First, we'll create our data set. We'll notice in our test data set, we have different uni values in various IDs. Ultimately, we'd like to get these outputted in a key-value pair with the name of the column and the value. For this example, we're using Databricks, but if you have the appropriate libraries installed, you can run this in your environment.
import scala.collection
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
val table1 = Seq(
(1,"A","uni1"),
(1,"A","uni2"),
(2,"B","uni1"),
(2,"B","uni2"),
(2,"B","uni3"),
(3,"C","uni1"),
(4,"D","uni1"),
(5,"E","uni1")
).toDF("ID","Letter","Val")
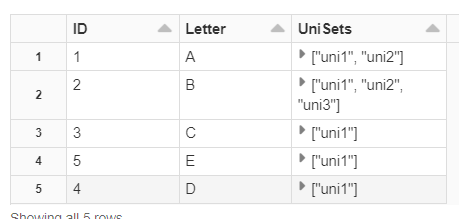
Next, we'll group these Vals as an array in a new column called UniSets. This gets us an array grouping of these values. From here, we want these values to be stored in a key-value pair with the name of the column.
display(
table1
.groupBy($"ID",$"Letter")
.agg(
collect_set($"Val").as("UniSets")
)
)
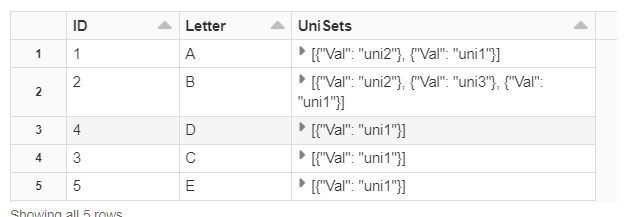
Finally, we'll group our array with the column names and result in a key-value pair:
display(
table1
.groupBy($"ID",$"Letter")
.agg(
collect_set(struct($"Val")).as("UniSets")
)
)