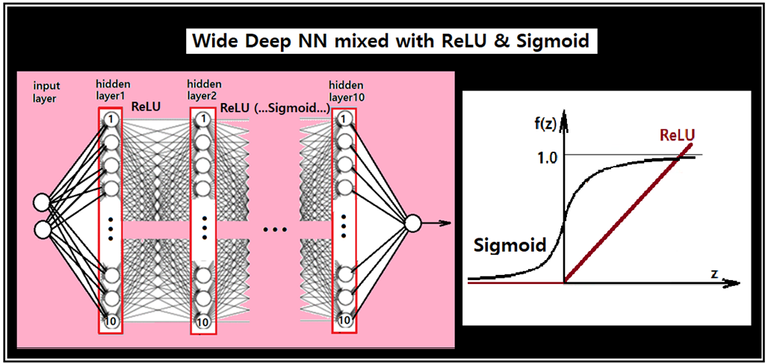
Learning rate = 0.1, 학습횟수(tainning) 10,000회 조건 하에서 XOR logic 문제를 Depth가 10인 즉 10개의 layer들을 가지면서 각 layer당 10개의 노드를 가지는 Fully connected NN(뉴럴 네트워크)을 적용해서 실패한 결과를 주었던 예제를 ReLU 함수를 사용하여 다시 다루어 보았다. 실패의 원인은 NN 레이아웃의 구조적 문제가 아니라 layer 사이에 도입되는 Sigmoid 함수의 특성에 기인하는 것이란 점을 지적하였다. Wide deep NN 코드의 레이아웃을 보면 각 layer 별 처리 단계 마다 Sigmoid 가 있음을 알 수 있다.
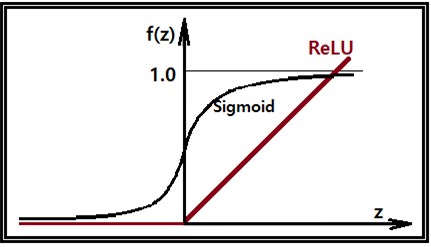
각 layer 별로 어떤 노드에서 값이 마이너스(-)의 값을 가지게 되면 Sigmoid 처리 결과 거의
∼0에 가까운 값을 주며 반면에 값이 아무리 큰 양의 값이라 해도 1.0 보다 작은 값을 가지게 되므로 어쨌든 결국 1.0 보다 작은 값을 10번 계속 곱하다 보면 거의 ∼0이 될 가능성이 대단히 높다. 실제 10개의 layer를 가지는 NN 계산 결과를 보면 정답을 주는 경우 보다 실패하는 경우가 거의 대부분이다. 반면에 RelU = max( 0, x) 를 사용하게 되면 어떤 노드에서 값이 마이너스(-)의 값을 가지게 되면 물론 0 으로 처리 되지만 반면에 값이 0과 1 사이라면 그대로 반영이 되고 특히 큰 양의 값이면 있는 그대로 계산에 반영이 되어 1.0 보다 작아질 가능성은 없다.
10개의 은닉층을 가지는 Wide deep NN을 대상으로 learning rate = 0.1, 학습횟수 10,000 회로 XOR 로직 문제를 풀어 보도록 한다.
일차적으로 Sigmoid 함수로 도배가 되어 있는 Wide deep NN을 대상으로 실패하는 여부를 각자 확인해 보도록 하자. Random number를 사용하기 때문에 결과에 변동이 있을지도 모르지만 요즈음 윈도우즈 10 컴퓨터로 한 번 실행에 1분 정도 걸리므로 대체로 10번 정도 실행 시켜보아 10번 다 정답이 나오면 성공이고 한번이라도 오답이 나오면 실패로 간주하면 된다. 이미 지난번 블로그 포스팅에서 확인이 되었다.
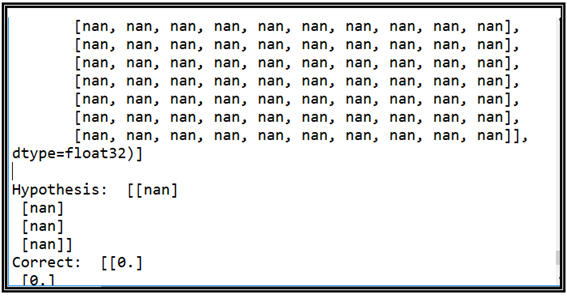
10개의 은닉층에 사용된 Sigmoid 함수를 모조리 ReLU 로 바꾸어 실행해본 결과 수많은 nan 이 생성되었는데 이는 10번에 걸쳐 큰 수를 계속 곱하게 된 것이 원인인 듯하다. 이 단계에서 혹 ReLU 가 Sigmoid를 대신할 수 없는 것 아니가하는 강한 의구심이 들었던 것도 사실이다.
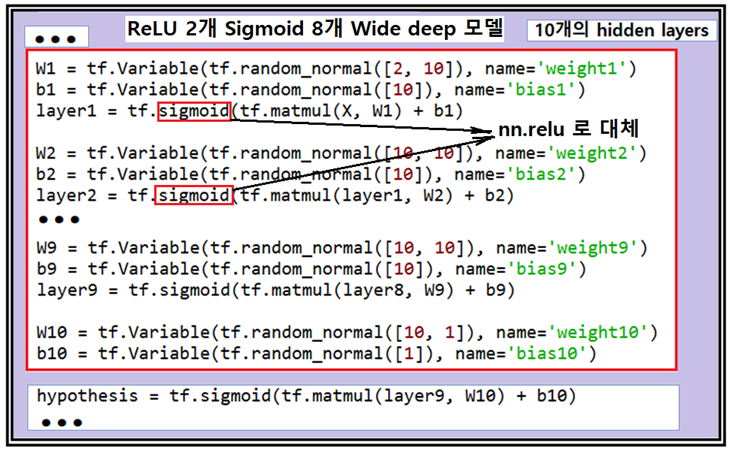
전략을 바꾸어 첫 번째 layer 로부터 ReLU 로 바꾸어 실행해 보았으며 두 번째 layer 까지 성공적이었다. 더 늘려 나가면 어느 layer 단계에서부터 NaN 이 출력되는지 알 수 있을 것이다.
반대로 layer1부터 layer7까지는 Sigmoid를 그대로 두고 layer8과 layer9에 만 한정하여 ReLU를 적용한 결과 10번 실행해 보면 대부분 싷패한 결과를 주었다. 마지막 은닉 층 처리에는 결과가 0∼1 사이로 나와야 하므로 반드시 Sigmoid를 쓰도록 해야 할 것이다.

ReLU 2개를 선두에 배치하여 성공적인 결과를 얻었으나 앞으로 CNN 과 같은 복잡한 머신 러닝에서처럼 ReLU 가 중간 중간 여러번 나타나는 경우가 있으므로 가장 단순한 XOR 문제를 대상으로 Computation 연습이 필요할지도 모른다.
뉴럴 네트워크 머신 러닝 계산에서는 앞 부분에서 잘못되면 당연히 실패하는 결과를 낳게 될 것이다. 이러한 의미에서 선두 부분에 ReLU를 2회 연속 적용해본 결과 성공적이었던 반면에 후반부에 ReLU를 2회 적용했지만 실패한 결과를 주었다. 결국 선두부분의 연산 성공 여부에 따라 Wide deep NN 전체 결과 연산 성공 여부가 결정된다는 점이다. 이런 점에서 2회의 ReLU 적용은 성공적이었다고 평가된다. 하지만 ReLU를 10번째 layer까지 적용할 경우 NaN 이 초래되므로 ReLU도 나름 문제점이 있으며 보다 안정적으로 NN 계산이 가능한 대안을 찾아 제시하기로 한다, 이 부분 내용에 관해서는 필자가 지금까지 1년 넘게 머신 러닝 서적이나 인터넷 검색을 해본 결과 아무런 자료를 찾지 못했으므로 필자가 고안한 정식화(formulation) 및 코딩 내용을 제시해 보도록 하겠다.
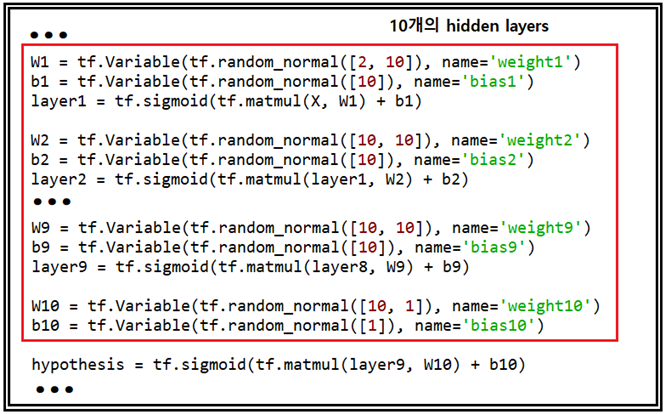
xor_nn_01 코드를 10개의 은닉층을 가지도록 변형한 코드 즉 wide_deep_10th.py 코드에서 선두 부분에 Sigmoid를 ReLU로 변경한 코드를 첨부하였으니 다운 받아 실행해 보기 바란다. 혹 indentation이 훼손되었으면 정확히 복구하여 실행해 보도록 하자.
#Relu2_smd8_wide_deep_10th.py
import tensorflow as tf
import numpy as np
tf.set_random_seed(777) #for reproducibility
learning_rate = 0.1
x_data = [[0, 0],
[0, 1],
[1, 0],
[1, 1]]
y_data = [[0],
[1],
[1],
[0]]
x_data = np.array(x_data, dtype=np.float32)
y_data = np.array(y_data, dtype=np.float32)
X = tf.placeholder(tf.float32, [None, 2])
Y = tf.placeholder(tf.float32, [None, 1])
W1 = tf.Variable(tf.random_normal([2, 10]), name='weight1')
b1 = tf.Variable(tf.random_normal([10]), name='bias1')
layer1 = tf.nn.relu(tf.matmul(X, W1) + b1)
W2 = tf.Variable(tf.random_normal([10, 10]), name='weight2')
b2 = tf.Variable(tf.random_normal([10]), name='bias2')
layer2 = tf.nn.relu(tf.matmul(layer1, W2) + b2)
W3 = tf.Variable(tf.random_normal([10, 10]), name='weight3')
b3 = tf.Variable(tf.random_normal([10]), name='bias3')
layer3 = tf.sigmoid(tf.matmul(layer2, W3) + b3)
W4 = tf.Variable(tf.random_normal([10, 10]), name='weight4')
b4 = tf.Variable(tf.random_normal([1]), name='bias4')
layer4 = tf.sigmoid(tf.matmul(layer3, W4) + b4)
W5 = tf.Variable(tf.random_normal([10, 10]), name='weight5')
b5 = tf.Variable(tf.random_normal([10]), name='bias5')
layer5 = tf.sigmoid(tf.matmul(layer4, W5) + b5)
W6 = tf.Variable(tf.random_normal([10, 10]), name='weight6')
b6 = tf.Variable(tf.random_normal([10]), name='bias6')
layer6 = tf.sigmoid(tf.matmul(layer5, W6) + b6)
W7 = tf.Variable(tf.random_normal([10, 10]), name='weight7')
b7 = tf.Variable(tf.random_normal([10]), name='bias7')
layer7 = tf.sigmoid(tf.matmul(layer6, W7) + b7)
W8 = tf.Variable(tf.random_normal([10, 10]), name='weight8')
b8 = tf.Variable(tf.random_normal([10]), name='bias8')
layer8 = tf.sigmoid(tf.matmul(layer7, W8) + b8)
W9 = tf.Variable(tf.random_normal([10, 10]), name='weight9')
b9 = tf.Variable(tf.random_normal([10]), name='bias9')
layer9 = tf.sigmoid(tf.matmul(layer8, W9) + b9)
W10 = tf.Variable(tf.random_normal([10, 1]), name='weight10')
b10 = tf.Variable(tf.random_normal([1]), name='bias10')
hypothesis = tf.sigmoid(tf.matmul(layer9, W10) + b10)
#cost/loss function
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) *
tf.log(1 - hypothesis))
train = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cost)
#Accuracy computation
#True if hypothesis>0.5 else False
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
#Launch graph
with tf.Session() as sess:
#Initialize TensorFlow variables
sess.run(tf.global_variables_initializer())
for step in range(10001):
sess.run(train, feed_dict={X: x_data, Y: y_data})
if step % 100 == 0:
print(step, sess.run(cost, feed_dict={
X: x_data, Y: y_data}), sess.run([W1, W2]))
#Accuracy report
h, c, a = sess.run([hypothesis, predicted, accuracy],
feed_dict={X: x_data, Y: y_data})
print("\nHypothesis: ", h, "\nCorrect: ", c, "\nAccuracy: ", a)
'''
'''
짱짱맨 호출에 응답하여 보팅하였습니다.
짱짱맨은 저자응원 프로그램입니다. 더 많은 저자 분들에게 더 큰 혜택을 드리고자 스파임대 스폰서를 받고 있습니다. 스폰서 참여방법과 짱짱맨 프로그램에 관해서는 이 글을 읽어 주세요. 기업형 예비증인 북이오(@bukio)가 짱짱맨 프로그램을 운영하고 있습니다. 여러분의 증인 보팅은 큰 힘이 됩니다. Vote for @bukio