Dans cet article, nous allons chercher à détecter à l'aide de radiographie la présence ou non d'une pneumonie. La pneumonie est une infection des poumons causée le plus souvent par un virus ou une bactérie. Pour plus d'information, nous vous invitons à aller lire cette page web.
Pour classifier cette maladie, nous allons avoir à notre disposition des radiographies. L'objectif va être de créer un système prenant en entrée une radiographie et nous indiquant la présence ou non d'une pneumonie. Lors de cette étude, nous allons utiliser un système de réseaux de neurones à convolution. En effet, ces derniers sont spécialisés dans le traitement des images. Afin de les utiliser, nous allons utiliser la libraire Keras en python. Pour obtenir des meilleurs résultats, nous verrons comment réaliser un transfert d'apprentissage, nous permettant d'utiliser des modèles pré-entraîner et donc plus performant.
Les données que nous allons utiliser dans cet article sont issues du site Kaggle. De plus, nous vous invitons à suivre notre Kernel que nous avons utiliser pour la création de cet article.
Présentation des données
Dans le jeu de données que nous avons à notre disposition, nous avons trois dossiers différents. Un dossier d'entraînement, de validation et de test. Le dossier d'entraînement contient des données qui vont nous servir durant la phase d'entraînement de notre système. Pour suivre l'évolution de l'entraînement, nous pouvons utiliser les données de validation. Enfin, afin de tester notre système, nous allons utiliser les données présentes dans notre dossier de test. Nous avons dans notre fichier d'entraînement 5216 images, dans notre fichier de validation 16 et dans notre fichier de test 568.
Visualisation des données
Dans chacun de ces fichiers, nous retrouvons deux sous-dossiers, un pour les images de personnes "normal" et un autre de personnes possédant une "pneumonie". L'objectif de cette étude est de pouvoir créer un système qui permet de classifier une image dans l'une des deux catégories, à savoir "normal" ou "pneumonie". Le système que nous allons créer se limite pour l'instant à ces deux catégories. Cependant, rien ne nous empêche d'augmenter le nombre de catégories pour d'autres maladies si vous avez d'autres données à votre disposition.
Nous pouvons visualiser les images de notre jeu d'entraînement à l'aide de la figure ci-dessous. Nous avons donc les images appartenant à la catégorie "normal" sur la première ligne et les images appartenant à la catégorie "pneumonie" sur la seconde ligne.

Images issues de notre base d'entraînement.
Analyse des catégories
Après avoir visualisé certaines images, nous allons chercher à quantifier les données que nous avons à notre disposition dans chacune des catégories. Cela va nous permettre d'obtenir un ordre de grandeur de notre jeu de données.

Histogrammes de la quantité des images présentes dans chacun des ensembles de données.
À l'aide des histogrammes, nous pouvons remarquer que la quantité de données dans la catégorie "normal" et "pneumonie" est identique dans notre base de validation et dans notre base de test. Cependant, nous pouvons constater un écart important dans notre base d'entraînement. Cela va nous poser problème lors de notre étude. En effet, en réalisant un apprentissage sur ces données, notre système sera plus enclin à nous donner comme catégorie "pneumonie", car c'est la catégorie majoritaire de notre jeu de données.
Pour éviter ce problème, plusieurs méthodes existent. La première consiste à augmenter notre base d'entraînement et à obtenir des classes à peu prêtes équilibrées. Ainsi, nous limitons la prédiction d'une classe plus qu'une autre par notre système. La deuxième méthode consiste à augmenter la pénalité lorsque nous avons une erreur sur la catégorie "normal". Cependant, cette méthode peut aussi posé problème. En effet, en augmentant la pénalité nous pouvons causer le problème dans l'autre sens. Ainsi, dans cet article, nous allons privilégier la méthode d'augmentation des données.
Sélection des données
Tout d'abord, dans un premier temps, nous allons chercher à sélectionner les données que nous allons utiliser. Pour ce faire, nous allons, à l'aide du nom des fichiers, récupérer les images. Puis, nous allons les ouvrir à l’aide de la libraire Pillow de python. La première étape va être de transformer toutes nos images au format PNG afin de les traiter de la même manière. Ce format nous permet d'obtenir une matrice et de récupérer pour chaque pixel trois valeurs correspondant aux intensités de rouge, vert et bleu.
Puis, nous allons redimensionner nos images. En effet, nous avons des images ayant des dimensions différentes. Afin de les traiter, il nous faut les mettre à la même dimension. Ici, nous avons décidé de les mettre au format 224 par 224 pixels. Le fait de redimensionner nos images nous permet aussi de gagner en temps de calcul. En effet, en utilisant des réseaux de neurones, nous allons devoir parcourir l'intégralité de notre image. En réduisant le nombre de pixels, nous réduisons la distance à parcourir pour notre système. Bien entendu, avec cette méthode, nous pouvons perdre en précision, car nous perdons de l'information sur notre image.
Enfin, la dernière étape consiste à normaliser les valeurs des pixels. En effet, afin que notre réseau de neurones soit le plus efficace possible, il nous faut des valeurs comprises entre 0 et 1. Ainsi, nous allons diviser chacune des valeurs de nos pixels par 255, ce qui correspond à la valeur maximal qu'un pixel peut prendre.
Vous retrouverez ci-dessous, le code que nous avons utiliser afin de réaliser les différentes étapes que nous avons énoncé ci-dessus.
def transform_images_from_names(names):
"""
Get images in an array based on the name of the folder.
@param names lists of all the name of the pictures.
@return a list of images in array format and the size of our original pictures.
"""
images = []
size = []
for name in names:
"""Open the image"""
image = Image.open(name)
""" Get the size """
size.append(image.size)
""" Resize the image and convert it to RGB format """
image = image.resize((224, 224))
image = image.convert('RGB')
""" Transform to array and append in our list """
sample = np.asarray(image).astype('float32') / 255.0
images.append(sample)
return images, size
Augmentation des données
Afin d'éviter le problème lié à la catégorie déséquilibrée, nous avons décidé d'augmenter nos données. Pour ce faire, nous allons réaliser différentes transformations sur nos données. Nous allons dans cette étude réaliser trois transformations. La première consiste à retourner notre image (flip). Ainsi, le côté gauche devient le côté droit et inversement. Puis, nous allons faire une rotation de notre image vers la droite et une rotation vers la gauche (de 30°). Il existe d'autres méthode de transformation comme le fait de réaliser une transition de notre image. On aurait aussi pu faire des rotations beaucoup plus importantes. Cela aurait permis à notre réseau d'être performant aux perturbations de notre image. Enfin, il existe des méthodes ou nous rajoutons du bruit à notre image. Cependant, dans cette étude, nous limitons nos transformations. Vous retrouverez ci-dessous, un exemple d'une transformation ainsi que le code qui nous a permis de le réaliser.
Exemple d'une transformation par rotation de 30° vers la droite.
def data_augmentation_from_names (names):
"""
Do an augmentation of our data. We will select the flip and the roations.
@param names list of all pictures.
@return dataframe with the name of the picture, target label and image on array format.
"""
images = pd.DataFrame([], columns = ['name', 'target', 'image'])
for name in names:
# Open the image
image = Image.open(name)
image = image.resize((224, 224))
image = image.convert('RGB')
# Do some transformations
hoz_flip = image.transpose(Image.FLIP_LEFT_RIGHT)
rot_left = image.rotate(30)
rot_right = image.rotate(-30)
# Add to our list
images = images.append({
'name': name,
'target' : 0,
'image' : np.asarray(hoz_flip).astype('float32') / 255.0
}, ignore_index=True)
images = images.append({
'name': name,
'target' : 0,
'image' : np.asarray(rot_left).astype('float32') / 255.0
}, ignore_index=True)
images = images.append({
'name': name,
'target' : 0,
'image' : np.asarray(rot_right).astype('float32') / 255.0
}, ignore_index=True)
return images
Création de notre classificateur
Afin de pouvoir traiter des images, nous allons utiliser un réseau de neurones à convolution. Ces réseaux ont la particularité d'être performant lors de l'analyse des images. En effet, ce genre de réseau parcourt les images afin d'extraire des informations comme les formes, les couleurs... Dans le cas d'un système de classification de véhicule, un réseau de neurones va extraire les informations présentes sur une image. Il va extraire des formes et en déduire que sur une image il y a, par exemple, des roues, une carrosserie... Et, à partir de ces informations, notre système va pouvoir réaliser une classification afin d'en déduire qu'il s'agit, ici, d'une voiture. Nous avons donc ici deux phases, une phase dit d'extraction des informations et une phase dit de classification.
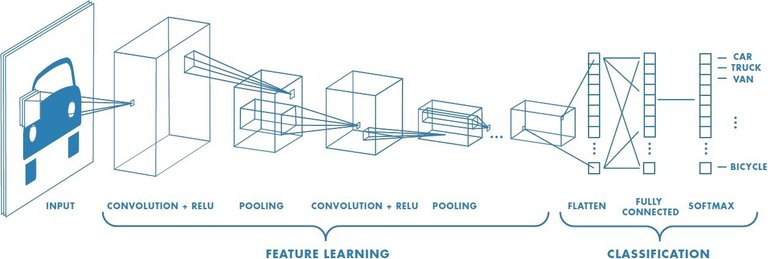
Illustration des deux parties d'un réseau de neurones à convolution.
Pour réaliser ce genre de réseau, nous avons utilisé la librairie Keras. Vous retrouverez ci-dessous un réseau de convolutions basiques. Ce réseau va nous permettre d'obtenir des résultats assez rapidement.
def convolution (categories = 2, shape_x = 224, shape_y = 224, channels = 3) :
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(10, kernel_size=(5,5), strides=(1, 1), activation=tf.nn.relu, use_bias=True, input_shape=(shape_x, shape_y, channels)),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(1,1), padding='valid'),
tf.keras.layers.Conv2D(10, kernel_size=(5,5), strides=(1, 1), activation=tf.nn.relu, use_bias=True),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(1,1), padding='valid'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(categories, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return modelTransfert d'apprentissage
Une méthode assez connue en intelligence artificielle est le transfert d'apprentissage. En effet, dans le cas de réseau de convolutions, la machine apprend à extraire des formes, des couleurs... Cet apprentissage peut être réutilisé quelles que soient les images que nous allons utiliser. En effet, il y aura toujours une phase d'extraction des informations. Ainsi, il peut être judicieux d'utiliser un système déjà performant dans cette approche. De ce fait, il ne nous restera plus qu'à entraîner notre système sur la deuxième phase de notre système qui est la classification.
Pour réaliser un transfert d'apprentissage, nous allons, dans cette étude, utiliser le réseau MobileNet qui est un réseau de neurones à convolution entraîné sur la base de données ImageNet. ImageNet est une base de données regroupant diverses photos annotées. De ce fait, le réseau MobileNet est très performant sur la tâche d'extraction des informations présentes sur une image. Maintenant, nous allons devoir adapter ce réseau à notre problème. Pour ce faire, nous allons réinitialiser la partie liée à la classification et entraîner ce nouveau modèle sur nos données.
# Import Mobilenet model and discards the last 1000 neuron layer.
base_model = MobileNet(weights='imagenet',include_top=False)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024,activation='relu')(x)
x = Dense(1024,activation='relu')(x)
x = Dense(512,activation='relu')(x)
preds = Dense(2,activation='softmax')(x)
transfer_model=Model(inputs=base_model.input,outputs=preds)
transfer_model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
transfer_model.fit(X_train, train_data["target"], epochs=15, batch_size=64)
Résultats de nos modèles
Les résultats que nous obtenons avec nos deux modèles sont très moyens. Cela peut être causé par rapport à notre base d'entraînement. En effet, nous avons généré des images dans une seule catégorie en réalisant des rotations. Or, comme vous avez sûrement pu le constater, les rotations que nous avons réalisé possèdent des coins noirs. De plus, ce type d'image n'est présent que pour une seule catégorie. Cela peut très fortement jouer lors de l'apprentissage.
Modèle basique
Pour ce qui est du premier modèle, le modèle le plus simple, nous obtenons cette matrice de confusion :
[162 72] [162 72]
Modèle transféré
Pour ce qui est du second modèle, le modèle utilisant la technique de transfert d'apprentissage, nous obtenons cette matrice de confusion :
[210 24] [210 24]
Analyse des résultats
Comme énoncé au début de cette partie, les résultats sont plutôt mauvais et les systèmes que nous avons réalisé ne peuvent pas aller en production, car ils ne sont pas assez précis et performant pour le cas d'étude que nous avons (médical). Nous sommes aussi surpris concernant les résultats que nous avons obtenus sur le modèle utilisant un transfert d'apprentissage. On peut expliquer ces résultats par le fait que le modèle déjà entraîné a appris sur des images "classiques" et non sur des radiographies. Ainsi, cela lui a peut-être limité la récolte d'information lors de la phase d'extraction.
Conclusion
Au cours de cet article, nous avons vu comment programmer en python avec Keras des réseaux de neurones à convolution. Bien que nous n'ayons pas obtenu des résultats satisfaisant, nous avons pu voir des techniques permettant d'améliorer nos résultats comme l'augmentation de données qu'il faudrait réaliser dans chaque ensemble de données d'apprentissage afin d'éviter certains problèmes.
Si des personnes sont intéressées par ce problème et veulent réaliser différents tests, nous vous invitons à reprendre notre notebook sur Kaggle. N'hésitez pas à partager vos idées d'amélioration ou vos travaux sur cette thématique dans les commentaires.
Liens
https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia
https://www.kaggle.com/rerere/chest-x-ray-basic-approach-and-transfer-learning
https://www.passeportsante.net/fr/Maux/Problemes/Fiche.aspx?doc=pneumonie_pm
Lien original : https://www.technologieintelligente.fr/intelligence-artificielle/cas-dapplication/classification-de-radiographie-detection-de-pneumonies/
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie and @utopian-io.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness and utopian-io witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Please consider setting @steemstem as a beneficiary to your post to get a stronger support.
Please consider using the steemstem.io app to get a stronger support.
Hi @rerere!
Your post was upvoted by Utopian.io in cooperation with @steemstem - supporting knowledge, innovation and technological advancement on the Steem Blockchain.
Contribute to Open Source with utopian.io
Learn how to contribute on our website and join the new open source economy.
Want to chat? Join the Utopian Community on Discord https://discord.gg/h52nFrV
Congratulations @rerere! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPVote for @Steemitboard as a witness to get one more award and increased upvotes!