Hola, he decidido aperturar este tema, pues tengo experiencia diseñando un cluster y la información que se puede encontrar actualmente en la web en español es muy poca.
Si estás leyendo este artículo y no tienes idea de lo que es un cluster, te pondré en contexto.
El término cluster proviene del inglés y tiene diversos sentidos según distintos autores, aunque todos se relacionan entre sí. La definición más extendida y conocida del término clúster en general es la de Michael Porter, llamándolo una herramienta de competitividad basada en la cooperación de sus miembros.
En el ámbito de la informática, un cluster representa un conjunto de computadoras independientes, interconectadas entre sí, que actúan como una sola computadora. Como consecuencia se logra aumentar el rendimiento, al trabajar varios equipos juntos y sumar sus potenciales.
Los sistemas de cluster proporcionan tolerancia a fallos, escalabilidad y alta disponibilidad a servicios de producción crítica según sea la necesidad. Los clúster de alta disponibilidad se encargan de proveer los servicios de manera ininterrumpida al cliente, independientemente de las fallas que puedan ocurrir en el sistema. El principio de la alta disponibilidad es la redundancia , pues al existir más de un nodo redundante (que maneja la misma data que el primario) es posible, en caso de ocurrir alguna falla en el nodo primario, trasladar el servicio desde el nodo de cluster erróneo a otro nodo completamente funcional y de esta manera continuar prestando el servicio. Este procedimiento ocurre de manera imperceptible para el usuario.
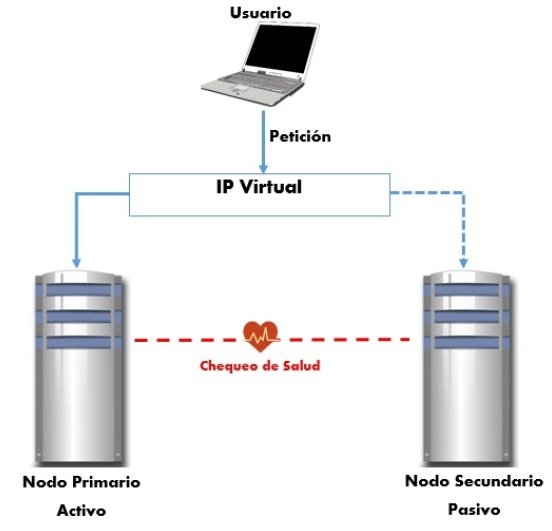
Cuando inicié mi proyecto de diseño de cluster, no tenía la más mínima idea de lo que esto se trataba. Es decir, si estás en la misma posición ahora mismo, tranquilo, ¡Puedes hacerlo!.
Primero que nada, debes elegir la topología que más convenga según lo que necesites "clusterizar". Las dos topologías más utilizadas y conocidas son activo/activo y activo/pasivo.
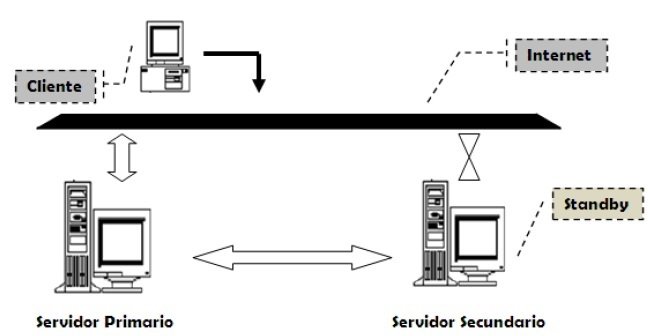
La topología activo/pasivo consiste en dar el rol de principal a un sólo nodo, el cuál como su nombre lo define, se encuentra activo ejerciendo el control sobre los recursos del cluster, mientras el resto de los nodos pertenecientes al cluter se mantienen en un estado de espera, actualizándose constantemente con la información que maneja el principal pero sin intervenir en la prestación de los servicios. Si ocurre un inconveniente en el nodo principal, ya sea fallas de energía, hardware, etc, alguno de los nodos secundarios (según el orden de prioridad configurado) tomará el control de los recursos y el servicio seguirá disponible de manera ininterrumpida e imperceptible para el usuario.
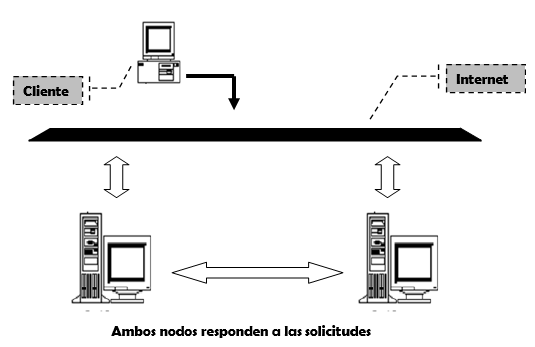
Por su parte, en la topología activo/activo todos los nodos integrantes del cluster participan activamente en la prestación de los servicios, diviendo la carga de recursos entre los mismos. Si algún nodo de ve imposibilitado, los recursos que este maneja son asignados al resto de los nodos activos y el servicio continúa disponible.
En este artículo, la topología a la cuál se hará referencia es la topología activo/pasivo.
¿Todo bien hasta ahora? ¡Continuemos!
El hardware a utilizar va a depender de la cantidad de nodos que se quieran clusterizar, el mínimo es de dos nodos, para lo que necesitaríamos dos CPU con una capacidad de procesamiento también dependiente de la cantidad de peticiones que se esperan recibir en cada nodo.
El software va a depender del sistema operativo bajo el cual se quiere trabajar. En este caso, CentOS es una distribución libre del sistema empresarial RHE de Linux. Necesitaremos una aplicación de servidor web, un sistema de archivos, un software de réplica de datos, una aplicación de base de datos y por supuesto un software de cluster.
Según lo mencionado, las aplicaciones seleccionadas para este diseño son:
- Servidor web Apache.
- Filesystem cfg.
- DRBD para replicar los datos.
- MySQL.
- Pacemaker y Corosync cómo software de cluster (trabajan en conjunto).
La configuración de las aplicaciones se debe realizar iniciando por el software de cluster. Debemos tener en cuenta que previamente debe existir una red entre los nosos que formarán parte del cluster y a cada uno se le debe asignar una IP estática dentro de esta red. Una vez establecido el cluster entre los nodos, el siguiente paso consiste en habilitar el servidor web en uno de los nodos. Posteriormente, en el mismo modo se configura el replicador de datos DRBD y si todo va bien, podremos visualizar los datos en todos los nodos al finalizar la configuración.
Al trabajar con un sistema redundante dónde es importante controlar cómo se almacenan y recuperan los datos en caso de producirse alguna falla en el servidor, se debe utilizar un sistema de archivos. El sistema de archivos se encargará de
inspeccionar la organización de los archivos almacenados en el disco duro o partición a través del sistema operativo. La configuración del sistema de archivos constituye el siguiente paso en la creación de nuestro cluster de alta disponibilidad.
Por último, se debe añadir el sistema de gestión de base de datos MySQL, y finalmente ya contaremos con todas las herramientas de cluster instaladas y configuradas, trabajando en conjunto y podremos iniciar las pruebas de funcionamiento de nuestro cluster.
No es tan difícil, ¿O sí?
El proceso de creación de un cluster en general no es complicado, pero si son necesarios procedimientos específicos de configuración para cada software que deben ser explicados con absoluto detalle. Si te interesa conocer más a fondo estos procedimientos, házme saber en los comentarios y con gusto te ayudaré!
Gracias por leerme.
Congratulations @nazapws! You received a personal award!
Click here to view your Board
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness and get one more award and increased upvotes!
Congratulations @nazapws! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!