One area of Hive code where BlockTrades has spent a lot of time recently is optimization of hivemind. Hivemind servers supply most of the data used by web sites such as hive.blog and peakd.com. So optimizing the performance of Hivemind helps speed up almost all frontends for Hive, and also allows the network to operate reliably as we get more users.
Data flow in the Hive network
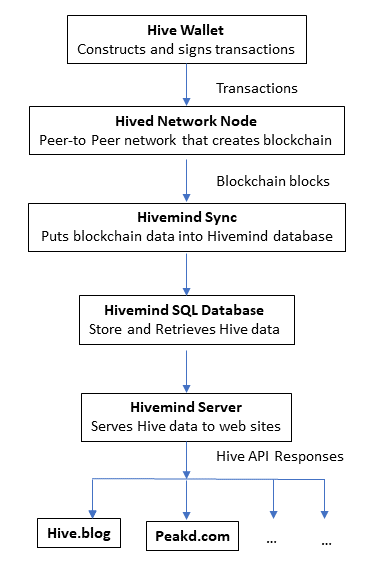
In the diagram above, hived creates the Hive blockchain from user transaction data, and it does directly serve up some data, but the majority of data it produces is sent to a hivemind server.
Why was Hivemind created?
User interfaces (e.g. websites and wallets) get most of their data from hivemind instead of hived. Hivemind is designed to make it easy to access blockchain data in many different ways.
Originally, user interfaces got all their blockchain data directly from hived nodes. But this caused several problems: 1) many programmers were not skilled in the software language (C++) that hived is written in, making it more difficult to add new features to the Hive network, 2) changes to that code could result in bugs that broke the blockchain servers themselves, and 3) having the hive network nodes serve up this data directly to many users put unnecessary loading on the most critical software component in the network.
Hivemind was created to solve the aforementioned problems. Hivemind is written using technologies that are familiar to many programmers (Python and SQL). If a hivemind server fails due to a bug (this has happened three times already in the past few months), the blockchain continues to run smoothly. And finally, Hivemind servers run in a separate process (and sometimes completely separate servers) from hived, tremendously reducing the data access load on hived.
Making Hivemind better
Below is a short summary of the work we’ve been doing to improve Hivemind in the past couple of months:
Making Hivemind faster
Hive-based web sites make calls to Hivemind to get lists of posts, lists of voters, etc. If one of these calls takes several seconds to complete, the user will have to sit there waiting for the data to be delivered to them. On hive.blog, for example, this delay manifests as as a “spinning wheel” to let the user know that the data is coming, but hasn’t arrived yet.
Every web user is familiar with delays of this type, but they really make web sites less fun to use, and if the delays get too long, users will get frustrated and leave a site.
To reduce these annoying slowdowns, one of the main things we did in this round of hivemind improvements was make hivemind much faster. For example, during benchmark measurements of production installations of hivemind at api.hive.blog, some API calls could take as long as 6-30 seconds to complete (that wheel could spin for a long time occasionally). At this point, with our new optimizations running on that same server, the slowest hivemind call in our benchmark measurements completes within less than 0.1 seconds on average. We optimized the overall average API call execution time by a factor of 10 or more. For some of the most time consuming calls that we spent extra time optimizing, we increased the speed by a factor of 20 or more.
We’ll be publishing the full benchmarks in a separate post as they may be useful to frontends developers interested in details on the updated performance of individual API calls.
Improvements to Hivemind API
We’ve modified Hivemind API call functionality to allow the creation of decentralized blacklists. I’ll be posting technical changes associated with the new API call in the next few days to allow existing web sites to take advantage of this new feature.
Migrated more functionality from Hived to Hivemind
We were able to move a lot of the comment data that was previously stored as state information (stored in memory) from hived to hivemind. This dramatically reduced the RAM memory requirements needed to operate a full Hive API node and it also speeded up the response time of API calls for this data.
Most recently, we made a similar change to move inactive voting data from hived to hivemind, once again dramatically reducing RAM requirements for hived.
Note that in both of the above cases, there was no corresponding increase in RAM used by hivemind from this re-partitioning of functionality, because hivemind stores its information on disk in a database.
As a result of the reduced memory requirements, an entire high-performance full API node can now be run on a single 64GB server, cutting costs by 50% or more (cloud service providers charge a significant premium for servers with large memory requirements, and while it was possible to split a full API node across two servers with less memory, this increased server maintenance costs).
Also, because of the speedups in hivemind’s API performance, that same lower cost server can now serve over 10 times the traffic that a single hivemind could previously be support. So in practice, between the reduced memory requirement and increased ability to serve API traffic, the overall cost of running Hive servers has been reduced by a factor of 20 or more.
To highlight the importance of this change, my recollection is that Steemit Inc was at one point spending over $90K per month to pay for leased servers on AWS (Amazon’s cloud platform).
Faster hivemind sync times
When someones wants to setup a new hivemind API node, they have to first fill it with data from the blockchain. This process is known as syncing, because you are synchronizing the data in the hivemind database to match that of historical data already stored in the blockchain blocks.
Previously, syncing a hivemind database was a multi-day process and this time only increased when we migrated more data from hived to hivemind, so we've also been working on increasing the speed at which hivemind syncs. We don't have final numbers yet, but we've already speeded up syncing by at least a factor of 3 (despite the increased amount of data being synced).
Making Hivemind easier to improve
Added database migration software
Hivemind stores its data in a SQL database. As we improve hivemind, it’s often necessary to change the way data is organized into tables in its database (the database “schema”). By tracking changes in the way this data is stored, we can sometimes upgrade existing installations of hivemind without requiring the database tables to be reorganized and refilled with data from scratch.
We added support for Alembic as a means of tracking and automatically making changes to a hivemind installation’s database when hivemind is upgraded. Alembic also supports rollbacks, allowing a database to be downgraded to a previous version, if a new version of Hivemind has problems that require reverting to a previous version of the Hivemind software.
Refactored Hivemind code base
A lot of source code in Hivemind was repeated in several places, with only small changes in each place, so we spent some time doing code refactoring. Code refactoring is the process of identifying common repeated blocks of code and consolidating that code to a single place. Code refactoring makes it easier to make future improvements to the code, because when code is repeated in many places, it’s easy to forget to make a change in each place (which results in software bugs).
Looking ahead
Now that we’ve moved more data over to hivemind, it becomes easier to add new API methods to look at that data in different ways. And since those API methods are written using Python and SQL, and the changes are isolated from the core blockchain code and can't impact the financial security of the network, it really expands the pool of available developers who can safely create custom API methods for Hive.
This ease of creation for new API methods, combined with the ability to create “custom_json” transactions, creates a world of possibilities for Hive-based applications (as an example, the splinterlands game play is implemented using custom_json transactions). And the increased performance of hivemind means it will be easier than ever to create apps that scale to large numbers of users. I plan to write a followup post soon that explores some of these possibilities more in depth, as I think this capability will play a central role in the future of Hive.
A lot to unpack with this update but some fantastic stuff in it, thanks for sharing!
Regarding your section about moving comments from hived to hive mind, does that theoretically mean someone could make an easier process to find comments? I’ve been trying to figure out how to get my really old comments in an easy way. Presently I have to go to a site like PeakD and go to my comments and just scroll endlessly. My browser ends up crashing and I didn’t find what I needed. It would seem that with it now being in Python instead of C++ programmers could find out a way to put them in pages kind of like emails that are 50 per page. Having 50 pages to look through is easier than trying to endlessly scroll, especially the more people like me comment every day.
Might be a tangent here but that’s a personal interest of mine, some people got me into some awesome stuff early on in my hive/Steem journey and I haven’t the slightest clue who they are. Finding them via my comments made years ago has been something I’ve been trying to do but am not having good success lol
Anyways, thanks again for the update and continued work! Appreciate it!
Search engine also works for this purpose, we just need to improve search page in hive.blog that gives some tips on how to use search or improve usability. For example, try changing
*into any word you want and you will get all your relevant commentshttps://hive.blog/search?q=*%20author:cmplxty%20type:commentThanks for this tip! I will definitely give it a try. I’ve got one thing I think will help with that, that I’ve been looking for so that may very well work in that scenario!
That's not at all a tangent, that's exactly the kind of thing that you could easily do with a custom Hivemind API call!
Great work!
Question, syncing from scratch would still pull data from blockchain (hived) right?
Looking forward for more technical notes and source code changes...
Yes, it still pulls data from hived, but it is able to pull the data much faster now, and the insert and updating of the database was also made much faster. A bunch of different techniques were used to achieve this speedup: we added an API function to hived that allows for getting a filtered set of virtual operations, we spawn multiple threads in hivemind to fetch the data, we temporarily drop some indexes and re-add them after sync is finished, etc.
Most of the sync speedups were done in this branch of hivemind: https://gitlab.syncad.com/hive/hivemind/-/commits/dk-issue-3-concurrent-block-query
A lot of the API-related speedups were done in this branch of hivemind: https://gitlab.syncad.com/hive/hivemind/-/commits/query-speedup
Great work, speedups of 10x are really awesome and this will both help taking the cost down and also scaling up Hive for even more users :)
That's the biggest challenge.
Your publications on the new improvements throughout Hive have become my favorites to read!
You have done an incredible job programming all these new improvements. I found it very interesting to know that you are using Python and SQL on Hivemid, I will consider learning Python to keep myself updated and maybe drop some C.
Greetings! @blocktrades
Good stuff. Optimising code for speed and memory efficiency is not easy, so those improvements are very impressive. We need the Hive sites to be responsive as people are used to that these days. Some of us remember waiting ages for images to download over a modem, but now fast connections are standard and some may give up if a site takes more than a few seconds to refresh.
Keep up the good work.
I remember the awful noises of my dial up modem connecting to the internet lol then my mom picking up the phone and screwing it all up! Do you remember Walmart having an internet software? Lol that’s what we were using since it was free.
Back then you could tell the browser not to download images to start with and then watch them appear line by line. Fun days. I used Compuserve for a while and various other UK services. One called Freeserve was popular as you just paid for the phone calls. I ended up getting a second just for the computer, which was an Amiga back then.
Freaking bravo blocktrades. I like that creation of new api methods, this will suits the need of all kind of apps! Hope you're keeping up the great work! Steemit will never show this much transparency in what they do. At least you're sharing with us the progress :)
Many success
I don't know much about that language but it's good to always be informed, the blockchains I met through you did an excellent job. Good luck on your new project
Brilliant! Reminds me of how Apple operates with a lot of focus on speed and efficiency. Thank You!
A huge hug 🤗 and a little bit of !BEER 🍻 from @amico!
Un caro abbraccio 🤗 e un po' di BEER 🍻 da @amico!
Congratulations @blocktrades! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Support the HiveBuzz project. Vote for our proposal!
Hola @blocktrades… He elegido tu post para mi iniciativa diaria de reblogear. Este es mi aporte para Hive…

Sigamos trabajando y aportando ideas para crecer en Hive!...
Hello @blocktrades... I have chosen your post for my daily reblogging initiative. This is my contribution to Hive...
Let's keep working and giving ideas to grow in Hive!
God
Thank you very much for your work! 🙏
Hug from Portugal
That's some serious gains right there!
😃😃😃😃😃😃
We certainly appreciate the type of work you're doing!
Hello, I wanted to exchange some hives for another cryptocurrency and the failed transaction was made and it comes out in my wallet that I transferred to you. Could you help me? I did all the steps well I don't know why that happened when I did it well before
Thanks, love reading behind-the-scene updates! Keep up the good work.
Una super información que hay que resaltar. En cosntante contacto con este tipo de info en pro de ir aprendiendo más y más sobre esta blockchain.
Hi @blocktrades, it's nice to know that Hive is growing in capable and efficient hands.
Hola @blocktrades, es agradable saber que Hive está creciendo en manos capaces y eficientes.
So is this blog the one we come to for updates or changes on Hive.blog and the blockchain? I'm still wondering with there is an analogue to @steemitblog and @steemitdev on the platform that I'm unaware of....
The official blog for the blockchain is @hiveio, but like many of the devs, I also occasionally make updates on the specific work that we (the blocktrades team) are doing.
Thanks for the quick response!
Very nice, this will make the interface will run smoothly.
Good work, continue to progress this community. My regards
Is this new structure???
Woww
this is nice... a lot of complex things on this pot but I still need to read it because i need to be aware of changes on the hive network. the optimization sounds nive already. i must say you guys are doing a great job in improving this platform. Is there anything that can be done to help newbies navigate the site easily or faster. something like a tutorial as soon as you enter the websites as a newbie. I have been on boarding new users and this has been a major complain for them
This is really cool! Thank you for this update and all the hard work put into HIVE from you and your team.
Informative
I want to use the https://hive.hivesigner.com/ API and analyze the operations performed in HIVE through this API. I want to get the information about the operations performed in HIVE from 2016 to 2018, but the request I send to the API is very time consuming. Can anyone guide me?
This is really amazing progress. Very exciting stuff.
Thats great