The Secretary of the Air Force, Heather Wilson, has embarked on an audacious (and in my opinion, much needed) initiative to significantly reduce unnecessary Air Force instructions (AFIs).
A primary goal of this effort is to remove overly prescriptive operating instructions as a way of empowering Air Force commanders to accomplish mission objectives through the application of good judgement and ingenuity.
General VeraLinn “Dash” Jamieson, the Deputy Chief of Staff for Intelligence, Surveillance and Reconnaissance (ISR), has sprinted out front of this endeavor by rescinding several AFIs from the Air Force Intelligence enterprise.
In September, four AFIs related to Air Force Intelligence operations were rescinded through an official product announcement. One of the instructions purged in this push was AFI 14-119, which was issued on May 4, 2012 to outline “Intelligence Support to Force Protection”.
During my time as an active duty Air Force intelligence officer, I spent many hours combing through AFI 14-119 in order to make certain that my unit was supporting Air Force Security Forces personnel in compliance with these requirements.
As AFI 14-119 is now simply another relic of Air Force legacy, archived at Muir S Fairchild Research Information Center (the Air University Library), I thought I would take some time to use modern data science methods to produce descriptive analytics and qualitatively capture metrics about this document and the types of language it contains.
What follows below are brief explanations of how I gathered statistics and built visualizations with the text in AFI 14-119.
Manual Inspection
AFI 14-119 is 28 pages in length (20 pages of instruction, and an 8 page attachment containing supporting definitions and documentation). This data can be gleaned from a quick manual scan through the PDF.
All AFIs are distributed in PDF format, so my next step was to convert the document to raw text so that I could parse and analyze the content.
Tokenization
After I had the PDF converted to raw text, I tokenized the document. Tokenization is Natural Language Processing (NLP) method that breaks a stream of text into words, phrases, and sentences.
A raw tokenization found 12,641 “words” in the document. These aren’t truly words though, because the numeric section identifiers in the document also got tokenized through this process. This first attempt at tokenization was really just breaking the document into distinct piece of text that were separated by spaces.
In order to get a more accurate word count, I programmatically iterated through the list of tokens and discarded any entry that wasn’t purely alphabetic. This yielded a new list with a count of 9,152 words. It is interesting to note here that the U.S. Constitution is only 4,543 words, and that includes the signatures of America’s founding fathers.

In the field of NLP, there is a concept called “stop words”. Stop words are some of the most common, short function words used in communication. These are words like: as, the, is, at, which, and on. While these words are necessary for communicating with proper grammar, they aren’t particularly useful for indexing a corpus of words for data science purposes.
When I ran our list of 9,152 words against a function to remove 179 common stop words, I was left with 6,548 words. With this "clean" list of words, I began looking for commonality and frequency. Below is a table that tallies the ten most common words found in the “cleaned” corpus of 6,548 words. It is interesting to note that these 10 words account for 891 of the total words used in the entire document.
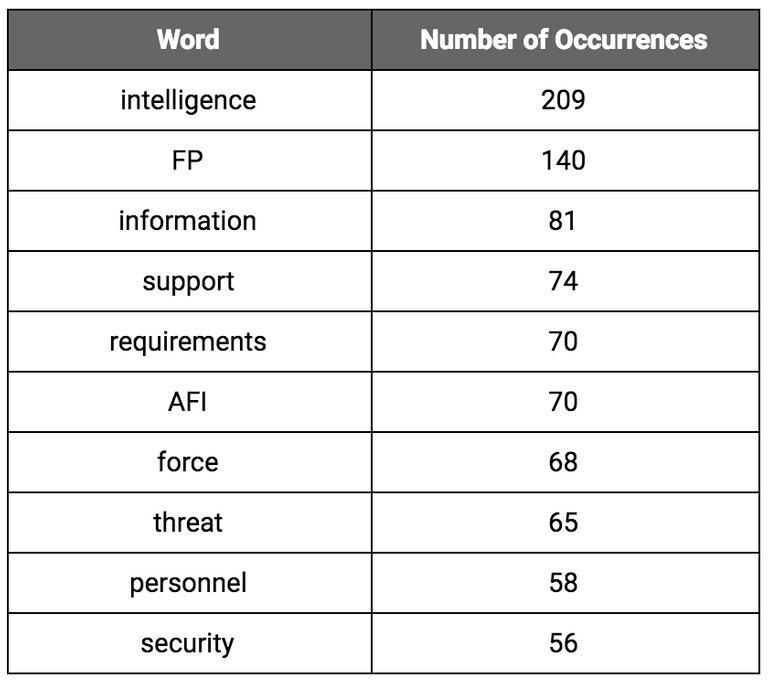
The four meaningful words from the AFI title (“to” is a stop word), “Intelligence Support to Force Protection”, appear in the document a total of 378 times. This means that nearly 6% of the content in this document was just a rehash of the document’s title.
Visualization
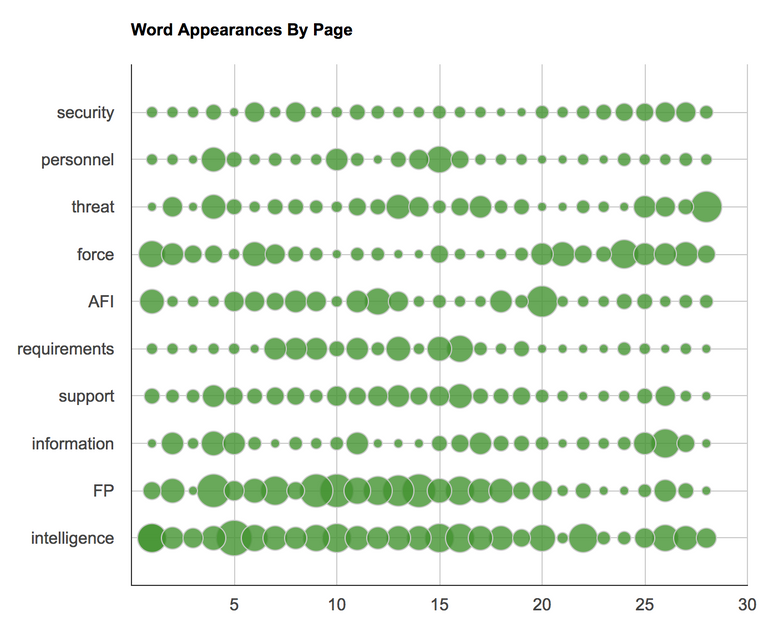
A bubble chart is a great way to visualize text usage in the AFI. In the bubble chart below, you will find each of the ten most common words from the document plotted by page. Each bubble is sized relative to the number of appearances that word made on a respective page.
With the text from AFI 14-119 tokenized and "cleaned", I could generate a word cloud to visualize the data. A word cloud (or tag cloud as it is sometimes called) is a way to quickly perceive the relative prominence of terms in a corpus of text. In the word cloud below, the importance (commonality) of each word is conveyed through the font size.

N-Grams
In NLP, an n-gram is a neighboring sequence of items from a given sample of text. The “n” simply refers to the number of items in the sequence.
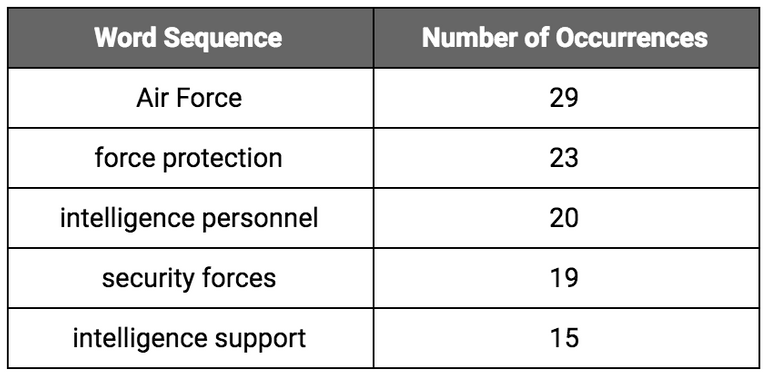
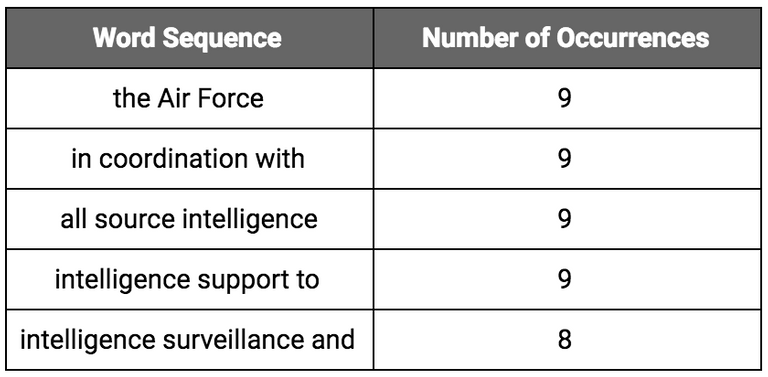
For this exploration I was interested in the bigrams, trigrams, and quadgrams used in the document (sequences of two, three, or four words used together). In order to identify the n-grams that appeared naturally in the document, I reverted to using the token list that still contained all of the stop words.
Here are the five most common bigrams in the AFI:
Here are the five most common trigrams in the AFI:
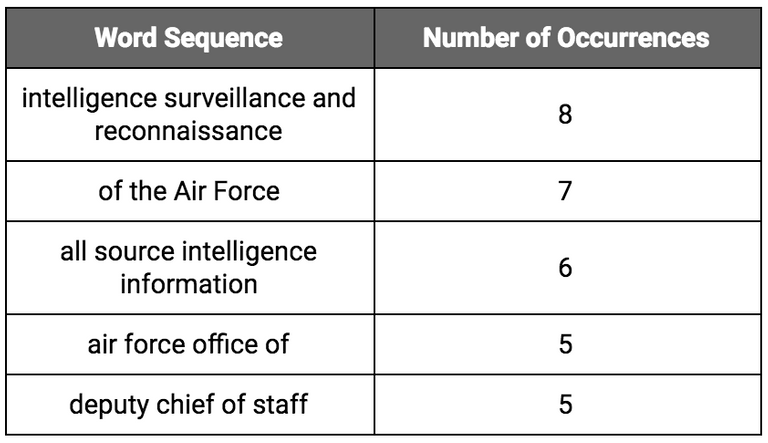
Here are the five most common quadgrams in the AFI:
Salience
My next task was to break the document into sentence tokens. The text from AFI 14-119 parsed into 658 sentences. With each sentence represented as a token, I leveraged the Google NLP API to analyze all sentences for relevant insights. One of these insights is entity level identification and salience scoring.
An entity represents a phrase in the text that is a known entity in Google’s knowledge graph, such as a person, an organization, or location. The Google NLP API identified 2,496 entities in AFI 14-119.
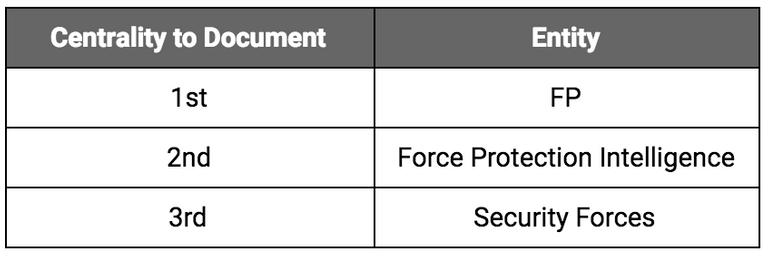
Each of these entities was then evaluated for salience. A salience score provides information about the importance or centrality of that entity to the entire document. The higher the salience score, the more important or central that entity is to the entire text.
Below are the three most salient entities identified in the document (in order of centrality):
Sentiment
The Google NLP API also provides sentiment scoring for each entity identified in the text it evaluates. Sentiment analysis attempts to determine the overall attitude (positive or negative) associated with how an entity is referenced in a document.
The Google NLP API found 2,292 entities referenced with negative sentiment. Below is a word cloud built from all of the entities that involved negative sentiment (the larger the text, the more times that entity was referenced negatively).

Conclusion
Descriptive analytics is a stage/phase of data science that creates a summary of historical data in an effort to summarize useful information. When applied to AFI 14-119 these methods glean interesting metrics and insight into how language was used in the now rescinded instruction. As the Air Force continues to remove outdated and overly prescriptive guidance, data science is one way to capture quantitative details about what exactly is being rescinded.
Congratulations @seanmaday! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!