业务现状分析
我们有很多servers和systems,比如network device、operating system、web server、Application,他们会产生日志和其他数据,如何使用这些数据呢?可以把源系统的日志数据移到分布式的存储和计算框架上处理,如何解决?
- shell cp hadoop集群的机器上,hadoop fs -put ...,有一系列问题,容错、负载均衡、高延时、压缩等。
- Flume,把A端的数据移到B端,通过写配置文件可以cover掉大部分的应用场景。
Flume概述
Flume is a distributed, reliable, and available service for efficiently collecting(收集) aggregating(聚合), and moving(移动) large amounts of log data.
webserver(源端) ===> flume ===> hdfs(目的地)
Flume架构及核心组件
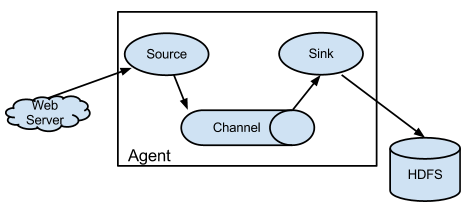
- Source, 收集
- Channel, 聚集
- Sink, 输出
Flume环境部署
Flume安装前置条件,版本Flume 1.7.0,
- Java Runtime Environment - Java 1.7 or later
- Memory - Sufficient memory for configurations used by sources, channels or sinks
- Disk Space - Sufficient disk space for configurations used by channels or sinks
- Directory Permissions - Read/Write permissions for directories used by agent
安装jdk,下载,解压到目标目录,配置到系统环境变量中~/.bash_profile,source让其配置生效,验证java -version。
安装Flume,下载,解压到目标目录,配置到系统环境变量中~/.bash_profile,source让其配置生效,修改配置文件$FLUME_HOME/conf/flume-env.sh,配置Flume的JAVA_HOME,验证flume-ng version。
Flume实战案例
应用需求1:从指定网络端口采集数据输出到控制台。
技术选型:netcat source + memory channel + logger sink。
使用Flume的关键就是写配置文件,
- 配置Source
- 配置Channel
- 配置Sink
- 把以上三个组件串起来
a1: agent的名称,r1: source的名称,k1: sink的名称,c1: chanel的名称
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.169.100
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:一个source可以输出到多个channel,一个sink只能从一个channel过来。
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent,
# bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
bin/flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf/myconf \
--conf-file $FLUME_HOME/conf/myconf/example.conf \
-Dflume.root.logger=INFO,console
配置telnet客户端与服务端,
rpm -qa | grep telnet
yum list | grep telnet
yum install -y telnet telnet-server
# 将telnet服务设置为默认启动(可选)
cd /etc/xinetd.d
cp telnet telnet.bak
vi telent
disable = no
# 启动telnet和验证
service xinetd start
telnet localhost
使用telnet进行测试,
telnet 192.168.169.100 44444
hello
world
Event是Flume数据传输的基本单元,Event = 可选的header + byte array。
应用需求2:监控一个文件实时采集新增的数据输出到控制台。
Agent选型:exec source + memory channel + logger sink。
# exec-memory-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/data/flume_sources/data.log
a1.sources.r1.shell = /bin/sh -c
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent,
# bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
bin/flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf/myconf \
--conf-file $FLUME_HOME/conf/myconf/exec-memory-logger.conf \
-Dflume.root.logger=INFO,console
验证,
echo hello >> data.log
echo world >> data.log
应用需求3:将A服务器上的日志实时采集到B服务器。
日志收集过程:
- 机器A上监控一个文件,当我们访问主站时会有用户行为日志记录到access.log中。
- avro sink把新产生的日志输出到对应的avro source指定的hostname和port上。
- 通过avro source对应的agent将我们的日志输出到控制台(Kafka)。
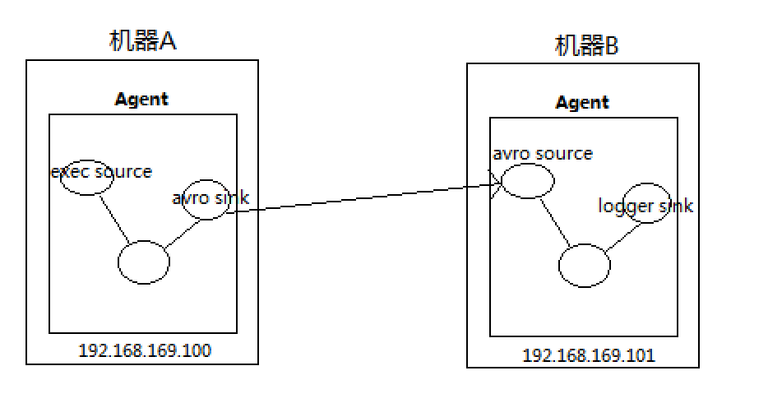
技术选型:
exec-memory-avro.conf: exec source + memory channel + avro sink
avro-memory-logger.conf: avro source + memory channel + logger sink
# exec-memory-avro.conf
# Name the components on this agent
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# Describe/configure the source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -F /export/data/flume_sources/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# Describe the sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = 192.168.169.100
exec-memory-avro.sinks.avro-sink.port = 44444
# Use a channel which buffers events in memory
exec-memory-avro.channels.memory-channel.type = memory
# Bind the source and sink to the channel
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
# avro-memory-logger.conf
# Name the components on this agent
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# Describe/configure the source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = 192.168.169.100
avro-memory-logger.sources.avro-source.port = 44444
# Describe the sink
avro-memory-logger.sinks.logger-sink.type = logger
# Use a channel which buffers events in memory
avro-memory-logger.channels.memory-channel.type = memory
# Bind the source and sink to the channel
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
验证,先启动avro-memory-logger.conf,因为它监听192.168.169.100的44444端口,
# bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
bin/flume-ng agent \
--name avro-memory-logger \
--conf $FLUME_HOME/conf/myconf \
--conf-file $FLUME_HOME/conf/myconf/avro-memory-logger.conf \
-Dflume.root.logger=INFO,console
# bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
bin/flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf/myconf \
--conf-file $FLUME_HOME/conf/myconf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console
本文首发于steem,感谢阅读,转载请注明。
微信公众号「数据分析」,分享数据科学家的自我修养,既然遇见,不如一起成长。

读者交流电报群
知识星球交流群
@padluo, 来来,老司机教你怎么成为cn-reader区的牛人:把 @rivalhw 的帖子全部读一篇,就算入门了...
之前我司也有考虑过研究一下flume ,感觉和hadoop配合很好用。感觉未来使用它的人会越来越多。
我是研究实时处理的框架时,配合Flume+Kafka。
Congratulations @padluo! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
To support your work, I also upvoted your post!
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOP