
I want to elaborate not only on introduced features but also on my thought and reasoning so everyone can benefit and introduce changes in their projects. This post will be long but I believe it might be useful for the entire HiveDevs community.
The workflow is built on top of Gitlab CI/CD but can be easily modified for any other CI/CD tool (i.e. CircleCI or Jenkins).
Docker
I've started my work by reviewing Dockerfile. I've built the condenser image and was a bit shocked:
$ docker image ls
condenser latest 6d57c0c8a904 19 seconds ago 1.54GB
1.54 GB for a simple frontend application? Boy, it's just too much. Let's do something with it.
Leaner docker image
Let's start by recognizing the reason why is this so big. You can also look into your Dockerfile and package.json and search for some common mistakes:
- using full-sized images rather than
alpineversions - installing dev dependencies for production images
- putting dev dependencies into production dependencies list
- copying useless files into the final image
Yep, you can check every point here. Let's make some work on a new Dockerfile:
FROM node:12.16.2 as development
WORKDIR /var/app
COPY package.json yarn.lock ./
RUN yarn install --non-interactive --frozen-lockfile --ignore-optional
COPY . .
RUN mkdir tmp && yarn build
CMD [ "yarn", "run", "start" ]
### REMOVE DEV DEPENDENCIES ##
FROM development as dependencies
RUN yarn install --non-interactive --frozen-lockfile --ignore-optional --production
### BUILD MINIFIED PRODUCTION ##
FROM node:12.16.2-alpine as production
WORKDIR /var/app
ARG SOURCE_COMMIT
ENV SOURCE_COMMIT ${SOURCE_COMMIT}
ARG DOCKER_TAG
ENV DOCKER_TAG ${DOCKER_TAG}
COPY --from=dependencies /var/app/package.json /var/app/package.json
COPY --from=dependencies /var/app/config /var/app/config
COPY --from=dependencies /var/app/dist /var/app/dist
COPY --from=dependencies /var/app/lib /var/app/lib
COPY --from=dependencies /var/app/src /var/app/src
COPY --from=dependencies /var/app/tmp /var/app/tmp
COPY --from=dependencies /var/app/webpack /var/app/webpack
COPY --from=dependencies /var/app/node_modules /var/app/node_modules
COPY --from=dependencies /var/app/healthcheck.js /var/app/healthcheck.js
HEALTHCHECK --interval=30s --timeout=5s --start-period=30s --retries=5 CMD node /var/app/healthcheck.js
CMD [ "yarn", "run", "production" ]
What has been improved:
- Node.js version was upgraded from
8.7to12.16.2which is the latest LTS at the moment. Always try using the latest framework versions, which may include security fixes and performance upgrades. It's also a good habit to use a specific version up to thepatchnumber. - Multistage build was used to build an optimal image for production deployment. First, we build a
developmentstage with every dependency to be able to compile React application. Next, we're removing development dependencies with--productionswitch during thedependenciesstage. After all, we're creating a minimal image from thealpinenode version which is the smallest base available, by copying only necessary files and directories. - Healthcheck has been introduced, so the docker daemon can easily manage containers with automatic restarts if necessary and zero-downtime deployments which will be explained later in this post. It will be also useful for dynamic scaling capabilities with
docker swarm.
Also, package.json file was modified, but it's not worth to post its content here:
- Dev dependencies like
webpack,babeloreslintwas moved into a proper list calleddevDependenciessoyarncould install only production deps for the final image. - Strict versions were introduced for every dependency to make sure every build produces exactly the same image. Semantic versioning is popular, but there is no way to check if the package author does not introduce breaking changes with only
patchversion increased. If you need to update a package, do it manually. If you have enough test coverage, you can update the package and run CI/CD to check if everything works fine.
After all that work done, the condenser image size was massively reduced:
$ docker image ls
condenser latest 58406d338e67 8 seconds ago 226MB


The compressed image in the docker registry is even smaller. Much better, right? Shame on you, Steemit!
Healthcheck
Simply speaking, docker is running containers and trying to keep it alive as long as possible. But the system needs to have a tool to determine if the container is actually alive. It may seem alive, but is your app responding to requests for example? Fortunately, docker has also integrated health check mechanism which can be integrated into Dockerfile or docker-compose.yml. Usually, you need to create an endpoint for liveness checks. Fortunately, condenser already has one so we can utilize it easily.
There is a lot of examples with curl used as a docker health check, but it's not a good way to go. Healthcheck should work cross-platform and curl implementation differs on Windows and Unix. You should write health check in the same technology or framework as your projects are written, for condenser it's Node.js.
const http = require("http");
const options = {
host: "localhost",
port: "8080",
path: '/.well-known/healthcheck.json',
timeout: 5000
};
const request = http.request(options, (res) => {
console.log(`STATUS: ${res.statusCode}`);
if (res.statusCode == 200) {
process.exit(0);
}
else {
console.error(`ERROR: ${res.statusCode}`);
process.exit(1);
}
});
request.on('error', (err) => {
console.error('ERROR', err);
process.exit(1);
});
request.end();
When ready, instruct Docker to use your health check mechanism. Add following line into your Dockefile:
HEALTHCHECK --interval=30s --timeout=5s --start-period=30s --retries=5 CMD node /var/app/healthcheck.js
Make sure this file /var/app/healthcheck.js exists inside your image. If you want to be sure your health check is working, inspect your container after running it:
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
060166cf52ee hiveio/condenser:development "docker-entrypoint.s…" 5 minutes ago Up 5 minutes (healthy) 0.0.0.0:8080->8080/tcp mystifying_dhawan
There should be a (healthy) indicator in STATUS column. And there is. Please also note that during the container startup process, it will indicate slightly different status (starting), as the docker daemon will wait before making the first check. It's because we're giving some time for our app to startup. It's the start-period parameter.
Depending on your app and traffic/load, those parameters should vary.
Pushing images to Docker Hub
We already have an improved (smaller) docker image, so it's time to push it to the repository. Doing it manually is a waste of time and may cause human mistakes. The best way is to utilize Gitlab Runner to do it for us in an automatic and bullet-proof manner.
Here is a job definition from .gitlab-ci.yml file with some additional code which we will breakdown:
variables:
DOCKER_IMAGE: hiveio/condenser
.docker-job: &docker-job
image: docker:stable
services:
- docker:dind
before_script:
- echo $HUB_TOKEN | docker login -u $HUB_USERNAME --password-stdin
build-development:
<<: *docker-job
stage: build
variables:
DOCKER_TAG: $DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA
DOCKER_TAG_MAIN: $DOCKER_IMAGE:development
SOURCE_COMMIT: $CI_COMMIT_SHA
only:
- develop
script:
- docker build -t $DOCKER_TAG -t $DOCKER_TAG_MAIN --build-arg SOURCE_COMMIT --build-arg DOCKER_TAG .
- docker push $DOCKER_TAG
- docker push $DOCKER_TAG_MAIN
First, we're creating global variable DOCKER_IMAGE so we can reuse it later in many places. And in case we would like to change the image name, we do it only in a single place.
Hence we have multiple jobs defined in .gitlab-ci.yml file, it's good to utilize advanced YAML syntax, which includes hidden keys and anchors. It will decrease the duplicated code and make the file easier to read and maintain. Every job name starting with the dot will be considered as a hidden key and won't be directly executed. Btw, this is a quick way to temporarily disable any job in your GitLab CI/CD without commenting or removing it.
By using .docker-job: &docker-job we created an anchor which can be later used to extend any job. If you add <<: *docker-job, it will populate image, services and before_script properties automatically. It's a good move if you have multiple jobs that do similar things.
Later on, we're creating some additional local (job scoped) variables:
DOCKER_TAG_MAINwhich will be evaluated tohiveio/condenser:developmentDOCKER_TAGwhich will be evaluated tohiveio/condenser:344e55efor similarSOURCE_COMMITwhich will be evaluated to344e55efefd56e00b15eea6ccf8560a1107b9ff6(or similar commit SHA)
It's a good idea to double tag an image. Latest tag is useless if you want to track your development process. Later on, I will describe the way how we're using this specific, sha-tagged image to track deployments and rollback them anytime with a single click.
Finally, we're building an image with additional build arguments by using --build-arg:
docker build -t $DOCKER_TAG -t $DOCKER_TAG_MAIN --build-arg SOURCE_COMMIT --build-arg DOCKER_TAG .
If you scroll up to the Dockerfile section, you will notice ARG SOURCE_COMMIT and ENV SOURCE_COMMIT ${SOURCE_COMMIT} which means these build arguments will be injected as an environment variables into your containers. It's a quick and easy way to pass additional, build-level variables into your images. Those specific variables are later returned by the condenser health endpoint. It may be useful to check a specific instance source.
$ curl https://staging.condenser.engrave.dev/.well-known/healthcheck.json
{"status":"ok","docker_tag":"hiveio/condenser:344e55ef","source_commit":"344e55efefd56e00b15eea6ccf8560a1107b9ff6"}
An important thing to mention is that HUB_TOKEN and HUB_USERNAME are environment variables injected into the GitLab runner job and configured in Projects Settings. To prevent unauthorized users from pushing malicious images into the official registry, those variables are configured as protected and masked, which means they can be only used on specific branches and are moderated from job logs, so there is no way it can leak without internal bad actor with elevated permissions.
Merge requests
To improve the process of adding new features and fixes to the codebase, Merge Requests have got a brand new CI/CD workflow which includes the following jobs:
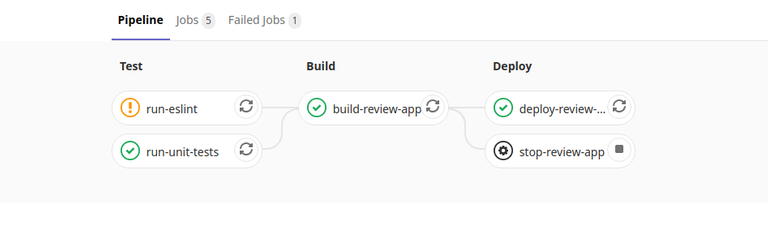
The entire pipeline is fired on every Merge Request and it's required to pass before changes could be merged. If the pipeline fails for some reason (i.e. failing unit tests), there is no way to merge changes into the main branch. This will enforce code quality and prevent regression.
Eslint
Code quality and standardization are important, especially if it's an open-source project that could be maintained by totally different developers from all around the world. Eslint is a tool that statically analyzes the code to quickly find potential problems and keep code organized with specified rules. Code analysis is especially useful when developing Javascript applications. It's really easy to make some stupid mistakes.
Eslint job will be fired on every Merge Request and on every branch pushed to the repository:
run-eslint:
stage: test
image: node:12.16.2
only:
- branches
- merge_requests
before_script:
- yarn install --frozen-lockfile --ignore-optional
script:
- yarn ci:eslint
allow_failure: true # will be changed to false when all linter errors removed
Because the codebase is a bit neglected, run-eslint job is allowed to fail for the moment (allow_failure: true), which is indicated by an orange exclamation mark on a MR view or pipelines list. There are "some" errors and warnings right now but it should be cleaned up soon, so we can require eslint job to pass before merging proposed changes:
✖ 1208 problems (1187 errors, 21 warnings)
831 errors and 0 warnings potentially fixable with the `--fix` option.
error Command failed with exit code 1.
Unit tests
Extensive testing is the only way to produce bullet-proof code and stable applications. Similar to run-eslint, run-unit-tests job is fired on every branch and every merge request.
run-unit-tests:
stage: test
image: node:12.16.2
only:
- branches
- merge_requests
before_script:
- yarn install --frozen-lockfile --ignore-optional
script:
- yarn run ci:test
coverage: /All files[^|]*\|[^|]*\s+([\d\.]+)/
Testing suit (jest) was configured to produce coverage report:
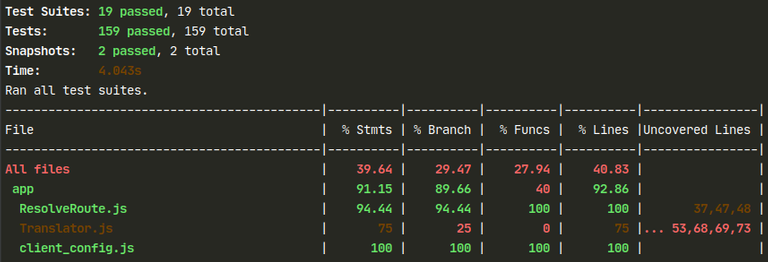
This report is later parsed by a Gitlab, using coverage: /All files[^|]*\|[^|]*\s+([\d\.]+)/ configuration. It will display coverage status and percentage change on the Merge Request view, allowing reviewers to quickly inspect if the code quality is increasing or not.
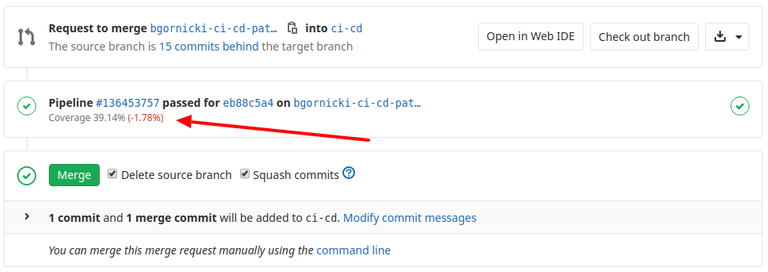
I would advise declining merging new features not covered with tests. This may be omitted for important fixes, but we all should try to make the code better, not worse.
Also, repository settings were changed and Pipelines must succeed setting is checked by default. It means no more broken code on develop/production branches.
Review apps
Review Apps are a huge and very important feature. From now on, every feature can be inspected visually by the reviewer with a single click. Gitlab Runner will create a special instance built from proposed code and expose it for the reviewers:
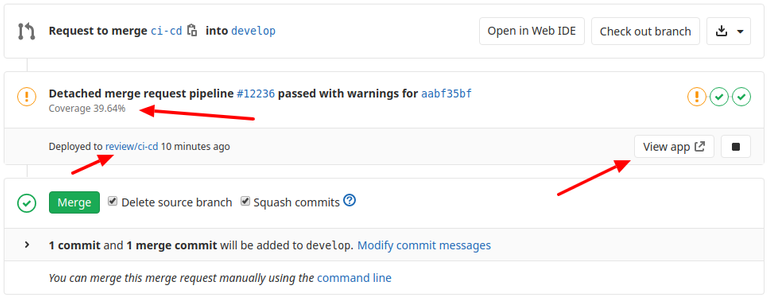
Review app requires three jobs to run on a merge request:
build-review-app:
<<: *docker-job
stage: build
variables:
DOCKER_TAG: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
SOURCE_COMMIT: $CI_COMMIT_SHA
only:
- merge_requests
before_script:
- echo $CI_JOB_TOKEN | docker login -u $CI_REGISTRY_USER $CI_REGISTRY --password-stdin
script:
- docker build -t $DOCKER_TAG --build-arg SOURCE_COMMIT --build-arg DOCKER_TAG .
- docker push $DOCKER_TAG
deploy-review-app:
<<: *docker-job
<<: *docker-remote-host-review
stage: deploy
variables:
DOCKER_TAG: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
SERVICE_NAME: review_$CI_ENVIRONMENT_SLUG
only:
- merge_requests
script:
- DOCKER_CERT_PATH=$CERTS docker -H $REVIEW_HOST --tlsverify pull $DOCKER_TAG
- DOCKER_CERT_PATH=$CERTS docker -H $REVIEW_HOST --tlsverify service rm $SERVICE_NAME || true # try to remove previous service but do not fail if it not exist
- DOCKER_CERT_PATH=$CERTS docker -H $REVIEW_HOST --tlsverify service create --with-registry-auth --network infrastructure --name $SERVICE_NAME $DOCKER_TAG
- echo "Review app deployed"
environment:
name: review/$CI_COMMIT_REF_NAME
url: https://$CI_ENVIRONMENT_SLUG$APP_REVIEW_SUBDOMAIN
on_stop: stop-review-app
auto_stop_in: 1 week
stop-review-app:
<<: *docker-job
<<: *docker-remote-host-review
stage: deploy
variables:
SERVICE_NAME: review_$CI_ENVIRONMENT_SLUG
only:
- merge_requests
when: manual
script:
- DOCKER_CERT_PATH=$CERTS docker -H $REVIEW_HOST --tlsverify service rm $SERVICE_NAME || true # try to remove previous service but do not fail if it not exist
- echo "Review app stopped"
environment:
name: review/$CI_COMMIT_REF_NAME
action: stop
The first job should look familiar if you read previous parts of the post. The only difference is that we're overwriting before_script. Note that if you're using anchors, you can always overwrite the template freely which is what we did here.
Because merge requests could be opened by developers which may not be well known in the community (vel. bad actors), it could be a security issue if the CI/CD on Merge Requests could push images to the official repository. To prevent this, we're using an internal registry provided by the Gitlab itself. It's private, will work well for Review Apps but won't be accessible by anyone else.
echo $CI_JOB_TOKEN | docker login -u $CI_REGISTRY_USER $CI_REGISTRY --password-stdin
We are using CI_JOB_TOKEN, CI_REGISTRY_USER and CI_REGISTRY which are environment variables injected automatically by Gitlab, no need to configure them. Also, please note using --password-stdin which is a more secure way to log in as it will prevent the password from being exposed in job logs.
By default, docker will connect to the local daemon on unsecured, but not exposed port. It is yet possible to configure Docker daemon to validate TLS certificates so it could be exposed to the external world in a secure way, which is how we deploy services from our runners to our machine. You need to pass additional parameters:
-Hwhich is remote docker address--tlsverifymakes sure your daemon is trying to identify itself with certificates--with-registry-authwill send registry authentication to swarm agents--networkwill connect service to the specified network so the reverse proxy could expose the instanceDOCKER_CERT_PATHwill instruct demon where to search for TLS certificates
DOCKER_CERT_PATH=$CERTS docker -H $REVIEW_HOST --tlsverify service create --with-registry-auth --network infrastructure --name $SERVICE_NAME $DOCKER_TAG
This will create a new docker service and expose it automatically under the URL created with CI_ENVIRONMENT_SLUG, which is a variable provided by Gitlab. It's guaranteed to be a valid URL or docker/kubernetes service name.
Review App instances are automatically removed when MR is closed or 1 week after it's opened. This is achieved by running stop-review-app job which is configured to be manually triggered (when: manual).
Tracking environment deployments

By using sha-tagged images, it's possible to quickly redeploy the environment at any moment, with a single click. In case of emergency, project maintainers can rollback the environment to the specified point in time (docker image to be specific)
Staging
Deploying a staging environment is quite similar to deploying a Review App. It also uses remote docker daemon but the service is not created on-demand, it's updated with a new image.
With docker swarm mode, you can ensure your application to be highly available. The swarm agent will take care of your containers. It will restart them or spin a new one if necessary (this is why health check is so important). It is a built-in, native docker mode everyone should start using.
deploy-staging:
<<: *docker-job
<<: *docker-remote-host-staging
stage: deploy
variables:
DOCKER_TAG: $DOCKER_IMAGE:$CI_COMMIT_SHORT_SHA
SERVICE_NAME: staging_condenser
only:
- develop
script:
- DOCKER_CERT_PATH=$CERTS docker -H $STAGING_HOST --tlsverify pull $DOCKER_TAG
- DOCKER_CERT_PATH=$CERTS docker -H $STAGING_HOST --tlsverify service update --image $DOCKER_TAG --update-failure-action rollback --update-order start-first $SERVICE_NAME
environment:
name: staging
url: https://$STAGING_DOMAIN
Job uses protected variables to prevent "bad" developers from pushing/deploying malicious code. It is only possible to push staging from the protected develop branch. Pushing directly to develop is disabled.
Zero downtime deployments
Updating single service is easy with docker swarm:
DOCKER_CERT_PATH=$CERTS docker -H $STAGING_HOST --tlsverify service update --image $DOCKER_TAG --update-failure-action rollback --update-order start-first $SERVICE_NAME
There are additional but important parameters provided:
--image $DOCKER_TAG- update existing service by running new containers with the specified image. For this case, it's sha-tagged image build from develop branch--update-failure-action rollback- by default, docker daemon will try to update the service and do nothing if it fails. By passing this parameter, we're instructing docker to roll back the service to a previous state, which means containers using the previous image.--update-order start-first- by default, docker will kill current containers and spin new ones after it. It may cause some downtime which we don't want. By settingstart-first, we instruct docker to spin new containers first. Swarm agent will switch containers without downtime if the healtcheck result becomes positive. And in case something gone wrong (healtcheck failed for any reason), we end up with a working staging environment because old containers are not touched at all.
Resources under control
With docker swarm you have full control over your services and containers. This is an example configuration which is used for staging environment. With some tweaks, it could be used for production also:
version: "3.7"
services:
condenser:
image: hiveio/condenser:latest
deploy:
mode: replicated
replicas: 2
resources:
limits:
cpus: "0.85"
memory: 2024M
restart_policy:
condition: any
delay: 5s
update_config:
parallelism: 1
delay: 10s
failure_action: rollback
order: start-first
rollback_config:
parallelism: 1
delay: 5s
networks:
- reverse-proxy
networks:
reverse-proxy:
external:
name: reverse-proxy
Production
It is not finished yet, but my advice is to start using docker swarm mode for production deployments (CI/CD is ready). It's designed to serve services like a condenser.
Some key features of Docker Swarm (based on official documentation):
Cluster management integrated with Docker Engine: if you know how to build the docker image, start a container, read some logs, you're ready to use Docker Swarm. You don't need to install additional software as it is a native Docker feature.
Decentralized design: adding a worker or a manager to your swarm is as easy as running a single command. Those could be machines from all around the world.
Scaling: For each service, you can declare the number of tasks you want to run. When you scale up or down, the swarm manager automatically adapts by adding or removing tasks to maintain the desired state.
Multi-host networking: You can specify an overlay network for your services. The swarm manager automatically assigns addresses to the containers on the overlay network when it initializes or updates the application.
Load balancing: You can expose the ports for services to an external load balancer. Internally, the swarm lets you specify how to distribute service containers between nodes.
Secure by default: Each node in the swarm enforces TLS mutual authentication and encryption to secure communications between itself and all other nodes. You have the option to use self-signed root certificates or certificates from a custom root CA.
Rolling updates: At rollout time you can apply service updates to nodes incrementally. The swarm manager lets you control the delay between service deployment to different sets of nodes. If anything goes wrong, you can roll back to a previous version of the service.
And after all, it is called Swarm, can't be a coincidence! ;)
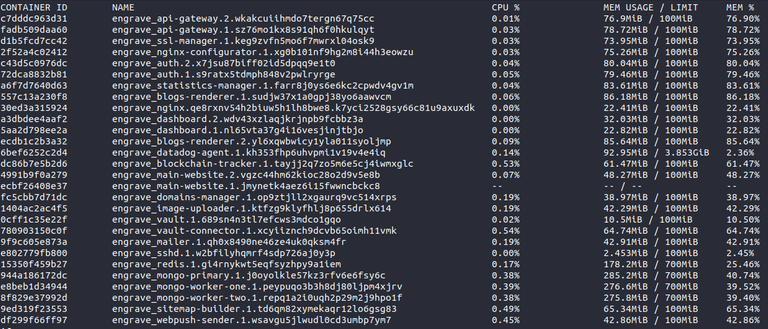
I'm using Swarm mode for most of my projects. Within Engrave (dblog.org) swarm is automatically managing a set of 23 microservices with almost 30 containers at the moment.
My requests and tips for condenser Developers (and not only)
- Please do write unit tests covering your code. Improving coverage will only cause fewer problems and bugs. Coverage is now visible on every merge request so it's damn easy to see a regression. Take care of the code quality.
- Use exact package versions in
package.jsonfile. When using^, it's not guaranteed to install the same version on two different builds. And some developers like to introduce breaking changes without changing themajorversion number. - Use
alpineimages to create minified production images. - Use the latest images from official Docker HUB when possible.
- Use multi-stage builds to create leaner docker image
- Write and configure health checks for your applications
- Run
eslintto clean up your code before you push it to the repository. You can usehuskyto ensure it happens automatically.
Vote for @engrave witness if you find my work valuable

Nice work!
680MB -> 58MB, 90% reduction. Not bad! Use less storage and save some compute, probably speed up builds too. Overall lower cost of ownership. Nice work, @engrave!
Build time will be actually a bit longer because of the multi-stage process but it's worth reducing space and transfer :)
Well that was...impressive
What about that shitty search bar in hive.blog? That thing doesn't work.
I hope it will be fixed soon. We already have an issue on a gitlab opened.
Yeah and I love the way things are done around here now. There's more synergy, direction and purpose about proceedings.
Wow, this is GOLD!
Got only halfway through it, will study it tonight.
1.5 GB, crazy.
great post!
I've been using GitHub Actions a lot lately for projects like Manubot. Great to see GitLab CI is also quite powerful, as its nice that GitLab has an open source edition.
Looking forward to using the YAML substitutions and docker healthcheck down the road! Didn't know about those features.
Impressive work and very educative post.
It's a shame to realize that STINC, with so many paid developers, has such poor code and deployment practices. And it is reassuring and encouraging to see that we can do better, just because we are no more centralized and more transparent.
Thank you @engrave
Thanks :) This was my main concern in the past, as I couldn't believe a company with actually massive amounts of resources can make something like this... But here we are, and it's time to improve it on our own :)
That's a really nice list of "how to be a dev AND work with other people" you've got there :D
Nice work!
This is just a great for not only Hive Developers but for everyone :)
Thanks for your hard work!
Please pardon the post reward adjustment.
No problem, thanks for the note about it :)
Dude...
Without Steemit Inc, we can introduce some professional tools and workflows ;)
Oof
<3
Some next level stuff going on here wow!
Whoa ! This is baby
stepjump right there.Kudos!
This is great work. Thanks!
Superb improvements Engrave Team! :)
Thanks :)
You're welcome! :)