf

Steem On
Hi gtg, this write-up was particularly meaty, fulfilling, wholesome, beefy and deserving of a CHOPS token. Don't Chomp on it all at once!
To view or Trade CHOPS visit steem-engine.com
Check out the #chops-token channel on the SFR Discord
This is a fairly meaty post. It may require splitting into a few servings to fully digest. Thanks @gtg
P.S. using this comment for testing.
Test !CHOPS 4
Wow, someone else on the internet that likes RethinkDB and is suggesting using it for projects? That's awesome, I thought I was the only one!
I think this post and series will be useful for those needing to efficiently get a lot of data from the STEEM blockchain. For my limited uses, steem.js has been working fine.
<script src="https://cdn.jsdelivr.net/npm/steem/dist/steem.min.js"></script>By the way, the link for Steem Pressure #7 seems broken. Here's where that post is:
https://steemit.com/steem-pressure/@gtg/steem-pressure-7-go-fork-yourself-step-by-step-guide-to-building-and-setting-up-a-mira-powered-hf21-ready-steem-consensus-node
Thank you, I just fixed that.
(I was shortening links and went too far with that ;-) )
Interesting. Offering custom APIs may be the way to go for techcoderx.com full node to stand out.
The Universe answered.
Your post is, like, godsend to me. I stuggled with an idea of starting to learn python for some time. With this Steem Pressure series you've conviced me.
Especially 7th episode.
Thank you, I'm glad to hear that! :-)
I'm definitely not the target audience for this post, but I'm glad you're doing what you do, so I don't have to. ;) Stay awesome!
Oh come on, I've made a meme explaining everything ;-)
Ha! Right... Here's hoping I can reach enlightenment without running an API. 'Cause if I tried it, you'd need to create a new meme with a brain exploding instead of getting superpowered.
PostgreSQL's JSON support seems to be worth exploring too.
Definitely.
I was hoping to use something lightweight and simple first, thus checking RethinkDB, however, it seems I was too optimistic about its performance at scale (but I haven't checked RocksDB branch yet).
I had some very scenarios with MongoDB clusters. HDFS/Hadoop though not db seems to the only new-gen NoSQLs that seems to hold up against real world workloads. I am not familiar with RethinkDB but its scalability will be a good item to consider. MySQL and PostgreSQL on the other hand has the tooling to work well with clusters and are time proven. With the JSON support they may be good for our dApp usecases.
Right now however ElasticSearch like @kaptainkrayola pointed out is a scalable solution. Chains like Bitshares and Peerplays have ElasticSearch plugins. I would consider Blockchain + ElasticSearch + demux-js ( https://github.com/EOSIO/demux-js ) implementation for the specific chain as a solution at this point.
PostgreSQL + PostREST (http://postgrest.org/en/v6.0/) would be something I would like to experiment with. I am fond of PostgreSQL as I have a project I inherited 11 years ago with Perl + PostgreSQL and we rewrote Perl to Python but the underlying PostgreSQL is running strong for close to 15 years now.
Have you considered ElasticSearch?
Yes, ElasticSearch will work and most importantly scale really well. If we are looking at query intensive workloads it works really well.
This is simply amazing, the human ideas organized by crypto and now available for analyze
I have no time at the moment, to follow tis posting but I guess, it will be a quite good source for my purposes too. Before I go on, I have to read your manual, dear @gtg. Thank you for this guide.
모두의 희망이 되는 스팀을 만들어주기를 바랍니다. 당신이 많은 스티미언들부터 존경받는 증인이 되기를 바랍니다.
I am trying it on my phone now, thanks! ;D
A useful post and sure, you have my vote since a long time.
And today, I add as well a !BEER for you.
PS: Is there someone who might help me to get a node up and advise us in monitoring?
Thank you :-)
Sure, as soon as I manage to get some spare time (try to catch me on Steem.Chat), but please be patient (to get an idea about my spare time, you can see when I posted previous episode of Steem Pressure ;-) )
Hi @gtg. I know you are damn busy and my question was more into the direction of the community....
I like your optimism, but I'm afraid that there are not many people that will actually read my post and then - if still no sleeping - proceed to a comment section ;-)
Haha yeah, looks like no one read Gandalf's posts. Seems like no one understand such wizard's gibberish. No matter if what you are trying to hack, are computers, blockchain technology or human minds. LoL };)
Hey @gtg, sure I miss all the “easy to eat cat content” with your post, but there are for sure more people as you think who read your work.
Building dapps on steem is “the 2020 thing“ and therefore you need to read from the chain.
Nice write up. But not quite helpful to me though.
Thank you. Hopefully it will help developers making Steem apps better, then all of us will benefit from it :-)
ded
This will be a good thing for steemit..
Congratulations @gtg! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
View or trade
BEER.Hey @gtg, here is a little bit of
BEERfrom @detlev for you. Enjoy it!Learn how to earn FREE BEER each day by staking.
💪💪
Congratulations @gtg!
Your post was mentioned in the Steem Hit Parade in the following category:
this will be very good for steemit
Hello!
This post has been manually curated, resteemed
and gifted with some virtually delicious cake
from the @helpiecake curation team!
Much love to you from all of us at @helpie!
Keep up the great work!
Manually curated by @solominer.
@helpie is a Community Witness.
Hello
I am currently a senior software student working on Steam Blockchain for my master's thesis, and I need to collect and fetch blocks data for my research. Can you guide me on how to get this data using the steem API? It took me a long time to apply. Please, if you can help me, thank you.
I no longer support Steem, sorry.
By the way, if that's a master's thesis, you really should do that by yourself and above post seems to explain everything you need for your task anyway.
Does block _log contain all the data of Hive blockchain blocks?
Yes.
If I want to get get_block, do I need a strong server? I use it very time consuming. I need block information from 2016 to 2018. Should I send this request on a strong system? Or does it require special facilities?
Excuse me, I want to get information about all virtual and key block operations from 2016 to 2018 through get_ops_in_block. How can I do this faster? Please help me?
Faster than what?
To reduce latency, use your own local node.
Alternatively, write your own plugin to dump whatever you need during replay.
I do not want to replay the block, I just need the data of the operation performed on HIVE. Only when I connect to the https://hive.hivesigner.com API to get the data is very time consuming and there is a long delay in receiving the information.
You do, you just don't understand what the replay means.
Use a local node as I suggested you before to get rid of those delays.
"Steem Pressure #8: Power Up Your dApp. RethinkDB? KISS my ASAP" appears to be a highly technical and potentially insightful article, likely delving into the intricacies of developing decentralized applications (dApps) on the Steem blockchain, with a nod towards database management and efficient design principles like KISS (Keep It Simple, Stupid). The intersection of dApp development with cryptocurrency trading is particularly noteworthy here. As dApps become more sophisticated and user-friendly, they're poised to play a pivotal role in the broader adoption of cryptocurrencies for everyday transactions and investments. This article might offer valuable insights on optimizing dApp performance and user experience, which is crucial in a market where ease of use can significantly impact the adoption and trading volume of a particular cryptocurrency. It underlines the importance of blending technical excellence with practical simplicity in the ever-evolving world of blockchain and digital finance.
Nice article.
MySQL? Try PostgreSQL, it's json / jsonb handling is really fast.
Your bot is broken. It comments again when matching and already resteemed post is edited.
It's just a disagreement on rewards.
I disagree to reward idiots and scammers with STEEM.
Both groups can still make use of anti-censorship features of Steem and post their content freely.
I just execute my right as SP holder to allocate Steem rewards pool to authors that brings value.
I try to be judicious w my joy emojis but this little exchange earned it. 😂
Thank you, @gtg. Let's not all of us rush to buy LASSECASH at one time now. Everybody form a single file line! Don't want anybody to get trampled with the insane demand for the LASSE token.
/s (as if the sarcasm was not obvious enough.)
@whatsup I think you may get some giggles here.
(LASSE token would have fared better if it were named after the dog imo)
!dramatoken
You're upping the drama to new levels! Have a DRAMA.
To view or trade
DRAMAgo to steem-engine.com.Nice. Now you have my attention.