(翻译整理自Dieleman的博客)
针对不同用户推荐合适的音乐是每个音乐类软件都希望实现的目标。本文从传统的协同过滤方法的优缺点说起,引出一套基于音频信号的音乐推荐算法,并在最后对实现的深度神经网络进行可视化剖析,理解模型的运行原理。
协同过滤
协同过滤是音乐推荐的一种基础方法,基本原理是通过历史使用数据来判断用户的喜好。举个例子,如果有两个用户听了大量相同的歌曲,那他们的兴趣应该是基本类似的。从歌曲角度来讲,如果两首歌被同一组人群听过的话,那这两首歌曲也可以被认为是类似的。上面说的两个角度也就是所谓的User-based和Item-based。这些信息是可以用来作为推荐的。
单纯的协同过滤是不需要知道歌曲内容的,同样一开始也不需要知道你是个什么样的人。所以这个方法的优势就是其适用性非常强,可以同样用于书本推荐和电影推荐等。
然而这个方法也有一个非常大的缺点,由于它采用的是历史使用数据,这也导致了那些比较流行与大众的内容更容易被推荐,而小众或者不知名的歌曲则基本不会被推荐到。这也使得这类推荐算法得到的结果会稍显无聊。
另一个问题是用户在听歌的时候,歌曲的分布是不纯粹的,当你在听某个专辑的时候其实有很多歌并非是你喜欢的,另外专辑中有很多类似转场的音乐的内容其实对于推荐来说是无关的。协同过滤并不会考虑着一些问题。
不过综合下来,最大的问题还是那些新歌和非主流的歌曲无法被推荐。这个可以被认为是一个冷启动问题。我们希望能够把合适的新歌及时推荐给用户,或者推荐一个用户从没听说过的乐队。为了这些目标,我们需要寻找一个不一样的方案。
基于内容的推荐
对于歌曲而言,可以获取到的内容信息包括了:标签、歌手、专辑信息、歌词、用户评论以及音频信息本身。在这些信息中,最难高效利用的应该是音频信号本身。在歌曲音频和用户偏好之间有一个较大的鸿沟,需要我们通过各种方法从音频中提取信息,比如一些比较便于提取的像:音乐的类型或者使用的乐器等等。剩余的一些信息稍微难一些,比如歌曲所传达的情绪,歌曲所在的时期。还有一些信息基本从音频是不可获取的:歌手的地区和歌词的主题。
尽管有那么多挑战,但有一点是很清晰的,歌曲的音乐本身会决定了你是否喜欢这首歌。对于歌曲音频信号本身的分析是非常重要且有意义的。
深度学习预测听歌习惯
本文采用的方案是通过现有的协同过滤模型进行训练,训练得到一个回归模型(深度神经网络),可以通过这个模型预测得到每首歌的隐含表达式。
这个方法的理念是根据协同过滤模型把用户和歌曲投影到一个低维度的隐含空间里,歌曲的位置包含了所有影响用户听歌习惯的因素。如果两首歌在这个空间中非常靠近,那么可以说它们是类似的曲目。如果一首歌非常靠近某个用户,那这也许是一个很好的推荐选项(假设用户还没有听过)。如果我们可以通过歌曲的音频预测出歌曲在空间中的位置,那我们就可以在不使用历史数据的情况下推荐音乐了。
训练后的模型可以通过t-SNE算法降维到二维空间用于可视化展示,可以从下图看到,同类型的歌曲会聚集到一起,比如下图中左上角是Rap,而最下方是电子乐。

架构
音乐推荐深度神经网络的架构图如下所示,包含了四个卷积层和三个稠密层,可以看出对于音频和图像,卷积层的设计差别还是非常大的。
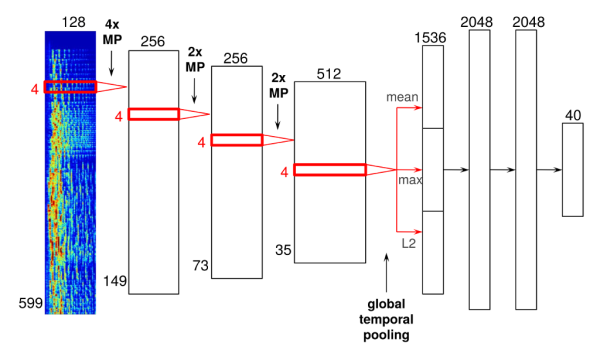
这里省略了细节设计,如果感兴趣的话可以直接阅读原文。
分析
这里可以说是最酷的部分了。到底这个神经网络学到了什么?这些特征到底看起来是什么样子的?使用卷积神经网络来处理这个问题的主要原因是在于,通过音频信号推荐音乐是一个非常复杂的问题,需要很多级的抽象。如同处理图像分类问题一样,连续的神经网络层级可以提取更多复杂的抽象特征。
输入层
首先是神经网络的输入,这里每一次的输入是3秒钟音频片段的频谱。对于一段长音频来说,可以把3秒作为一个时间窗口,把歌曲可以切成N多个片段,把这么多个片段的预测值做一个平均。
这里具体的计算是将音频信号的各个窗口做一次傅里叶变换,每一次傅里叶变换可以构成一帧,这些连续帧连接在一起形成一个声音频谱。最后一步是将频率的时间轴从线性转换为梅尔刻度以降低维度。最终的输入是梅尔频谱(599帧/128个频点)。
隐含层第一层
让我们来观察第一个卷积层(直接对应的是输入频谱),这个卷积层已经学习到了一组filter,而这些filter是可以简单可视化的,如下图所示,负值是红色,正值蓝色,0是白色。每一个filter仅包含4帧的宽度,各个filter之间以垂直红线分割。

横轴是时间轴,纵轴是频率从下至上由低到高
从图像中可以看出,大部分filter在各个频率下,红蓝分布很均匀,说明它们过滤出了歌曲的背景音乐或者是和声部分。而另一些filter则指向性很明确,在某些特定的频率出现升高或降低,说明这些filter探测到了演唱者的人声。
进一步的测试发现了一些有意思的现象(原文中包含了某些测试集的演示),这些filter甚至探测出了音频中特定的音高与和弦,可见这些细微的因素也会影响到人们对于歌曲的偏好。
隐含层最后一层
神经网络的每一层都会从前一层的输入中提取更高维度的抽象并传输给下一层。输出层前一层的全连接网络基本可以挑选出歌曲的子类型了。这里已经不需要通过频谱进行可视化分析了,每一个filter基本可以代表一个特定的分类或者某几个分类。有些filter还很有意思地区分了语言(比如中文歌曲),还有些定位了某种语言下的特定歌曲类型(像西班牙Rap音乐)。
这一层的设计主要参考了AlexNet,可见除了图像分类问题,这些filter对于音频信号的信息提取也非常有用。
输出层
输出层为一个40维的空间向量。我们可以将测试数据放入训练完成后的模型,对每一首歌找到各自距离最相近的其它歌曲,从而可以列出多个基于相似度生成的歌单。从结果来看,效果虽然不是最完美,但还是非常不错的,这里就不列出结果了,感兴趣也可以去原文看。
总结
这篇文章整理了基于内容的深度学习音乐推荐系统,系统的具体设计内容都可以在这篇论文Deep content-based music recommendation里找到。