Machine Learning ve Python
Python veri analizi için mükemmel bir dildir çünkü mevcut olan binerce paket sayesinde veri analistler ve geliştiriciler için en iyi seçimdir.
Machine learning için ihtiyacımız olan bir kaç popüler paketten bahsedelim .
Numpy : Bilimsel hesaplamalarda ve çok boyutlu array işlemleri yapmamızı sağlayan pakettir.
Scipy : Bilimsel şlemlerde sinyal işlemede ve bunu gibi bir çok alanda kullanılmaktadır.
Pandas : Data handling yani veri elde etmek için kullanılır.
Matplotlib : Veri görselleştirmesi için kllanıan bir pakettir.
Seaborn : İstatiksel grafikler için kullanılmaktadır.
Scikits : kullanımı çok geniş alana yayılmıştır örneğin x-ray,görüntü işleme,derin öğrenme ...
Scikits
Bir çok makine öğrenmesi algoritmasına sahiptir size kalan tek şey karşılaştığınız sorunu hangisinin çözeceğini bilmektir. Makine öğrenmesi statik bir alandadır verileri inceliyerek daha sonra verilerden yola çıkarak verilerin sonucunu tahmin etmemizi sağlar.
Nasıl gerekli modüllerin indirebilirim?
İsterseniz bu siteden manuel olarak indirin daha sonra zip dosyasını çıkarıp içindeki dosyaları python modüllerinizin yüklü olduğu dosyaya kopyalayabilirsiniz
Linux için.
sudo apt-get install python3-numpy
sudo apt-get install python3-sklearn
sudo apt-get install python3-pandas
sudo pip install seaborn
Windows için.
pip install seaborn
pip install numpy
pip install pandas
pip install -U scikit-learn
eğer numpy ve pandas yüklü ise herhangi bir hata ile karşılaştıysanız ve pycharm kullanıyorsanız.
pycharm settings sonra interpreter ve daha sonra sağ köşedeki + işaretini tıklayıp modül ismiyle arama yaptıktan sonra indirebilirsiniz.
Anaconda kullanıyorsanız.
conda install modül adını yazarak indirebilirsiniz.
Gerekli paketleri içeri aktaralım.
import numpy as np
import sklearn.linear_model as skl
import pylab as py
import pandas as pd
import seaborn as sb
Diğer algoritmalara nazaran daha kolay biriyle başlamak için linear regression model ile öğrenmeye başlıyoruz.
f(x)=y olduğu bir fonksiyonumuz var biz butada dimension yani boyutu değiştirebiliriz. Mesela F(x,y,z) = w
Şimdi doğrusal gerileme modelini yaratalım.
model = skl.LinearRegression()
# Yeni veriler oluşturalım
xval = np.array([1,2,3,4,5]).reshape(-1,1)
yval = [1,2,3,4,5]
# Modelimizi deneyelim
model.fit(xval,yval)
# Şimdi iste tahmileri inceleyebiliriz.
>>> model.predict(12)
array([ 12.])
>>> model.predict(44
array([ 44])
# Şimdi sonucları inceleyelim ve görselleştirelim.
xval = np.array([1,2,3,3,4,3,6,8,9,10]).reshape(-1,1)
yval = [1,2,3,4,5,6,7,7,9,10]
model.fit(xval,yval)
py.scatter(xval,yval)
Bu kodların şu şekilde bir çıktısı olacaktır.
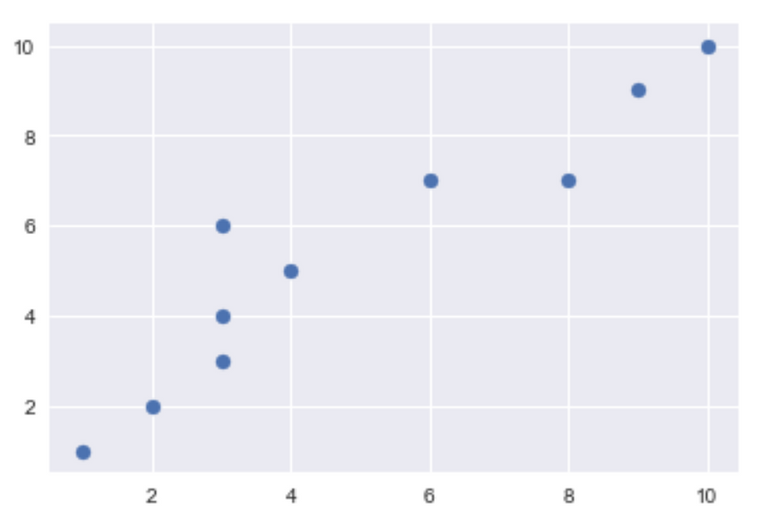
Ama bu grafikteki x ve y arasındaki doğrusal ilişkilerde bazı hatalar vardır, çünkü bu sonuçları az sayıdaki verilerin değerlendirmesi sonucu oluşturmaktadır.
Bu sonuçların daha kesin olması için kullanılan verilerin sayısının artırılması gerekmektedir.
Öyleyse şöyle bir tahmin denemesi alalım
>>> model.predict(12)
array([ 11.66141732])
>>> model.predict(44
array([ 39.88188976])
Çok boyutta çalışmak.
Günlük yaşamda karşılaştığımız problemler çoğunlukla tek boyutlu değildir bundan dolayı şimdiki işlemimize çok boyut kullanarak devam ediyoruz.
samp=np.array([[1,2,300,14],
[9,3,1,95],
[5,7,11,58],
[4,8,14,57],
[2,1,2,27],
[9,9,7,100],
[12,3,21,126],
[29,12,3,309],
[2,40,11,90],
[21,32,4,270],
[7,13,8,79],
[17,2,19,172],
[13,24,13,159]])
df=pd.DataFrame(samp, columns=['X','Y','Z','W'])
Bu kodları çıktısında göreceğiniz üzere X-Y-Z-W bizim kolonlarımızdır. ve her listenin elemanları sırasıyla X-Y-Z-W nun altında çıkarak bir tablo oluşur.
[1,2,300,14] köşeli parantez içindeki ilk veri X=1 Y=2 Z=300 W=14 tür.
Boyutlarımzı oluşturduk ama yukarıdaki kodun çıktısı olarak aldğımız tablo bizim için yeteri kadar görsel değildir ,şimdi Seaborn modülünü kullanrak istatiksel grafiklerimizi elde edelim.
sb.pairplot(df)
Bu kod çıktı olarak bize şu grafiği verecektir.
Verileri bölme ve test etme
Oluşturduğumuz modelin doğruluğunu kontrol etmek isteriz .Bunun için test tahminler yapabiliriz ama şunu göz önünde bulundurmamız gerekir oluşturduğumuz modeldeki verilerin miktarı az olduğundan ötürü tahminimizde ki doğruluk payındaki sapma daha fazla olacaktır.
xval=df[:8][['X','Y','Z']] # only first 8 rows
yval=df[:8][['W']]
model.fit(xval,yval)
5 satır daha ekleyelim
>>> model.predict(df[8:][['X','Y','Z']])
array([[ 68.12886489],
[ 249.65152055],
[ 87.91908068],
[ 175.75498023],
[ 160.41262073]])
Eğer modelimizi değiştirirsek kullanacağımız algoritmayı modelimize göre seçebiliriz daha kesin sonuçlar elde edebiliriz.Modelimizdeki z lerin katsayılar 0,004 ten küçük olduğundan onu kaldırıp bir daha inceleme yapalım.
>>> xval=df[:8][['X','Y']]
>>> yval=df[:8][['W']]
>>> model.fit(xval,yval)
>>> model.predict(df[8:][['X','Y']])
array([[ 68.91717972],
[ 250.38276578],
[ 87.94208619],
[ 175.61505435],
[ 160.85673992]])
Bir önceki sonucumuza oranla daha iyi bir sonuç elde ettik.Tekrar hatırlamamız gereken bir nokta var veri miktarını artırırsanız istediğiniz tahmin sonuçları ona oranla daha doğru çıkar.örnek verecek olursak mesela bir şirkete yatırım yapmak istiyorsunuz sizi ikna etmek için size sadece en iyi satış yaptığı 3 ayın satışlarını gösteren bir tablo veriliyor.Ama bu şirket 5 yıllık bir geçmişe sahip ve bu 3 ay 2. yılının ilk 3 ayıda olabilir şuan şirket batma eşiğinde de olabilir.Yani demek istediğim sizdeki tablo 5 yıllık olsaydı şirketin bu uzun sürede hangi yılda satışlar yükselmiş bunun dönemsel oranı nedir veya black friday gibi günlerde ne kadar satış ne kadar satış yapmış vs vs bilgileri öğrenebilir ve yatırımınız daha kararlı ve reel veriler üzerinden tamamlanmış olurdu.
Congratulations, your contribution has been approved.
You can contact us on discord.
[coogger-moderator]
Congratulations @baristutakli! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
To support your work, I also upvoted your post!
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPCongratulations! This post has been upvoted from the communal account, @minnowsupport, by baristutakli from the Minnow Support Project. It's a witness project run by aggroed, ausbitbank, teamsteem, theprophet0, someguy123, neoxian, followbtcnews, and netuoso. The goal is to help Steemit grow by supporting Minnows. Please find us at the Peace, Abundance, and Liberty Network (PALnet) Discord Channel. It's a completely public and open space to all members of the Steemit community who voluntarily choose to be there.
If you would like to delegate to the Minnow Support Project you can do so by clicking on the following links: 50SP, 100SP, 250SP, 500SP, 1000SP, 5000SP.
Be sure to leave at least 50SP undelegated on your account.