
翻栗子 发自 凹非寺
量子位 出品 | 公众号 QbitAI

昨天,Yann LeCun大神发推宣布,Facebook的两个无监督翻译模型,开源了。
所谓无监督,便是不需要双语对照文本,只用单语语料库 (Monolingual Corpora) 来训练AI的翻译能力。
登上了EMNLP 2018
此次开源的两个模型,一个是基于短语的翻译模型 (PBSMT) ,另一个是神经翻译模型 (NMT) 。

二者都经历了以下三个步骤:
1.参数初始化
2.语言建模,有去噪效果
3.回译,自动生成双语对照
由此,即便没有双语语料库作为训练数据,AI依然能够学会翻译。
用WMT’14英法和WMT’16德英两个常用基准,评估模型的表现。结果,两个模型的BLEU分值,皆远远高过了此前表现最好的模型。
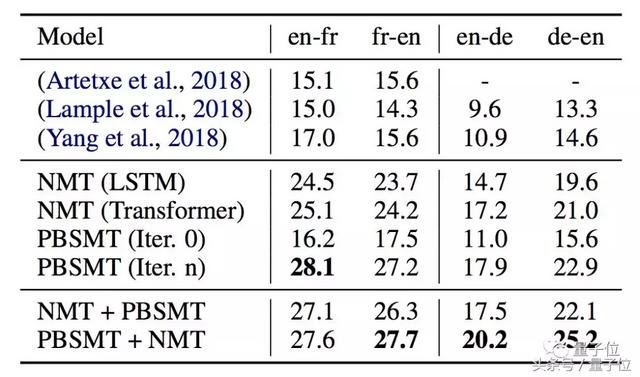
△ 28.1是引入回译之后的分数
加上回译的PBSMT,几乎比前辈的成绩提升了一倍。NMT的表现也不差。
论文中写到,除了性能更强之外,Facebook团队的模型也更简单,超参数比较少。

两只骄傲的AI翻译官,登上了EMNLP 2018。
代码,终于开源了
NMT和PBSMT两个模型的代码实现,都在GitHub上面了。
NMT:
NMT代码实现支持以下功能。
· 三种机器翻译架构:seq2seq,biLSTM+注意力,Transformer
· 在不同模型、不同语言之间,共享参数
· 去噪自编码器的训练
· 双语对照数据训练
· 反向双语对照训练
· 即时多线程生成反向对照数据

△请注意科学烫手
还有一些论文里面没用到的功能,比如:
· 任意数量的语种
· 语言模型预训练/共同训练,参数共享
· 对抗训练
PBSMT:
PBSMT代码实现支持以下功能。
· 无监督的短语表 (phrase-table) 生成脚本
· 自动Moses训练

△ 这只鸡可能很暴躁
请开始,你的翻译
要训练自己的AI翻译,你需要以下工具:
Python 3
NumPy
PyTorch
Moses(用来清洁和标记化文本/训练PBSMT模型)
fastBPE(用来生成并应用BPE代码)
fastText(用来生成嵌入)
MUSE(用来生成跨语言嵌入)
准备好了的话,就开始吧。

△ 违者请放心,不会有事的
GitHub传送门:
https://github.com/facebookresearch/UnsupervisedMT
论文传送门:
https://arxiv.org/pdf/1804.07755.pdf

△ 字幕组卖萌最为致命
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
Posted from my blog with SteemPress : http://blockshare.top/2018/08/%e5%bc%80%e6%ba%90%e4%ba%86%ef%bc%81facebook%e6%97%a0%e7%9b%91%e7%9d%a3%e7%bf%bb%e8%af%91%e6%a8%a1%e5%9e%8b%ef%bc%8c%e4%b8%a4%e7%a7%8d%e8%af%ad%e8%a8%80%e5%88%86%e5%bc%80%e5%ad%a6%ef%bc%8c%e4%b9%9f/