Over the last couple of days I've been going back and forth with some of Steem's technical experts and full node witnesses @themarkymark, @anyx & @bobinson exploring the question of whether full RPC steem nodes can be run on relatively inexpensive (~$2k capital cost) high end desktop systems (HEDT) rather than renting high end servers costing $10-15k per month.
While some may wonder why I am focussing on this issue arising from Ned's bombshell announcement, given the many concerns that arise (delay in SMTs etc), there is a very good reason.
Ned's post has revealed the very concerning reality that our whole wonderful Steem ecosystem is highly dependent on Steemit Inc running full RPC nodes which provide the APIs that all the amazing Steem frontends and apps (@steempeak, @steemmonsters, @utopian-io, @steemworld, @partiko, @esteem, @actifit, @steemhunt etc) rely upon.
Steemit Inc is spending around $2M per year on outsourced (rented) infrastructure costs, of which full nodes are a big component. This is simply unsustainable in a low Steem price environment. These fiat costs are covered by Steemit Inc selling Steem and this pushes the price of Steem down further.
It is a vicious cycle that can only be solved by dramatically cutting infrastructure costs by properly decentralising Steem.
Only a few witnesses (including @themarkymark & @anyx) are running full RPC nodes to supplement Steemit Inc. This is because currently it is very expensive to run a full node as they currently require massive amounts of RAM (256Gb+) only available on expensive server grade computers to run efficiently due to the huge size of the Steem blockchain. This is a crucial failure of decentralisation which must be resolved if Steem is to thrive.
shown that it is possible to cut costs substantially by purchasing (rather then renting) a very high end 512Gb Xeon Gold server for around $12k, and run a full RPC node on it. This is a vast improvement over spending the same amount PER MONTH as Steemit Inc has been doing.@anyx has
However it is not enough for full decentralisation.
$12k upfront plus a couple hundred $ monthly for hosting is a big commitment that many witnesses, especially those outside the top 20, will not be willing or able to make.
To fully decentralise and remove central points of failure and control, all crucial elements of a decentralised network need to be able to be run on consumer grade equipment.
This is why in the Proof of Work (PoW) blockchain world, true believers in decentralisation support GPU based mining and oppose ASICs. If the equipment needed to participate fully in a decentralised blockchain network is not readily accessible and within the financial means of large numbers of people, then it will naturally centralise and become vulnerable.
In addition to the cost and accessibility issues, there are some real technical advantages of HEDT machines for blockchain applications. HEDT machines have much faster single core performance than server CPUs and single core performance is crucial to Steem nodes, particularly in the time consuming replay function, performed every time there is an outage or upgrade.
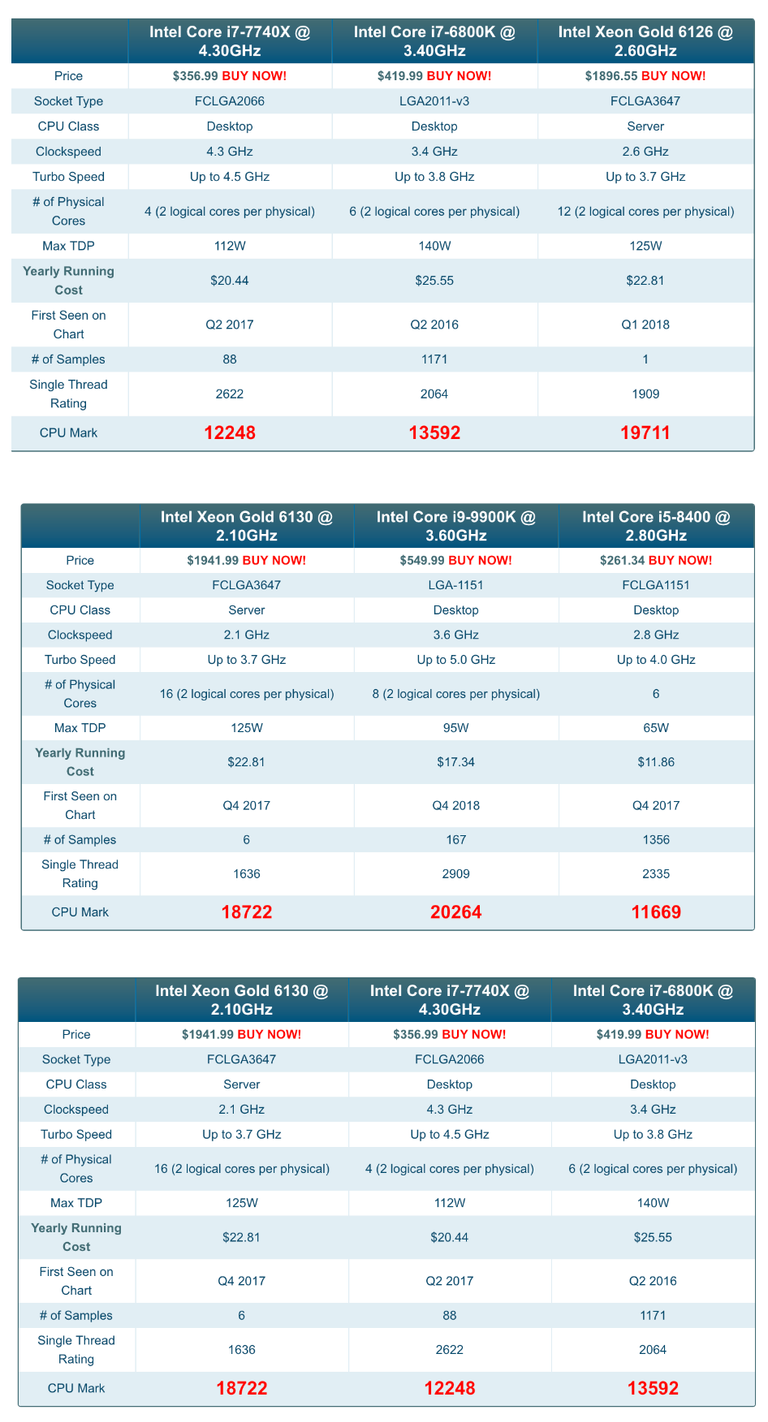
The tables below show the much higher single thread performance of HEDT CPUs costing $250-$550 like the:
- Intel Core i7-7740X (max RAM 128Gb, Optane ready)
- i7-6800K (max RAM 128Gb)
- i9-9900K (max RAM 64Gb, Optane ready)
- i5-8400 (max RAM 64Gb, Optane ready)
compared to server CPUs such as XEON Gold 6126 or 6130 costing more than $1900.
AMD Ryzen Threadripper HEDT CPUs are also an option, with the advantage that they support ECC memory, but the disadvantage of lower single thread performance vs Intel HEDT CPUs.
There are two ways that HEDT class machines may be able to be used to provide full nodes:
It is crucial however that tests are done on consumer grade Optane, as server grade is 3x the price for marginal performance increase.By supplementing RAM with Intel Optane memory. @bobinson is doing testing on this.By "sharding" full nodes into multiple HEDT class machines, splitting the APIs between them to provide redundancy for all but the most lightly used APIs. This sharding could be done within the one witness's setup and/or across multiple cooperating witnesses.
Currently consensus data (which must be on every machine) is 45Gb and the total for all APIs is 202Gb. Thus each HEDT class machine would have around 80Gb available for running APIs.
- Partial redundancy (of the most critical or highly used APIs) could be achieved with 3 HEDT class machines (~$6k)
- Full redundancy (2 machines running each API) could be achieved with 5 HEDT class machines (~$10k). Even taking into account the somewhat lower reliability of HEDT class machines, the overall per witness reliability and performance of such a setup would be higher than a single Xeon Gold server (as well as still being cheaper).
But it is important not to get too focussed on reliability levels.
There is always a cost / reliability tradeoff. However, the whole point of decentralisation is to have a very large number of (implicitly lower reliability) nodes in the system so a few can go down without problems to the overall system.
While no individual witness wants to have an unreliable node, the system as a whole is designed so another witness steps in if one of the main witnesses servers go down. The consequence is just a decrease in the earnings of that witness, not an outage of the Steem blockchain.
It is simply not necessary to have the same levels of reliability and individual witness level redundancy in a properly decentralised system as it is in a centralised system.
These days all computers are very reliable and the difference between consumer grade and enterprise grade reliability is huge in dollar terms but very small in actual percentage terms.
Decentralised systems do not need enterprise grade reliability at the individual node level, because decentralisation provides much higher reliability at the system level.
I am pleased to announce that I am joining the @Utopian-io team as CFO where I will be applying my financial, technical legal and decentralisation expertise to take Utopian and Steem to an even higher level.
I look forward to working with all concerned parties on Steem, to resolve these and other challenges facing us and move forward to the bright future that I saw at SteemFest.
And don't forget to:
Signup for the Crypto Class Action against Facebook & Google's Crypto Ad Ban
https://gateway.ipfs.io/ipfs/Qmd9Lme3FP2CMxtRbuQWCuiVdpWNp6EdKa5BkQ4gqRZ4mz
What are their URLs?
As I admitted in one of my previous videos, I also rely heavily on Steemit's API for my fulltimebots.
Regarding full-nodes, if ~300GB is needed to be stored in memory how bad would it be if a SSD harddrive is used as swap on a 64GB machine? Those don't cost much but would the performance hit be too great?
We need to find a clever way to prune this db asap ...
I did 64Gb with raid 0 nvme (2) and killed it after 3.5 weeks of replay.
Has any analysis been done on precisely what computational elements of the replay process are taking so much time? It’s single core speed dependent and memory speed (bandwidth, latency or both) dependent. Could it be sped up on a FPGA? @bobinson is showing 4-6 hour replays but is that not a full node?
Posted using Partiko iOS
So the hard drives couldn't handle the constant read/write? Were they solid state hds?
They were nvme drives which are 4x+ faster than ssd and raid 0 doubles that even more.
Hmmmmmmmmm .... lemme start googling the biggest memory sticks on the market ... it seems like hard drives wont' do the job ...
Perhaps it was a bad batch of drives? I need to look more into nvme vs regular ssd since I was unfamiliar with it ... It could also be that NVME is still not fully tested and breaks over time? Sometimes KISS (keep it simple stupid) is the best way to go. How critical is that 4x boost? I don't see a problem with latency going up per api call ... it's not like we're producing blocks which is a time sensitive issue.
NVME drives are SSD drives that are connected directly to the PCI-E bus and do no use SATA, they typically run 2,000-3,500 MB/s compared to 300-550MB/s for SATA based "SSD" drives.
Running isn't the problem, the problem is the replay times go from 1 day to weeks. Any patch, any outage, any short loss of power/Internet will force a replay which will take days/weeks to finish.
Once it is up, could run it on a SATA disk.
Depends if you want to be able to replay within 24 hours or 30 days. You either supply the ram, or you wait the time it takes to do a replay.
Gotcha ... yea that replay time is brutal ... hmmm ...
"Meditate on this, we will" ~ yoda
Also, I didn't know you were running a full-node (if you still are) ... that's something that needs more promotion if it's true. I may have to reconsider my witness votes if I can query it ...
I ran four full nodes for a year for buildteam. I just recently stopped and Drakos took over. The two Publics are decommissioned. Was considered by many as the fastest public nodes and I have helped others with theirs.
I have been planning a paid offering for a while and a unique spin on the whole node situation but costs are very high and you need redundancy if offering a paid service.
What I run now is not public.
Yep we're pretty dependent on steemit.api over at @steempeak but happy to switch to paid when it comes time and I'd personally love to see the system more decentralized which would make things less prone to total system failures based on one node.
This is indeed amazing summary @apshamilton
Thank you for taking the time and your effort. I really appreciate it a lot.
Yours
Piotr
Congrats on being appointed the position! Great information that demonstrates that supporting the ecosystem as a community is realistic. These are the times I wished I knew a little bit more about the technical aspects of doing this as I would love to support the infrastructure of the ecosystem!
Posted using Partiko iOS
Im entirely new but I believe in this system and offer whatever support I can even if its just a lowly upvote. If I had the money I'd personally fund you adequate server farms for the witnesses. Here's hoping. I imagine sooner rather than later Computers are gonna be adequate enough for steemit just by the fact, all we need is to hold out until then and then steemit gets huge like facebook Ideally but then not all going to one dude who looks like a picture of inbred royalty from the past XD Thank you for your contributions, I love learning about where this is all currently at, even at a laymen's understanding.
Like all other cryptos, STEEM has issues with scalability. Like you, Roger Ver of Bitcoin Cash feels that Moore's Law will deal with this problem, however Moore's Law appears to be dropping off its exponential growth.
Source
If anyone develops a system to run a steem node on a GPU mining rig I can throw some hardware at it.
i dunno anything about servers so i can't say much, but i was surprised by comments basically saying only steemit inc is capable of running it. i'm so happy you're part of this community and is actively looking for answers.
on a different note, i'd like to hear your opinions on this https://steemit.com/steemit/@steemitdev/upcoming-changes-to-api-steemit-com cuz i feel like steemit inc is about to cause even more confusion than it already has.
This change to using Hivemind for some of the non core APIs should reduce RAM requirements for full nodes and is thus a good thing.
Posted using Partiko iOS
thanks! 👍
That was very informative. Great new summary.
If you haven't seen it then check out @ura-soul's video response to the livestream. Sounds like you two are singing very much from the same song sheet on this.
As am I, but I'm a non techy!
Posted using Partiko Android
Peace, Abundance, and Liberty Network (PALnet) Discord Channel. It's a completely public and open space to all members of the Steemit community who voluntarily choose to be there.Congratulations! This post has been upvoted from the communal account, @minnowsupport, by apshamilton from the Minnow Support Project. It's a witness project run by aggroed, ausbitbank, teamsteem, someguy123, neoxian, followbtcnews, and netuoso. The goal is to help Steemit grow by supporting Minnows. Please find us at the
If you would like to delegate to the Minnow Support Project you can do so by clicking on the following links: 50SP, 100SP, 250SP, 500SP, 1000SP, 5000SP.
Be sure to leave at least 50SP undelegated on your account.
Steem onExcellent. Hope @ned reads about it and realize about how much power we have at the Steem community.
Posted using Partiko iOS
awesome post, new follower ... sounds like you know your sh$t
Decentralised systems do not need enterprise grade reliability at the individual node level, because decentralisation provides much higher reliability at the system level.
This is very valuable comment and i am sure with your financial background -u will be able to guide the community better to reduce cost without affecting service quality. All the best,
That was very informative
Thank you for this explanation. Not being a techie myself, I was hearing a lot of people saying that it didn't really matter, it was just the front end of steemit dot com that was in danger, and using a different front end like steempeak would be fine. That struck me as odd but I didn't know how the nodes worked until reading this and now I see that no, the dapps are indeed dependent on steemit inc. I hope they are successful in getting the properly decentralized nodes set up!
Could a solution like a Citrix Netscaler or F5 Load Balancer be centrally located somewhere and then have the different API requests punted to different HEDT systems?
Nice...hope u will like my work as well
https://steemit.com/@warsishah/
Congratulations @apshamilton! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board of Honor
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @steemitboard:
Today I wrote a post on what PIVX are doing to create "light nodes" that do not need the full blockchain.
Not a quick fix for Steem, but shows what can be done in the future.